
Los primeros portátiles Nvidia RTX Spark ya tienen nombre
Descubre los primeros portátiles con Nvidia RTX Spark. Microsoft, Asus, HP y más lanzarán modelos con chip ARM de 20 núcleos y 6,144 GPU. Conoce todos los detalles.
Descubre los primeros portátiles con Nvidia RTX Spark. Microsoft, Asus, HP y más lanzarán modelos con chip ARM de 20 núcleos y 6,144 GPU. Conoce todos los detalles.

Descubre LiMuon, el optimizador ligero y rápido que reduce memoria y complejidad muestral para entrenar modelos grandes. ¡Mejor rendimiento!

Descubre cómo ZO-Finetuner optimiza el ajuste de LLMs sin retropropagación, reduciendo el uso de memoria y mejorando el rendimiento en múltiples tareas.

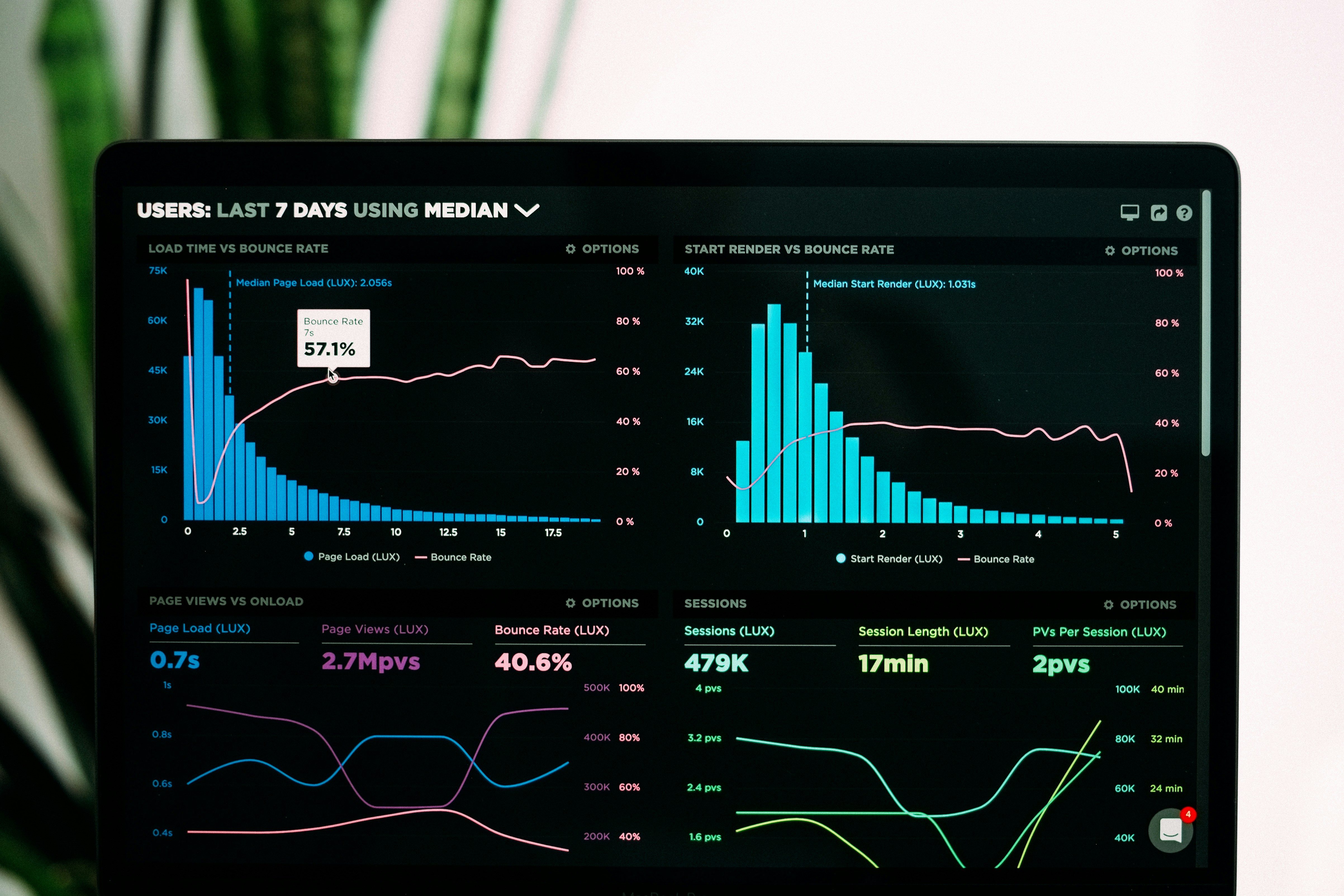
La escasez de chips de memoria dispara los precios de portátiles y PCs de sobremesa en Europa. Descubre cómo la demanda de IA impacta en tu bolsillo.

Descubre el gap de inferencia en IA física: memoria limitada pero no ancho de banda. CUDA Graphs muestra un overhead oculto en GPUs rápidas como H100.

Descubre SAGE, el innovador gate que optimiza la memoria de LLMs agenticos: reduce costos de API 3.4x y latencia 2.5x manteniendo calidad.
Genera informes patológicos sinópticos con un modelo eficiente que solo requiere media GPU H100. Resultados precisos.

Descubre cómo optimizar GNNs con capas conscientes de E/S. Logra hasta 8.5x de aceleración y reduce la memoria hasta 76x. Implementaciones drop-in.
Descubre las Redes Residuales de Memoria de Reservorio (ResRMN), una nueva clase de RNN no entrenadas que mejoran la propagación temporal mediante conexiones residuales ortogonales.

Descubre cómo ForecastCompass (FoCo) mejora la predicción agéntica usando memoria de factores adaptativa, aumentando precisión y calibración en entornos dinámicos.

Mejora el rendimiento de modelos 3DGS con compresión basada en diccionarios: reduce memoria y acelera el renderizado.

Descubre cómo las capas probabilísticas bayesianas mejoran la memoria en modelos de secuencias, reduciendo incertidumbre y aumentando robustez más allá del entrenamiento.

Descubre OBCache, la técnica de poda de caché KV que optimiza la memoria en LLMs para inferencia en contextos largos sin sacrificar precisión.
Descubre cómo los modelos de mundo equivariantes con memoria latente mejoran predicción en entornos parcialmente observados con simetrías temporales.

Descubre por qué los modelos de difusión tienden a memorizar ejemplos comunes y generan contenido mediocre, y cómo la diversidad de datos puede evitarlo.
Comparativa de memoria: Chain-of-Thought vs Transformers en bucle comprimido. Los bucles no pueden igualar el razonamiento con scratchpad. ¡Descubre por qué!

Descubre TARIC, navegación exterior VLN que supera interrupciones semánticas con memoria 3D y transitabilidad. Mejora tasa de éxito real al 40% vs 17.5%.

Descubre por qué la memoria recurrente lineal es efectiva en RL parcialmente observable. Justificación teórica con filtros lineales y HMM.

Aprende a usar Node.js Streams para procesar archivos enormes sin colapsar la memoria. Guía completa con ejemplos prácticos.

Descubre cómo los streams en Node.js te permiten procesar gigabytes de datos sin colapsar la memoria. Guía completa con ejemplos prácticos.