
Pensamiento Especulativo: grandes modelos mejoran el razonamiento
Mejora la precisión de modelos pequeños hasta un 6.2% usando guía de modelos grandes sin entrenamiento. Descubre Speculative Thinking.
Mejora la precisión de modelos pequeños hasta un 6.2% usando guía de modelos grandes sin entrenamiento. Descubre Speculative Thinking.

Los Anclajes de Relleno Dinámico (DIA) optimizan la generación con formato restringido, logrando avances zero-shot en GSM8K y MATH.
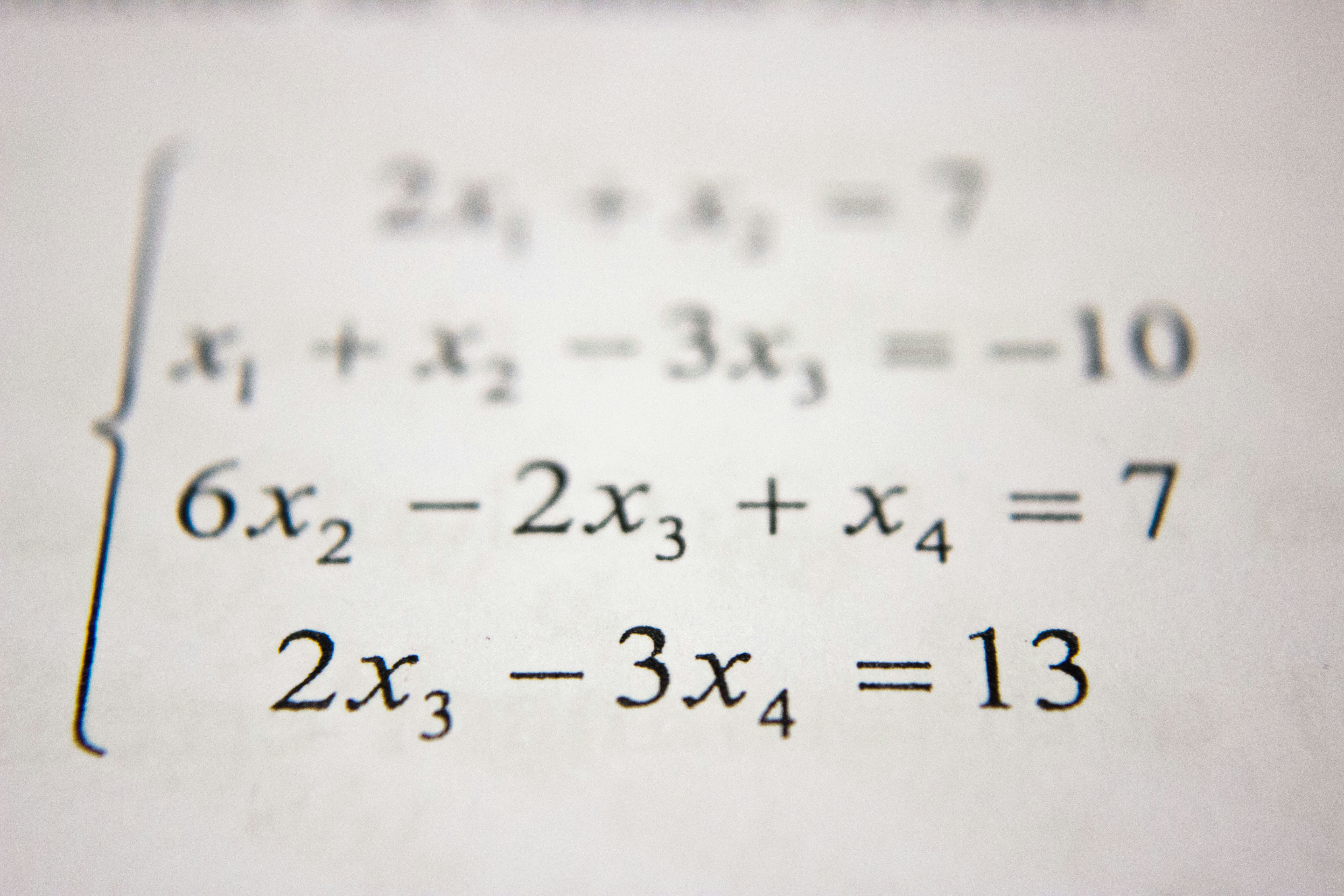
Descubre PyraMathBench: evalúa y mejora la capacidad matemática de los LLMs con 32,505 preguntas y técnicas como SOLVE e IRPO.

Aprende cómo T1 permite a modelos pequeños de IA verificar respuestas con herramientas externas, logrando rendimiento superior a modelos 8 veces mayores.

EST-PRM pone a prueba la estabilidad de los modelos de recompensa de proceso ante transformaciones que distorsionan la calibración de recompensas.

Descubre cómo la inferencia 2-bit en modelos de razonamiento genera fallos como bucles y cómo la planificación y rescate recuperan precisión hasta 87%.

Descubre Hermes: agente que combina razonamiento informal y verificación formal en Lean para mejorar precisión matemática en LLMs un 40% con 80% menos coste.

Math.random() no es seguro para claves API. Error en un repo de 44K estrellas. Descubre por qué es peligroso y cómo evitarlo.