
Brick: Enrutamiento por Capacidad Espacial para Mezcla-de-Modelos
Ahorra hasta 22x en costes cloud con Brick, el router multimodal que enruta cada consulta al modelo ideal. Precisión del 76.98%.
Ahorra hasta 22x en costes cloud con Brick, el router multimodal que enruta cada consulta al modelo ideal. Precisión del 76.98%.

CuMA alinea modelos de lenguaje a valores culturales usando mezcla de adaptadores, evitando el colapso medio y preservando la pluralidad cultural.

Clasificación estratificada interpretable con Árboles de Presupuesto Latente Simultáneo. Controla variables temporales, espaciales o demográficas.

Descubre cómo la mezcla rápida de Gibbs en variedades riemannianas logra tiempos polinomiales evitando barren plateaus y mínimos espurios.

Analizamos los tiempos de mezcla de Gibbs con aumento de datos en regresión probit de alta dimensión. Límites explícitos y cómo elegir prior que acelera la convergencia.

Descubre cómo BlendIn optimiza la alineación de LLMs en inferencia, combinando modelos de forma fiable para mejorar el rendimiento hasta un 50%. ¡Lee más!

Descubre cómo las Mezclas de Expertos (MoE) filtran el ruido en los datos, superando a redes densas en precisión y eficiencia. Resultados en tareas de lenguaje.

Descubre KLA: Atención Lineal de Kalman, un filtrado bayesiano paralelo que supera a Mamba y GLA en modelos de lenguaje.

Aprende cómo estimar gradientes de forma insesgada en cadenas de Markov, incluso con mezcla lenta. Perfecto para modelos con redes neuronales.
Descubre cómo el estimador de distancia mínima con Hellinger logra estimar densidades en tiempo casi lineal para mezclas gaussianas y log-cóncavas. ¡Lee más!

Descubre cómo el machine learning clusteriza exoplanetas cercanos y los vincula con la acreción de guijarros, revelando subpoblaciones y procesos de formación.

Descubre cómo MR-MoE acelera el entrenamiento de redes líquidas con expertos multitasa y atención para mejorar predicción de series temporales.

Descubre el innovador método MPI que alinea los enrutadores MoE con direcciones singulares para mejorar eficiencia y precisión.

Descubre N-GRPO, una nueva estrategia de exploración que mejora el razonamiento matemático de LLMs mediante la mezcla inteligente de embeddings semánticos. Resultados consistentes en benchmarks.

Descubre cómo N-GRPO revoluciona la exploración en modelos de lenguaje, generando trayectorias diversas sin perder coherencia semántica. Mejora el razonamiento matemático en LLMs.

Flash-GMM: clustering GMM en GPU 20x más rápido. Procesa datasets 100x mayores. Mejora búsqueda ANN. ¡Descúbrelo!

Descubre cómo las Mezclas de Operadores Neuronales reducen la complejidad activa en el aprendizaje de operadores, mejorando la eficiencia computacional.

TENP: poda trapezoidal de neuronas para MoE. Reduce parámetros activos un 63% con solo 1 punto de pérdida de precisión. ¡Mejora código un 10%!

Descubre cómo un nuevo análisis de convergencia revela el verdadero impacto de la topología de red en el rendimiento del SGD descentralizado. Te sorprenderá.
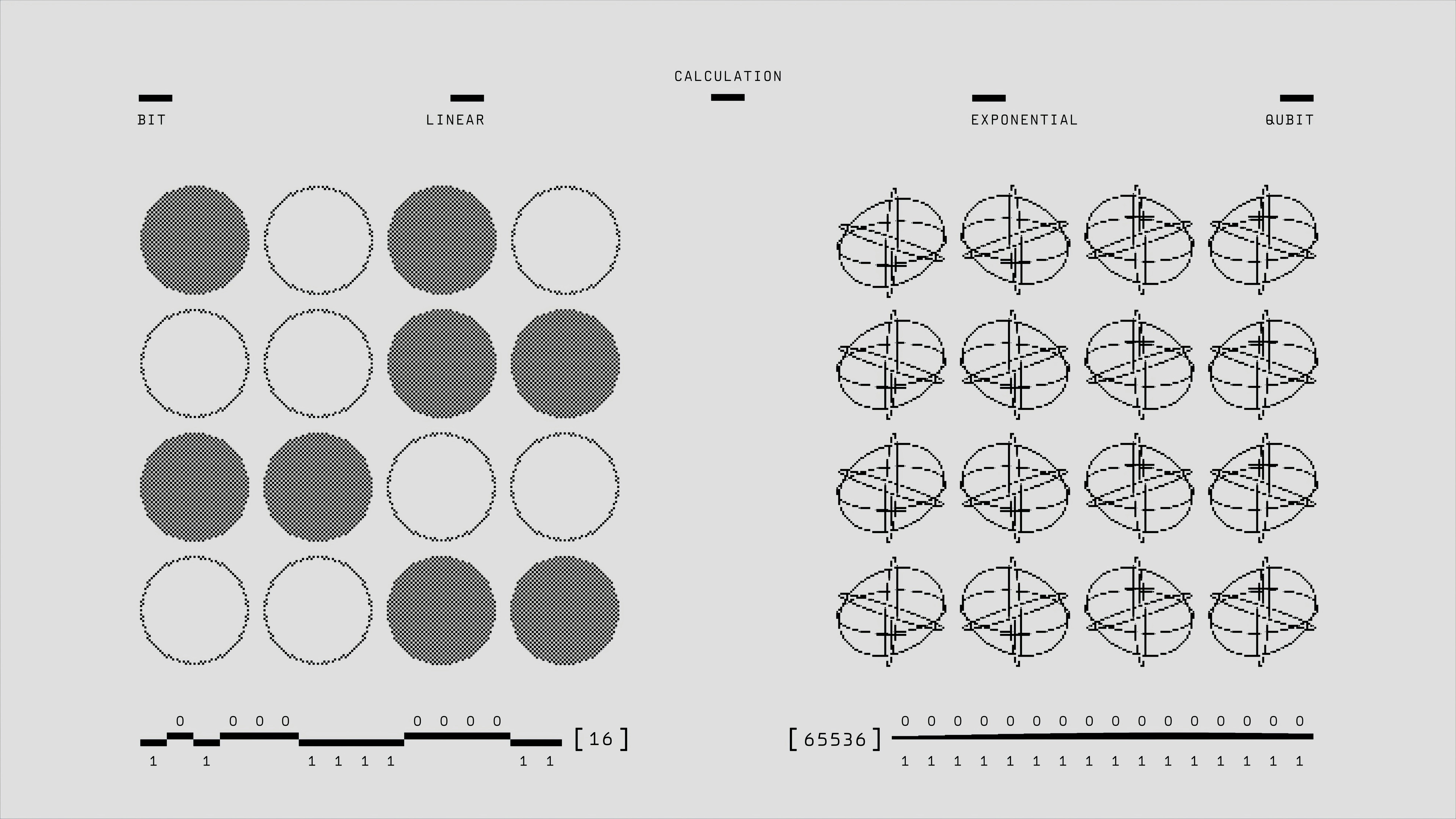
Descubre cuándo los modelos de score locales extrapolan correctamente a sistemas más grandes. Teoría, diagnóstico y benchmark FDLF para estabilidad en generación científica.