
PersistBench: ¿Cuándo olvidar las memorias a largo plazo en LLMs?
PersistBench expone graves riesgos de seguridad en la memoria a largo plazo de LLMs: fuga de datos y sesgos. Conoce los resultados y soluciones.
PersistBench expone graves riesgos de seguridad en la memoria a largo plazo de LLMs: fuga de datos y sesgos. Conoce los resultados y soluciones.

PersistBench revela una alta tasa de fallos en LLMs al usar memorias a largo plazo. Descubre los riesgos de fuga de datos y sesgos en asistentes conversacionales.

Descubre cómo el modelo VLM consciente de creencias combina memoria y RL para un razonamiento similar al humano. Mejora en QA visual con HD-EPIC. ¡Lee más!

Descubre cómo un modelo VLM consciente de creencias integra memoria y aprendizaje por refuerzo para un razonamiento similar al humano, mejorando tareas de VQA.

Descubre MesaNet, un modelo recurrente que optimiza capa por capa en inferencia. Mejora rendimiento en contextos largos sin aumento lineal de memoria.

Descubre cómo la topología de red influye en las fugas de memoria en sistemas multiagente de LLM y obtén recomendaciones para un diseño seguro.

Descubre PERSIST: modelo de mundo con escenas 3D latentes que genera mundos coherentes con memoria espacial persistente y control geométrico.

Aprende cómo Cartridges a Escala elimina el prefilling en LLMs, mejora la precisión y reduce tokens. Descubre el entrenamiento de cachés KV modulares sobre millones de documentos.

Descubre los Kernel Neural Operators (KNO): aprendizaje de operadores escalable, eficiente en memoria y flexible en geometrías irregulares.

Descubre cómo las RNN asimétricas modelan dinámicas complejas con drift-diffusion matching, aplicado a memorias asociativas y episódicas.

Descubre cómo fusionar BM25 con búsqueda densa late-interaction sin entrenamiento mejora hasta +17.2 puntos la recuperación de memoria en conversaciones largas. Estudio detallado.

EMTC mejora la consistencia temporal en memoria episódica para MARL cooperativo, superando cuellos de botella y logrando hasta un 28% de mejora en benchmarks.
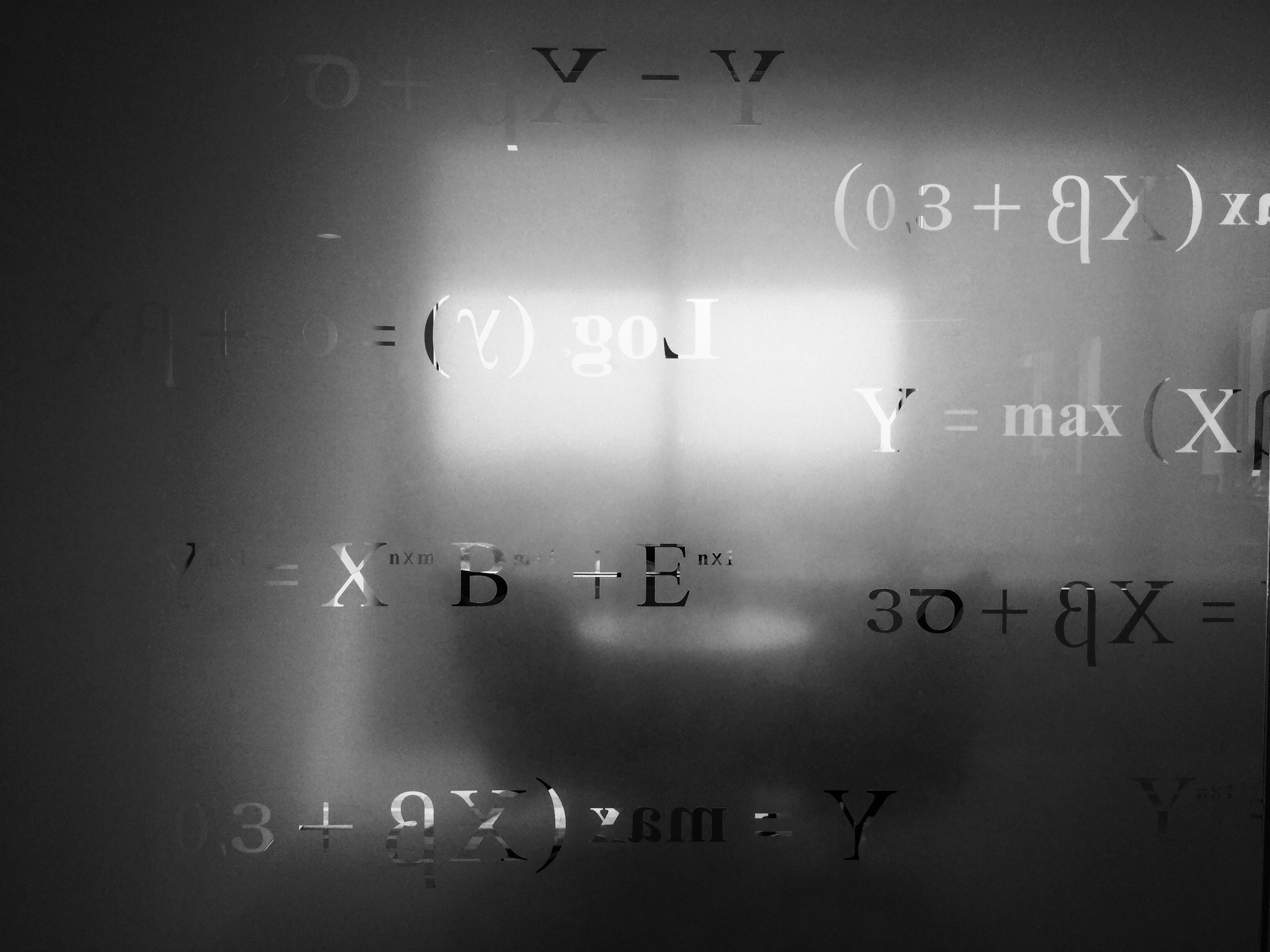
STaR-Quant mejora la cuantificación de baja precisión en DLLMs, logrando 1.69x aceleración y 3.14x ahorro de memoria sobre FP16. Descubre cómo optimizar tu modelo.

Descubre AlphaQ, un método sin calibración que asigna bits a expertos en MoE basado en la pesadez espectral. Logra compresión 4x con precisión casi total.

Descubre MemoryDocDataSet: un benchmark que desafía a la IA a combinar memoria conversacional y razonamiento en documentos largos. ¿Tu modelo supera la brecha?

RowNet es un transformer de memoria que mejora la valoración inmobiliaria al recuperar propiedades comparables. Descubre su arquitectura.

Descubre cómo SegTreeMem mejora agentes conversacionales de largo plazo al preservar el orden temporal con árboles de segmentos.

Descubre cómo el rastreo de evidencia y procedencia permiten verificar, depurar y auditar agentes LLM para mayor confianza.

M³Eval: primer benchmark que evalúa la memoria en modelos multimodales con tareas de video cognitivas. Descubre sus debilidades.

¿Error java.lang.OutOfMemoryError? Aprende cómo solucionar el límite de overhead del GC ajustando el heap y usando profiling. Guía paso a paso.