
Modelo de cribado con equilibrio acotado en decisiones multi-atributo
Descubre un modelo computacional que explica cómo las personas descartan opciones con mal rendimiento en atributos críticos, mediante un equilibrio acotado.
Descubre un modelo computacional que explica cómo las personas descartan opciones con mal rendimiento en atributos críticos, mediante un equilibrio acotado.

Descubre cómo un sistema RAG híbrido multi-campo analiza 13k informes de accidentes marítimos (1971-2025) para determinar causas raíz y agilizar investigaciones.

Descubre cómo ProFact usa aprendizaje por refuerzo agéntico para optimizar la verificación de hechos en múltiples etapas, mejorando precisión y eficiencia.

Descubre WildIFEval: 7,000 instrucciones reales con múltiples restricciones. ¿Cómo siguen las instrucciones los LLMs? Benchmark y análisis detallado.
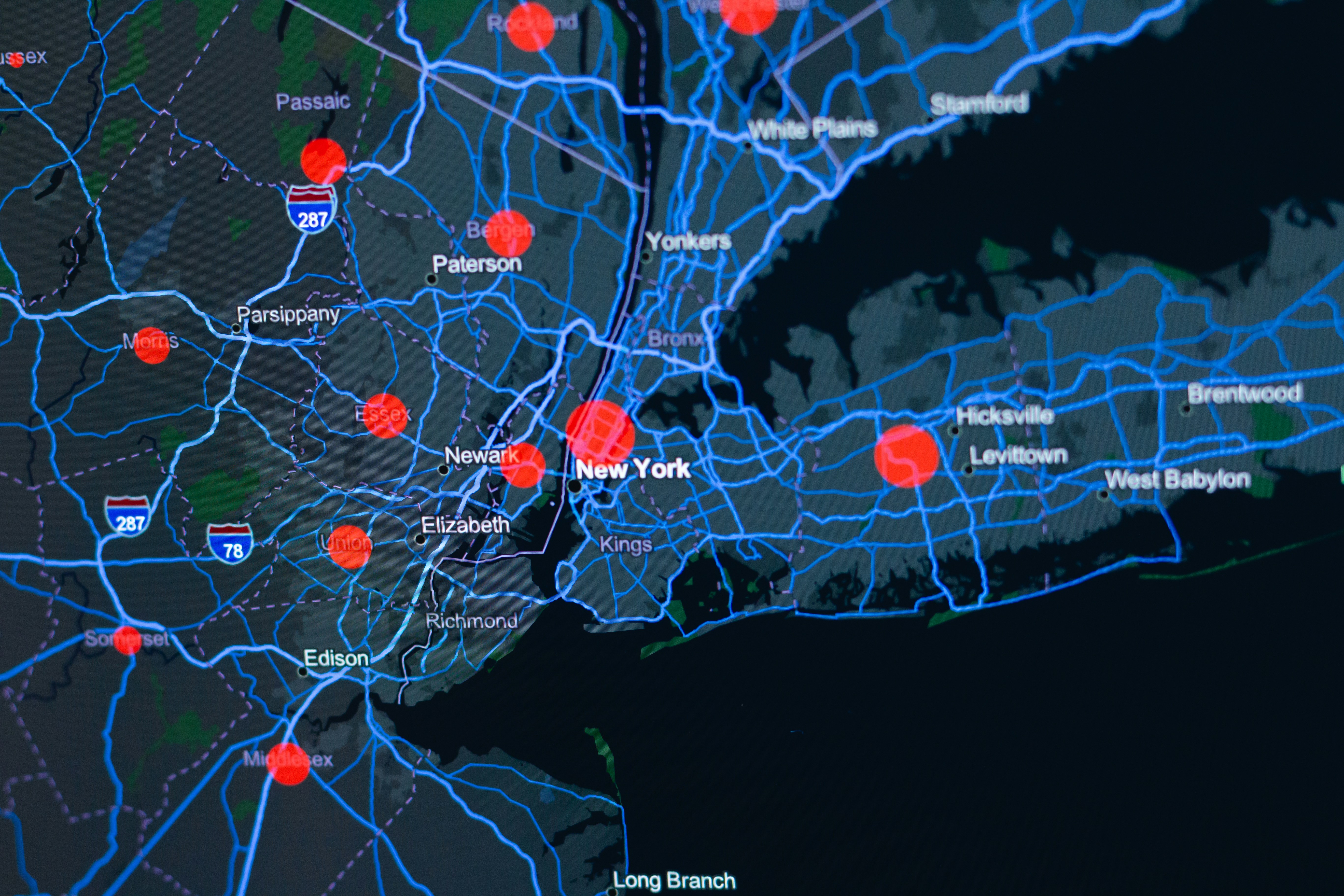
Descubre PlaceRep, un método que aprende representaciones de lugares a partir de puntos de interés, superando límites administrativos y mejorando predicciones urbanas.

Redes FMMNN: precisión excepcional en funciones oscilatorias con activaciones seno y estructura multicomponente. Inicialización escalada acelera entrenamiento.

Descubre por qué los ataques de envenenamiento de corpus fallan en sistemas RAG reales con chunking y reranking. Conoce CRCP, un nuevo enfoque para ataques robustos. ¡Lee más!

Descubre abstracción PyTorch para reconstrucción neuronal de escenas a gran escala usando múltiples GPUs, logrando más de mil millones de splats Gaussianos.

Exploración paralela por dominio en agentes LLM supera a la lineal en localización de cambios multiarchivo. Resultados en SWE-bench.

Descubre cómo reciclar consultas de varianza cero en entrenamiento mejora eficiencia y rendimiento de búsqueda agéntica, logrando resultados sobresalientes.

Explora cómo los modelos de visión-lenguaje componen y cambian personalidades múltiples dinámicamente, afectando el razonamiento y la descripción de imágenes.

T1-Bench revoluciona la evaluación de agentes con escenarios intercalados y 25 dominios. ¿Tu modelo supera la prueba? Conoce los resultados.

Descubre EEVEE, marco de aprendizaje de prompts en tiempo de prueba para agentes LLM que maneja múltiples datasets y mejora el rendimiento hasta un 48%

Descubre cómo el aprendizaje profundo permite obtener certificados de ingresos en subastas óptimas de múltiples artículos y postores. Un avance clave en diseño de subastas.
Descubre cómo el franchising multiubicación impulsa el crecimiento, reduce costos y fortalece tu marca en el retail. Estrategias clave para el éxito.

Mejora la predicción de fuerzas moleculares con refinamiento de escala adaptativo guiado por pérdida. Reduce errores en sistemas iónicos acuosos. Avance en IA.

RepoLaunch automatiza la construcción y pruebas de repositorios multi-lenguaje y plataforma, con 78% de éxito. Ideal para datasets de SWE.

Descubre cómo las leyes de escalado explican la mezcla de datos en IA. Aprende sobre competencia de capacidad y reducción de ruido para optimizar modelos.

Descubre cómo el Tarot y el I-Ching alteran el comportamiento de los LLM en juegos multiagente, generando ganadores distintos y revelando el poder del proceso reflexivo.

Aprende cómo la minería de procesos y automatización facilitan la colaboración multiusuario con roles, comentarios y versionado. Q2BSTUDIO optimiza tus flujos.