
Soberanía de Evaluación en Clasificación Basada en Metadatos
La soberanía de evaluación revela que métricas de clasificación pueden estar infladas. Marco multi-track para auditar sistemas de IA.
La soberanía de evaluación revela que métricas de clasificación pueden estar infladas. Marco multi-track para auditar sistemas de IA.
La soberanía evaluativa revela si los modelos realmente predicen o solo se alinean con etiquetas. Descubre la validez en clasificación con metadatos.

Evaluamos PlanGPT con métricas de coste y tiempo. ¿El resultado? No es mejor que una estrategia greedy. Descubre por qué.

Descubre cómo la granularidad de tareas afecta el olvido catastrófico en el aprendizaje continuo. Estudio comparativo con EWC en CIFAR-100. ¡Lee más!
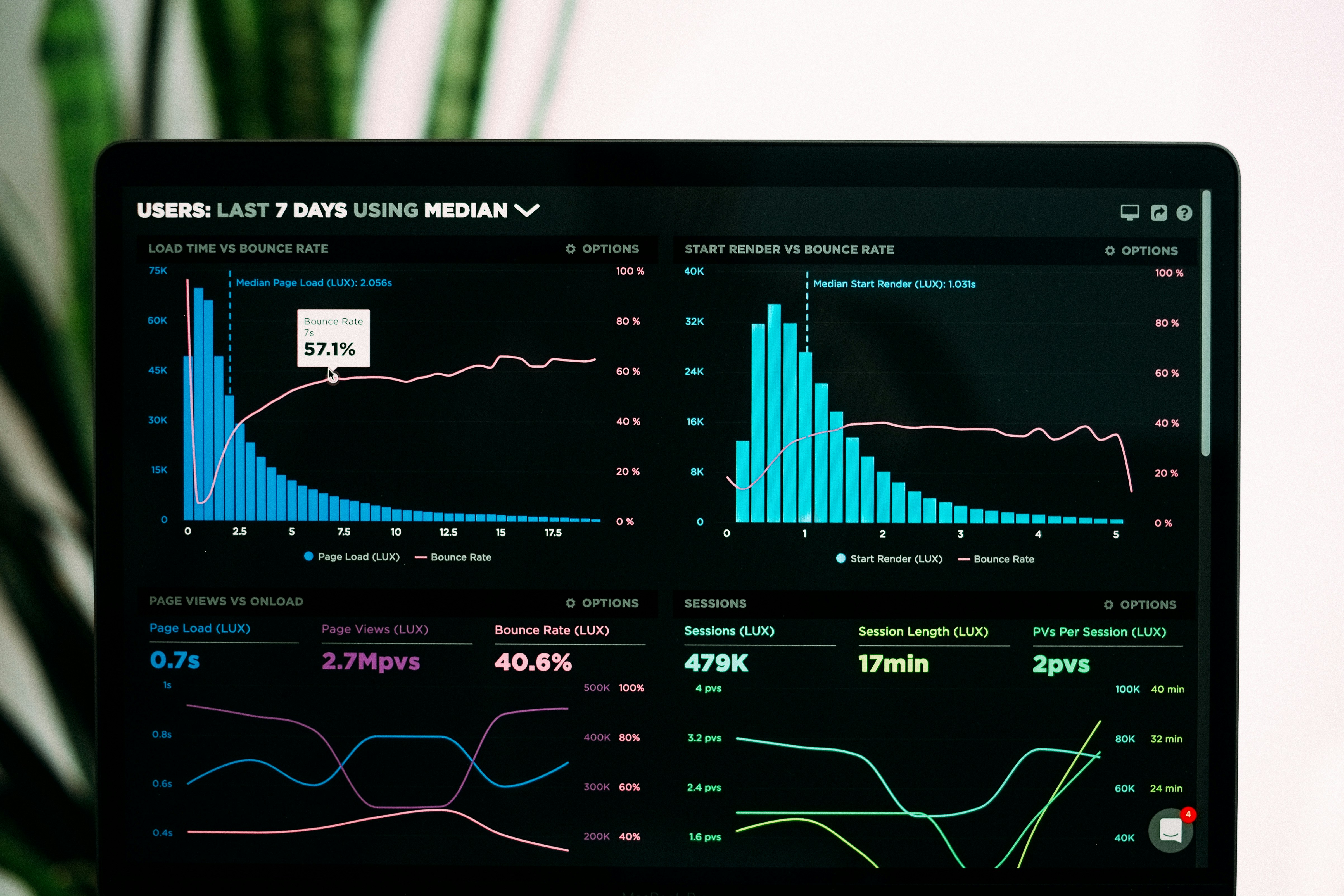
La nube segura impulsa la mejora continua con paneles en tiempo real, gestión de ideas y alertas. Q2BSTUDIO te guía hacia la excelencia operativa.

El benchmark Errorquake-10k muestra que la severidad de errores difiere en LLMs con igual precisión. Una métrica clave para evaluar modelos de IA.

Descubre cómo detectar regresiones en el inicio de tu app iOS con XCUITests, CI y alertas Slack para evitar que lleguen a producción.