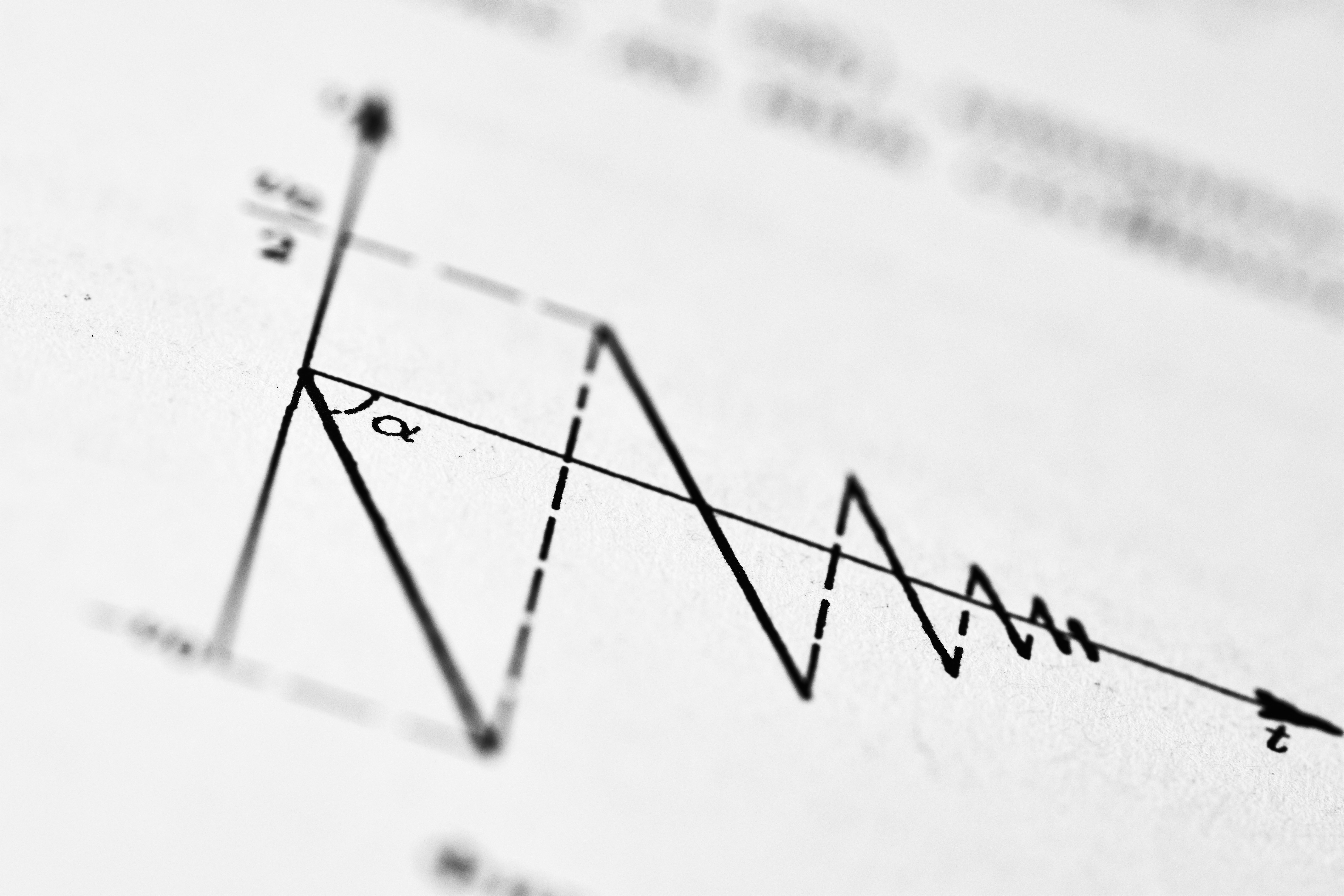
Sesgo tras sesgo: recompensa mecánica en modelos de lenguaje
Los modelos de recompensa en IA tienen sesgos. La recompensa mecánica los mitiga con pocos datos. Optimiza la alineación de modelos de lenguaje.
Los modelos de recompensa en IA tienen sesgos. La recompensa mecánica los mitiga con pocos datos. Optimiza la alineación de modelos de lenguaje.

Agente de RL optimiza señales de excitación para identificación de parámetros en sistemas mecatrónicos, superando métodos clásicos con solo 0.75% de violaciones

Aprende cómo los LLMs mejoran el diseño de recompensas en RL cooperativo multiagente, logrando mayor rendimiento en Overcooked.
EST-PRM pone a prueba la estabilidad de los modelos de recompensa de proceso ante transformaciones que distorsionan la calibración de recompensas.

Descubre cómo In2AI revolucionó el entrenamiento multi-agente con atribución retrasada de recompensa, logrando que un modelo de 8B superara a GPT-5 en MindGames Arena.

Descubre PaW: co-entrenamiento de políticas y modelado del mundo para agentes de lenguaje. Mejora el aprendizaje por refuerzo sin modificar la inferencia.

Descubre cómo un nuevo método de perturbación perceptual y modelado de recompensa corrige el sesgo en evaluaciones de LLMs multimodales. Más preciso y alineado con humanos.

Descubre cómo LEMAE usa LLMs para identificar estados clave y acelerar la exploración multiagente, con menos redundancia. Resultados superiores en SMAC y MPE.

