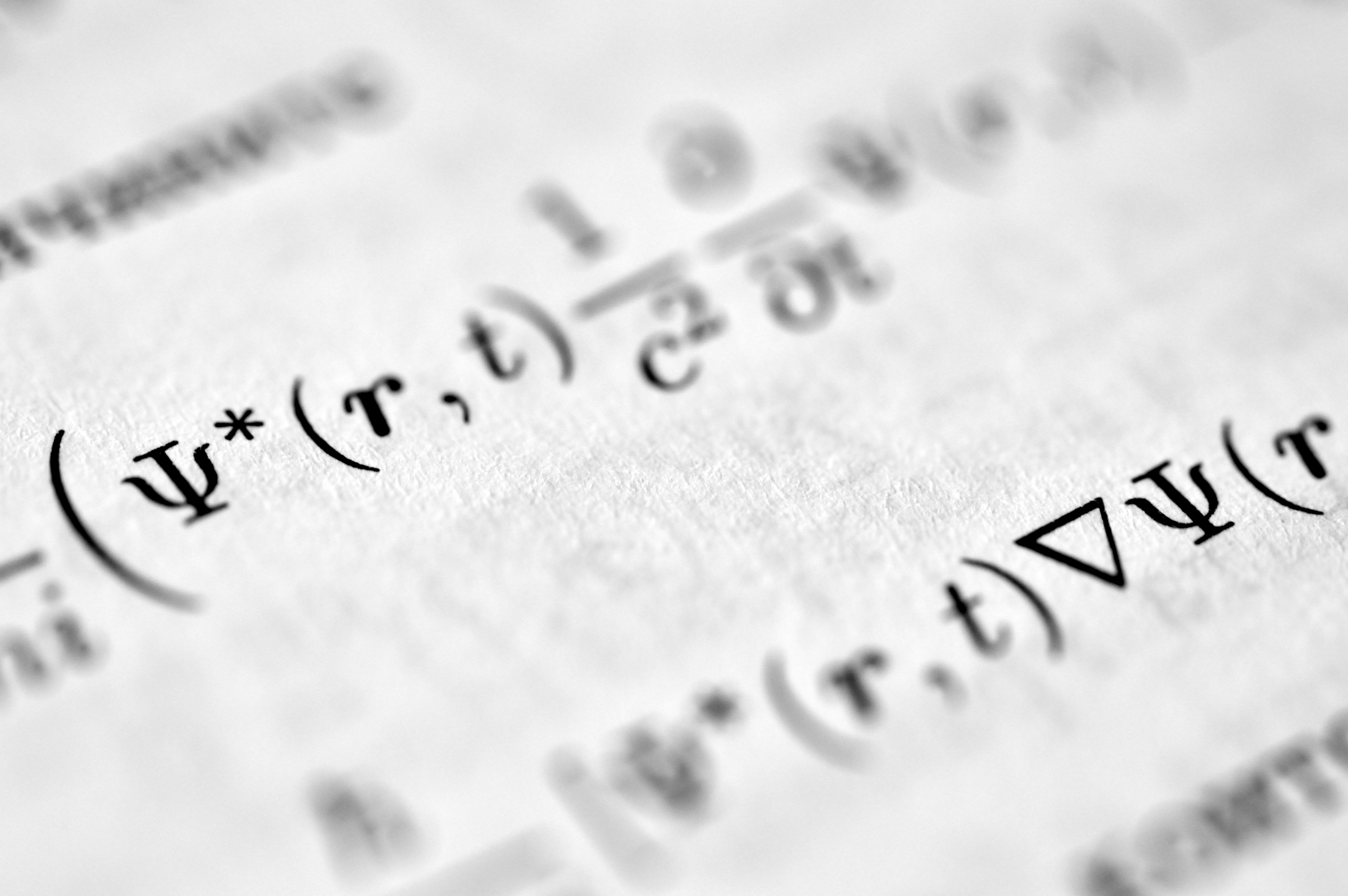
Alineación de Valor y Estructura para Cuantificación Consistente en Modelos MoE
Descubre cómo VSRAQ mantiene la selección de expertos estable al cuantificar modelos MoE, mejorando la calidad sin coste adicional en inferencia.
Descubre cómo VSRAQ mantiene la selección de expertos estable al cuantificar modelos MoE, mejorando la calidad sin coste adicional en inferencia.

Mejora el rendimiento de mezclas dispersas de expertos con enrutamiento Sinkhorn selectivo. Sin pérdidas auxiliares, mayor eficiencia y robustez.

Descubre cómo Selective Sinkhorn Routing optimiza modelos SMoE eliminando pérdidas auxiliares, mejorando eficiencia y precisión en lenguaje e imágenes.

Descubre SpanNorm, la innovadora técnica que equilibra estabilidad y rendimiento en Transformers profundos, superando las limitaciones de PreNorm y PostNorm.

¿Los patrones selectivos indican causalidad? Este estudio mecanicista entre modelos de 1B revela que no. Compara Pythia, OLMo y OLMoE en tareas compuestas.

Descubre cómo Fisher-MoE recorta dimensiones intermedias para comprimir modelos MoE al 50%, reduciendo memoria un 45% y acelerando inferencia un 21% sin perder capacidad.

Descubre Nemotron 3 Ultra de NVIDIA, un modelo MoE de 550B con arquitectura híbrida Mamba-Transformer. Ofrece hasta 6x más rendimiento, 1M de tokens de contexto
Descubre UltraEP, el primer balanceador de carga en tiempo real para MoE que logra un 94.3% del rendimiento ideal en entrenamiento e inferencia con 2560 GPUs.

Descubre cómo los modelos MoE pueden controlar el rechazo a peticiones dañinas. Estudio revela la efectividad de la redirección basada en un solo experto.

Descubre cómo LoopMoE integra computación iterativa con Mezcla de Expertos para superar a modelos tradicionales en benchmarks de lenguaje. ¡Mejora de rendimiento a escalas de 3B y 9B!

Descubre PTGAMoE: marco jerárquico para análisis de tráfico cifrado que preserva semántica y supera a SOTA.

Descubre CoRe-MoE, un marco de IA que permite a robots humanoides caminar y correr con fluidez en cualquier terreno. Resultados en simulación y robot real.

Descubre por qué descomposiciones tensoriales tienen limitaciones en la compresión de LLMs y cómo afectan a modelos densos y MoE. Análisis teórico y práctico.

Clasificación interpretable de series temporales con AnchorMoE: transparencia ante-hoc sin post-hoc. Ideal para diagnóstico clínico y detección de fallos.

Descubre cómo el rastreo causal consciente de expertos revela qué rutas en modelos MoE como Qwen3 y Mixtral recuperan hechos.
Skill-MoE mejora el razonamiento de modelos de lenguaje combinando expertos por habilidades. Logra hasta un 8% más de precisión en benchmarks con un solo GPU.

SafeMoE aprovecha conocimiento inseguro para respuestas seguras e informativas, superando en un 20% la tasa de seguridad. Un nuevo paradigma en alineamiento.

FilterMoE revoluciona las GNNs de prepropagación al enrutar filtros por nodos y canales, superando a métodos previos en 9 de 11 benchmarks. ¡Mejora precisión y escalabilidad!

Estudio revela cómo y cuándo se forman los circuitos de atención en modelos de lenguaje 1B. Descubre que inducción y atención-sumidero están separadas por orden de magnitud en tokens.

Predice la calidad de tus prompts con EMoE: incertidumbre sin entrenamiento en difusión texto-imagen.