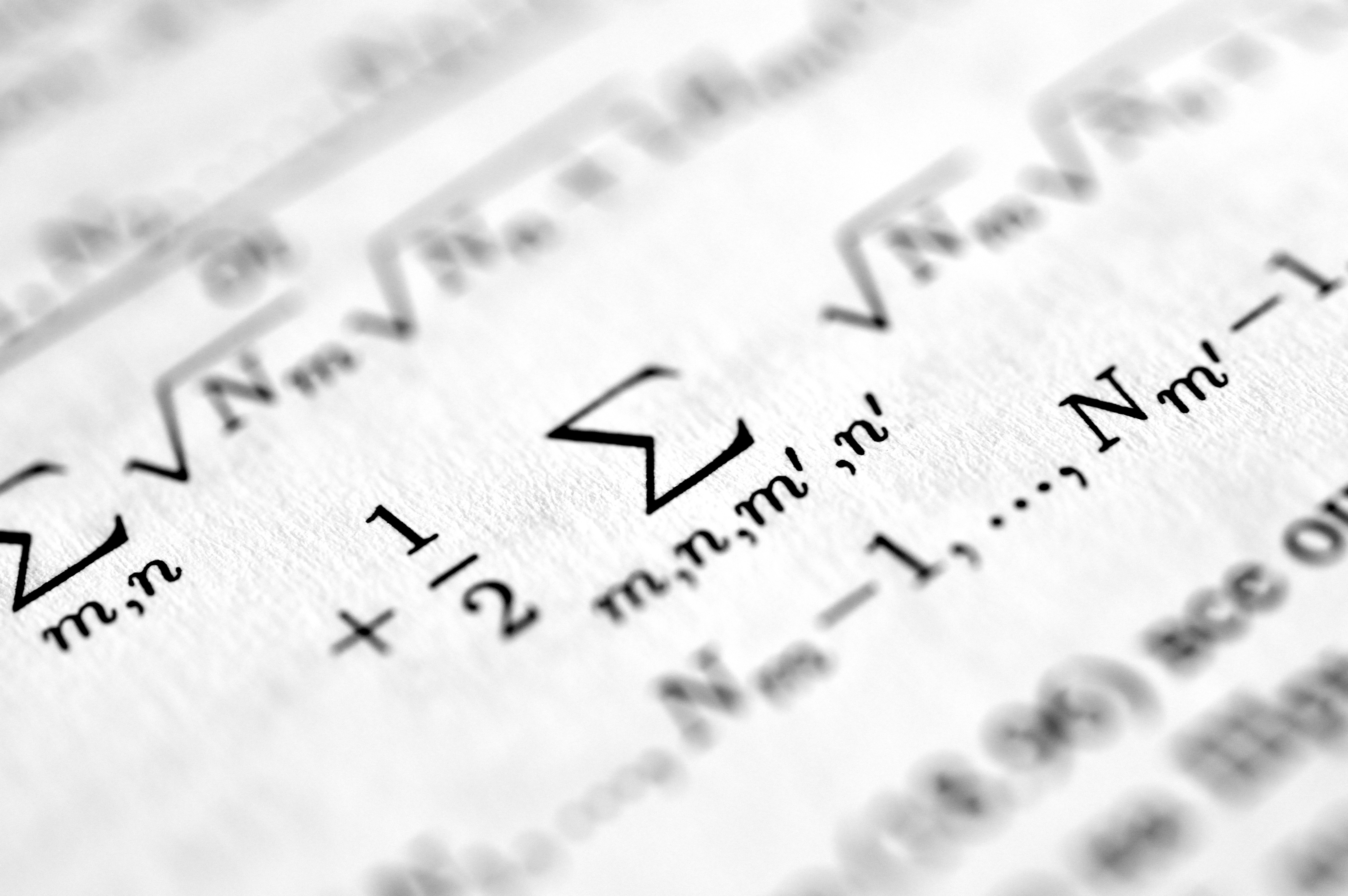
MCMC sin evaluar el objetivo: enfoque de variable auxiliar
Descubre cómo un nuevo marco unifica y mejora algoritmos MCMC usando variables auxiliares, sin necesidad de evaluar la distribución objetivo. Mejor rendimiento en datos sintéticos y reales.
Descubre cómo un nuevo marco unifica y mejora algoritmos MCMC usando variables auxiliares, sin necesidad de evaluar la distribución objetivo. Mejor rendimiento en datos sintéticos y reales.
Descubre cómo la iteración de políticas alcanza tiempo polinomial fuerte para MDPs robustos con conjuntos L∞. Un avance clave en optimización secuencial.

Descubre un método asintóticamente óptimo para pruebas secuenciales en cadenas de Markov. Mejora límites inferiores y aplicaciones en MCMC y MDPs.
Modelos de Markov neuronales inspeccionables mejoran predicción de series no estacionarias. Reducción del 5.6% en discrepancia. ¡Descubre cómo!

Descubre los nuevos límites de convergencia no asintóticos para Engression y Reverse Markov Engression. Resultados casi óptimos para aprendizaje de distribuciones condicionales con redes profundas.
Descubre cómo identificar regímenes latentes y estructuras causales en series temporales no estacionarias con modelos de Markov y efectos instantáneos.

Descubre un enfoque directo para manejar bandidos contextuales con estados latentes. Aprende cómo reducir el problema a bandidos lineales y mejorar las decisiones en entornos inciertos.
Un nuevo marco de RL continuo seguro optimiza el momento de las interacciones clínicas y garantiza seguridad en toda la trayectoria. ¡Lee el artículo!
Certificación no vacía de MCMC de transporte: nuevos límites de brecha espectral con flujos normalizadores. Ideal para muestreo bayesiano.

