
EDEN: corpus a gran escala de notas clínicas en italiano
EDEN: 4 millones de notas clínicas anonimizadas de urgencias italianas. Un dataset único para entrenar modelos de lenguaje en diagnóstico de disnea y pérdida de conciencia.
EDEN: 4 millones de notas clínicas anonimizadas de urgencias italianas. Un dataset único para entrenar modelos de lenguaje en diagnóstico de disnea y pérdida de conciencia.

Descubre cómo el benchmark SORB evalúa el impacto de la reducción de grafos en la maximización de influencia en redes multirelacionales. Resultados clave para IA y ciberseguridad.
Comparativa de arquitecturas flexibles para modelos multimodales geoespaciales. Analizamos trade-offs en flexibilidad, alineamiento y rendimiento en clasificación y segmentación.

¿Código generado por IA en tu repositorio? HybridCodeAuthorship es el benchmark definitivo para detectarlo. ¡Descubre cómo!

Descubre cómo Q2BSTUDIO automatiza tus flujos de trabajo con IA en Santa Cruz de Tenerife. Optimiza procesos, reduce costos y acelera tu transformación digital. ¡Contáctanos!

Servicios profesionales de automatización con IA en Santa Cruz de Tenerife. Mejora eficiencia y reduce costes. ¡Descubre cómo!

Partner oficial de automatización con IA en Tenerife con 15+ años de experiencia. Optimizamos procesos con n8n y modelos de lenguaje. ¡Contáctanos!

Descubre M*, el sistema de serving que reduce la latencia hasta un 20% en modelos multimodales, superando a vLLM-Omni. Ideal para arquitecturas compuestas de IA.
Descubre EWAM: adaptación en línea cero-shot que reduce datos de despliegue sin ajuste fino, usando capas ligeras para memoria, detección de anomalías y corrección.

Descubre cómo los modelos autorregresivos de dos capas estiman estados latentes imitando el filtrado de Kalman. Con resultados teóricos.

Descubre AfriSUD, la primera colección de treebanks sintácticos para 9 lenguas africanas. Evalúa modelos NLP y descubre la brecha sintáctica.

Descubre el MPC agentivo que integra LLMs para adaptar el control semántico en vehículos autónomos, respondiendo a normas sociales y preferencias del usuario.

Localización de circuitos de anclaje en modelos de lenguaje. Un estudio de Qwen y Llama revela cómo las señales de sesgo se transmiten internamente.
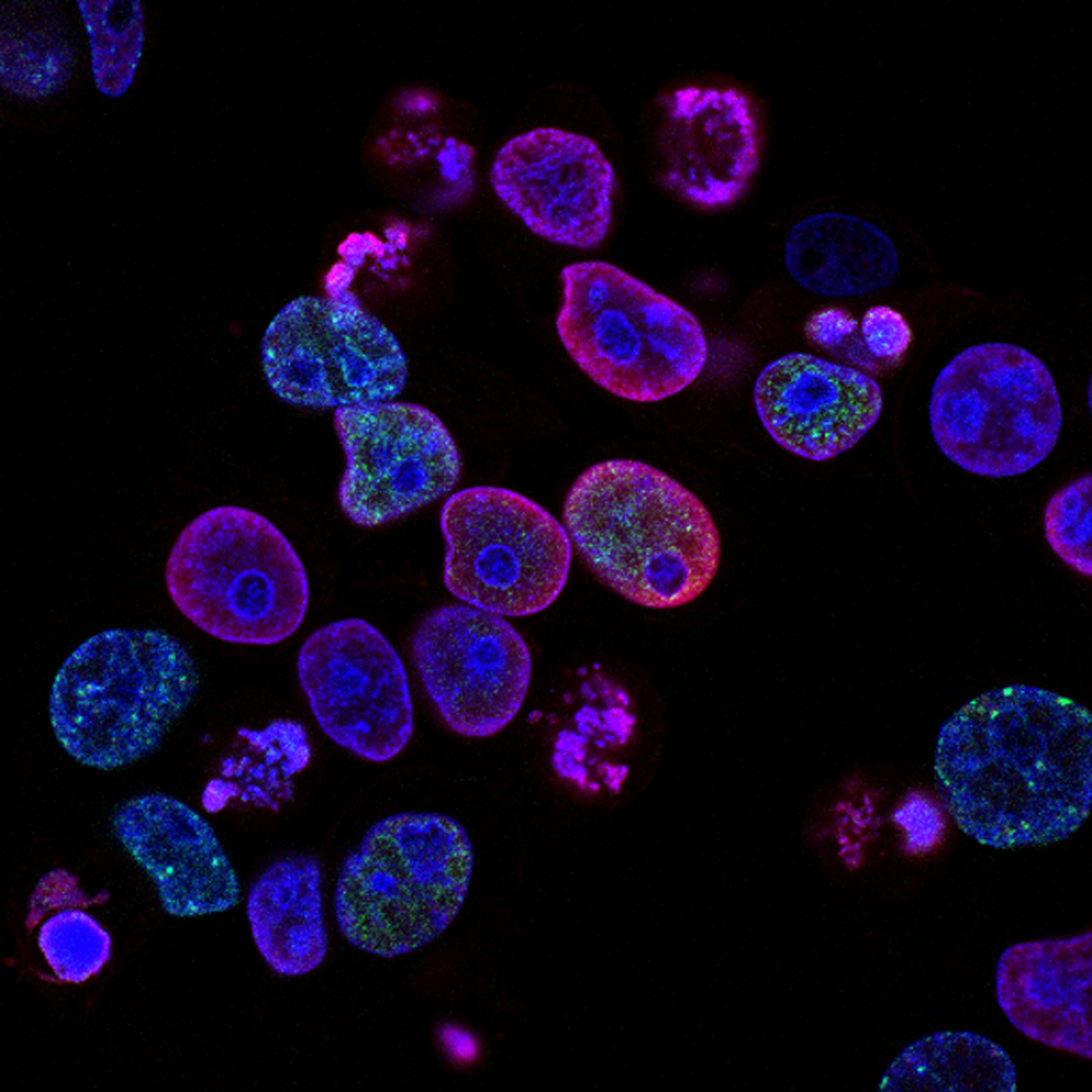
OCOO-T: modelo de célula virtual minimalista que predice respuestas transcripcionales a perturbaciones con alta precisión y escalabilidad.

TimeROME-DLM permite editar conocimiento en modelos de difusión enmascarados sin reentrenar. Rápido, sin VRAM extra, escala a 400 hechos. ¡Conócelo!

UOJ-Bench evalúa LLMs en programación competitiva: generación, hacking y reparación. En una prueba, fallan en detectar >50% errores; con escalado superan >90%.

Aislamiento modal en razonamiento intercalado reduce coherencia. MoTiF supervisa transiciones con refuerzo paso a paso para mejorar precisión en tareas.
GRASP combina visión-lenguaje y planificación neuro-simbólica para agarre robótico con lenguaje natural. 73.3% de éxito sin entrenamiento. ¡Descúbrelo!

Descubre por qué el orden no implica control en sistemas complejos: evidencia experimental en IA, biología y modelos de lenguaje que redefine la alineación.

Descubre cómo proteger tus modelos de difusión de imágenes con una nueva técnica de fingerprinting robusta contra ataques de colusión. Precisión superior al 99.5% y alta fidelidad.