
Colapso de flujo en hiperconexiones: diagnóstico y mitigación
Diagnóstico y mitigación del colapso de flujo en hiperconexiones de modelos Transformer. Aprende a romper la simetría y mejorar el rendimiento.
Diagnóstico y mitigación del colapso de flujo en hiperconexiones de modelos Transformer. Aprende a romper la simetría y mejorar el rendimiento.

Genera ejemplos sintéticos sin ejecución para mitigar alucinaciones en autocompletado. +18.8 EM en Delulu.

Descubre cómo los modelos frontera generan alucinaciones sintéticas como negativos duros para entrenar modelos de código y reducir alucinaciones +18.8%.

Descubre cómo evitar el sesgo sistémico en RL auto-recompensante y mejorar el rendimiento de LLMs con nuestro método RLER. ¡Lee aquí!

Descubre cómo ADPrompt adapta GNNs pre-entrenadas con un doble prompting que reduce sesgos de atributo y estructura, mejorando la equidad en clasificación de nodos.
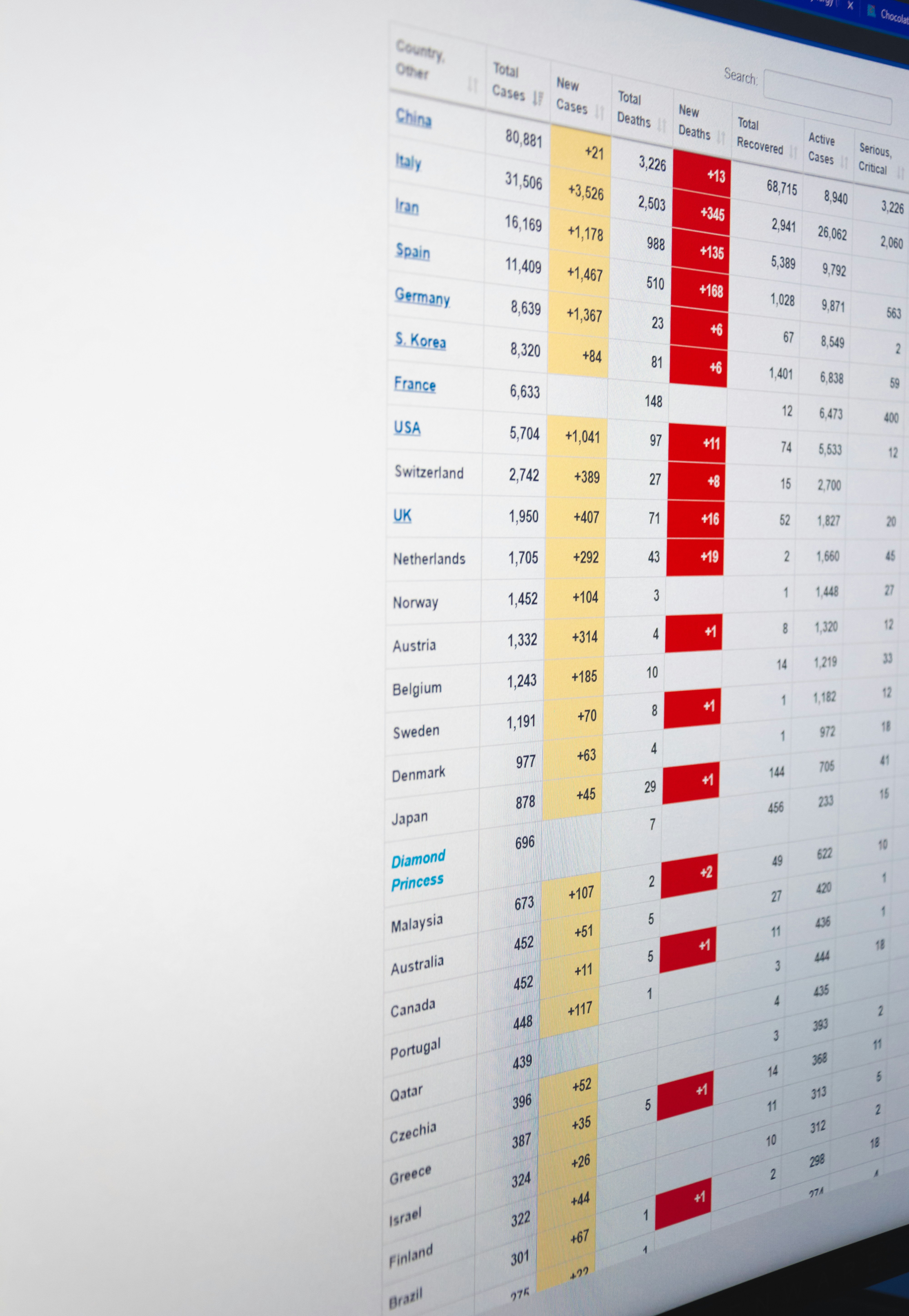
Descubre cómo una app personalizada puede reemplazar tus hojas de cálculo, automatizar procesos, centralizar datos y conectar con ERP y CRM para mejorar tu negocio.

Mitiga alucinaciones en LLMs con soft prompts: un método ligero que mejora la precisión y fomenta la abstención responsable. Ideal para aplicaciones críticas.

Descubre cómo el nuevo benchmark HarmAmp analiza la amplificación del daño en interacciones con LLM y cómo TrajSafe lo mitiga de forma proactiva.

Los agentes de IA con múltiples herramientas filtran datos sensibles en un 88.6% de los casos. Descubre el benchmark TOP-Bench y cómo mitigarlo con TOP-Align.

Descubre cómo combinar scores (perplejidad, contraste, verificación) con decodificadores para reducir alucinaciones en LLM sin supervisión. Resultados con Qwen3-1.7B.

Descubre SABER: refinamiento selectivo para transferencia positiva en aprendizaje continuo sin olvidar.

Descubre cómo la modernización de aplicaciones heredadas reduce costos, mejora la eficiencia y potencia la innovación. Q2BSTUDIO te ayuda.

GUARD: mitigación quirúrgica de memorización en difusión texto-imagen sin sacrificar calidad. Protege privacidad y evita infracciones de copyright.
EST-PRM pone a prueba la estabilidad de los modelos de recompensa de proceso ante transformaciones que distorsionan la calibración de recompensas.

Descubre cómo los errores suaves afectan la inferencia de LLM en HPC. Estudio sistemático con 17 hallazgos clave y estrategias de mitigación de bajo costo.

Aprende cómo las correlaciones espurias en VLM crean un espejismo de seguridad y cómo el desaprendizaje reduce ataques y rechazos innecesarios.

Aprende a evaluar y reducir el sesgo en el código generado por GPT-4o y Gemini. Analizamos métricas CBS, ACR y estrategias de mitigación para lograr equidad en IA.

DiscourseFlip: un ataque de manipulación de opinión a nivel de discurso en RAG que evade defensas actuales. Conoce sus implicaciones.

Descubre cómo lograr el clasificador justo óptimo en multiclase. Algoritmos de pre y post-procesamiento alcanzan la frontera Pareto entre precisión y equidad.

Descubre cómo EAPO mejora la precisión en modelos de IA reduciendo el abuso de herramientas. Aprende cuándo no actuar y optimiza el rendimiento.