
M³Eval: Evaluación de Memoria Multimodal con Tareas de Video Cognitivas
M³Eval: primer benchmark que evalúa la memoria en modelos multimodales con tareas de video cognitivas. Descubre sus debilidades.
M³Eval: primer benchmark que evalúa la memoria en modelos multimodales con tareas de video cognitivas. Descubre sus debilidades.

Conoce UniCAD, el benchmark que unifica tareas CAD multimodales, y su modelo UniCAD-MLLM con rendimiento superior en todas ellas.

Descubre BabyCL, un marco que procesa vídeos egocéntricos de niños para aprender palabras, reduciendo la brecha con offline. ¡Lee más!

Descubre Gemma 4 12B, el modelo de IA de Google DeepMind que procesa texto, imagen, audio y video sin codificadores externos. Funciona en laptops con 16 GB.

Gemma 4 12B de Google: modelo open source multimodal que corre local en laptops 16GB. Analiza audio, video y texto con 256K de contexto. Ideal para privacidad y edge.

Descubre cómo Gemma 4 12B revoluciona la IA local en dispositivos de consumo. Guía completa con arquitectura innovadora sin codificadores para desarrolladores.

ChatHealthAI integra registros médicos electrónicos con modelos de lenguaje para lograr razonamiento clínico interpretable y preciso. Descubre cómo.

Descubre cómo el marco CORE detecta manipulación multimodal y noticias falsas mediante razonamiento de conflictos. ¡Aprende más!

El marco PRPF optimiza la intervención de agentes móviles proactivos al percibir antes de razonar, reduciendo falsos positivos y mejorando la eficiencia. Descubre cómo.

CP-Agent: IA multimodal que interpreta morfología celular bajo fármacos, acelerando descubrimiento con reportes contextuales.

La entropía falla en RL visual: VEPO selecciona tokens visual-informativos y supera en hasta 3.15 puntos. Descubre cómo.

Los Tokens de Percepción Imaginativa (IPT) mejoran el razonamiento espacial en modelos multimodales sin generar imágenes. Aumento del 3.4% en precisión en conteo multivista.
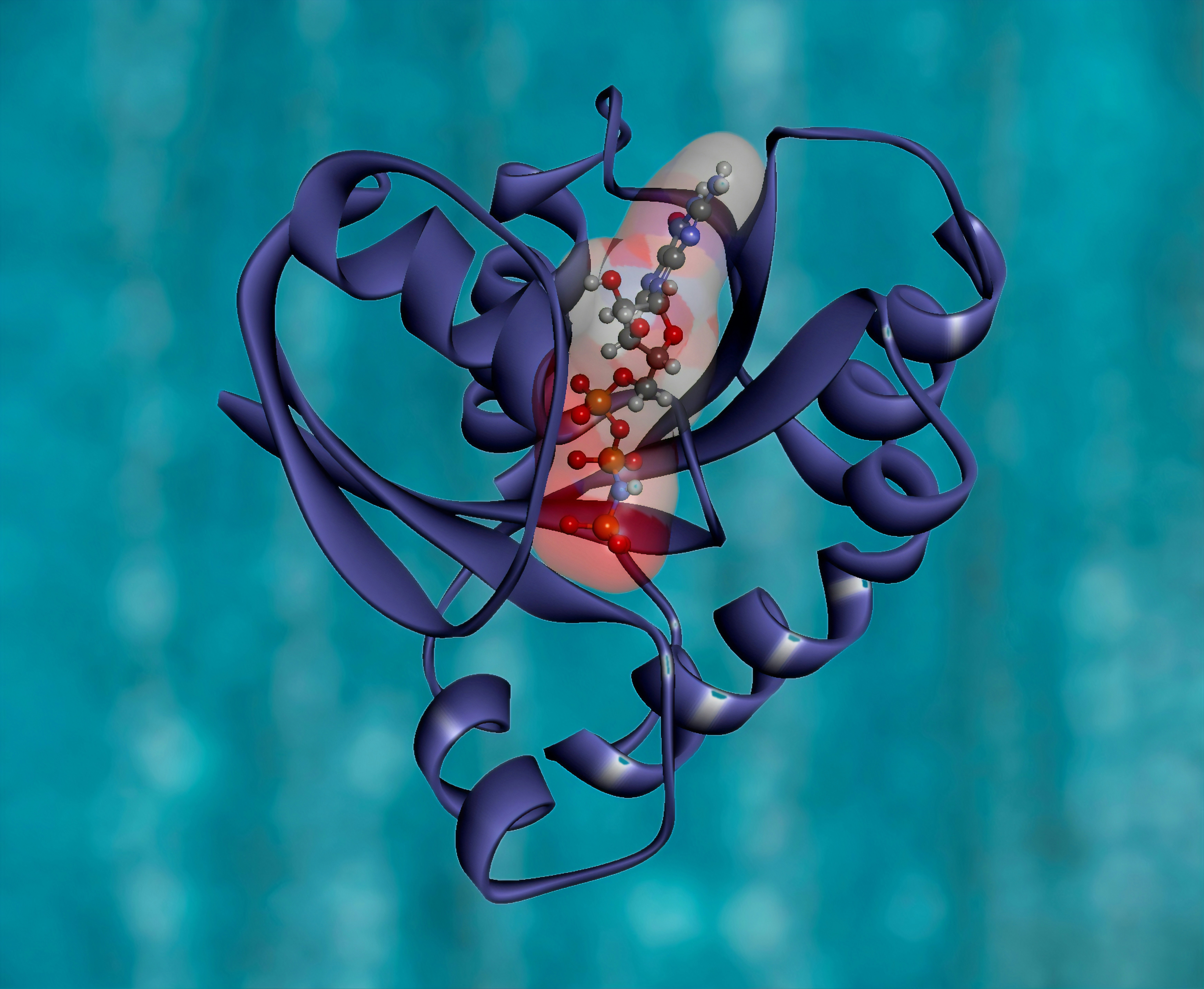
Aprende sobre MMM-PPI, un innovador modelo que integra secuencia, estructura y función para predecir interacciones proteína-proteína con precisión superior.

Descubre Social Caption: evaluando la comprensión social de modelos multimodales. Tres dimensiones clave: inferencia, análisis holístico y dirigido.

Nuevo modelo deep learning estima tiempo de dispersión de FRBs con 94% precisión, acelerando análisis astrofísico.

CR-Seg: segmentación razonada que combina atención y cadena de pensamiento para objetos complejos.

Descubre TurtleAI, el benchmark que evalúa modelos multimodales en programación visual con Turtle Graphics. Muestra fallos y cómo el ajuste fino mejora un 20%.

Descubre MemVerse, el marco de memoria multimodal que permite a los agentes de IA recordar, adaptarse y razonar sin olvido catastrófico. ¡Mejora el aprendizaje continuo!

MIND: nuevo marco de razonamiento activo para modelos multimodales. Emula el proceso humano entender-repensar-corregir. Logra SOTA.

Descubre EvoEnv, el nuevo benchmark que evalúa a los agentes IA en entornos laborales dinámicos: planificación, exploración y aprendizaje continuo.