CAST optimiza el RLVR con autoenseñanza no privilegiada y asignación de ventajas token en grupos de varianza cero. Mejora el razonamiento.
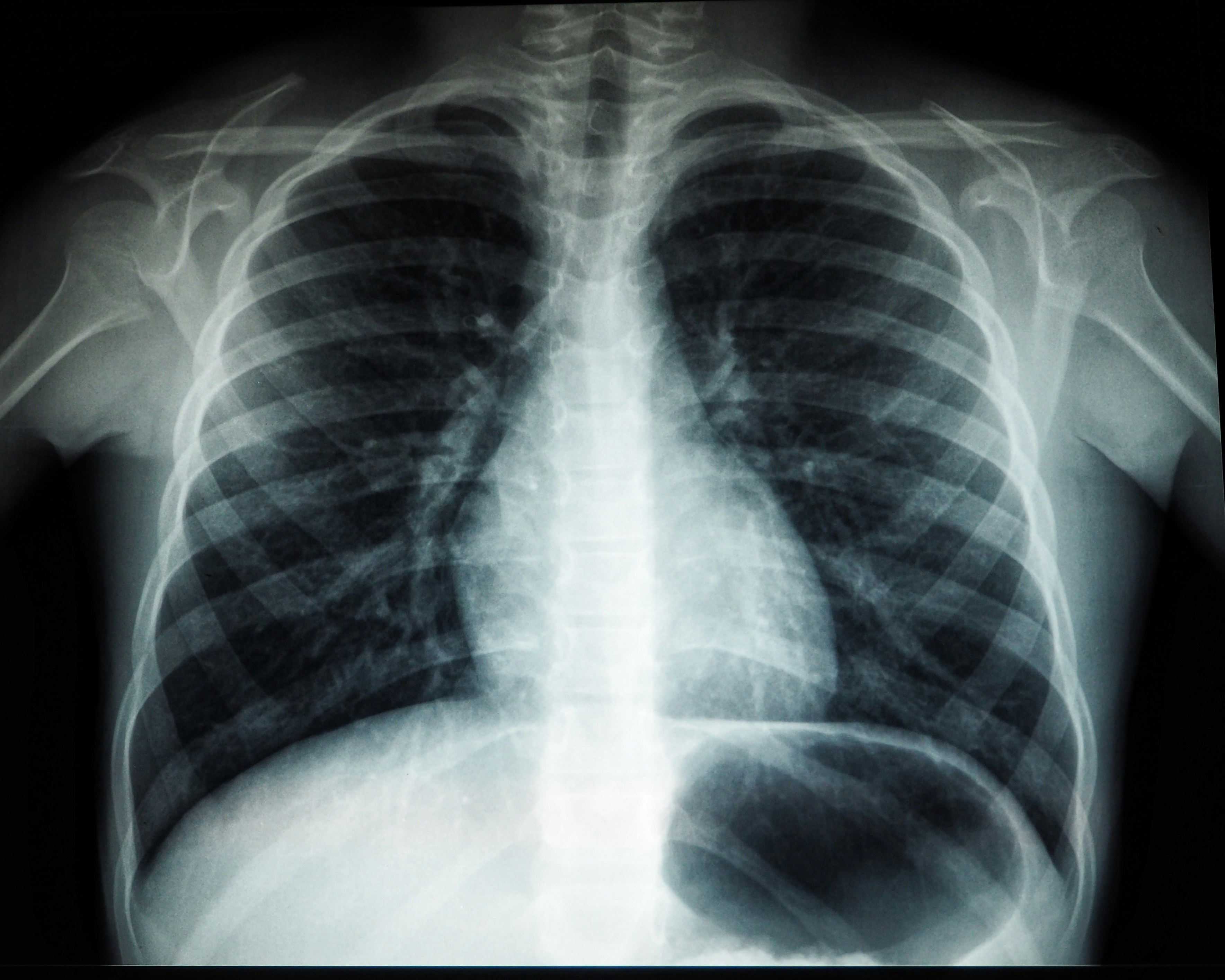
Mejora la generación automática de informes de rayos X de tórax con recompensas Set-Distance. Resultados: +6.8% BERTScore, +7.82% RadGraph, +4.45% CheXbert.

Descubre cómo Latent Reward Steering optimiza el razonamiento de LLMs al promover comportamientos cognitivos implícitos.
Descubre cómo el fuzzing de verificadores RLVR revela bugs antes de que el modelo los aprenda. Mejora la seguridad de tu IA con métricas clave.

EVA: nueva técnica de alineación de valor esperado que permite recompensas continuas en verificación formal de matemáticas con Lean 4. Mejora la evaluación de pasos intermedios.

Una IA menos competente puede aumentar tu satisfacción laboral. Estudio revela impacto en percepción propia y de colegas en el trabajo.

Optimiza el escalado de modelos dispersos con datos limitados. Descubre leyes de escalado, saturación retardada y compensaciones clave.

POPO elimina muestras ineficaces acelerando el fine-tuning de LLM para razonamiento matemático, planificación y geometría visual con menos rollouts.

Descubre cómo FedMChain optimiza el aprendizaje federado multimodal evitando la competencia entre modalidades y mejorando la precisión con menos comunicación.

La temperatura transforma la destilación de LLMs: a altas temperaturas, FKL supera a RKL. Aprende a optimizar la transferencia de conocimiento.
Descubre cómo HB-ARFM reconstruye campos de temperatura y velocidad en ebullición a partir de observaciones parciales, superando limitaciones Markovianas.

SPADER utiliza aprendizaje por refuerzo con recompensas de exploración diversa para mejorar el recuerdo y F1 en QA multi-respuesta.