¿Cómo se relacionan las leyes de escalado con las representaciones internas en deep learning? Este estudio revela una correlación entre rendimiento y estructura

Aprende a estimar núcleos de Markov válidos con un gráfico contrastivo anclado en Doeblin. Mejora la precisión en dinámicas de cadena.

Algoritmo optimista logra arrepentimiento minimax-óptimo en POMG. Complejidad O(√T) con dependencia de la dimensión de Eluder.

Descubre el blindaje robusto para RL seguro. Garantiza seguridad en MDPs con transiciones inciertas mediante lógica temporal. Ideal para alta incertidumbre.

Descubre cómo la optimalidad de Bellman en MDPs con estados catastróficos produce aversión a pérdidas y efecto reflejo, sin preferencias de riesgo.

Aprende cómo PatenteXAI aplica Shapley jerárquico y grafos de conocimiento para valorar patentes de forma eficiente, con resultados precisos en milisegundos. Optimiza tu portafolio.

Descubre I-PERI, un algoritmo federado que recupera estructuras causales a partir de datos heterogéneos con intervenciones desconocidas, mejorando privacidad y precisión.

Analizamos los desafíos del RL en sistemas energéticos reales: observabilidad, diseño de acciones, recompensa y la brecha simulación-realidad.

Descubre cómo se demuestra la convergencia de algoritmos bi-escala bajo ruido markoviano, un avance clave para el aprendizaje por refuerzo off-policy.
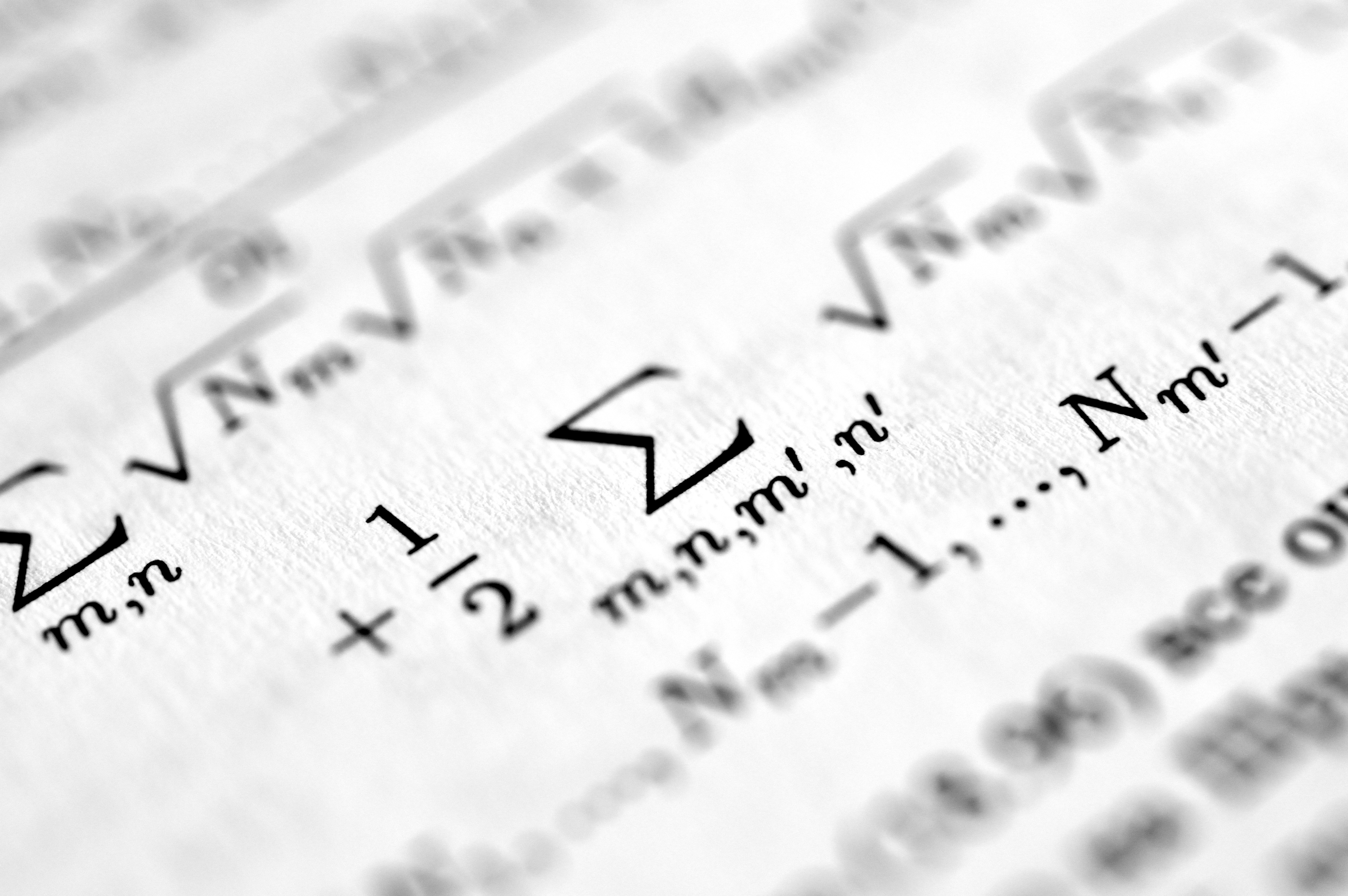
Descubre cómo las funciones de Lyapunov permiten analizar la convergencia finita de algoritmos estocásticos en aprendizaje automático y refuerzo.

Descubre cómo la caminata verdadera auto-evitativa reduce el error de estimación integral en MCMC de t^-1/2 a O(√log t/t), acelerando la convergencia.