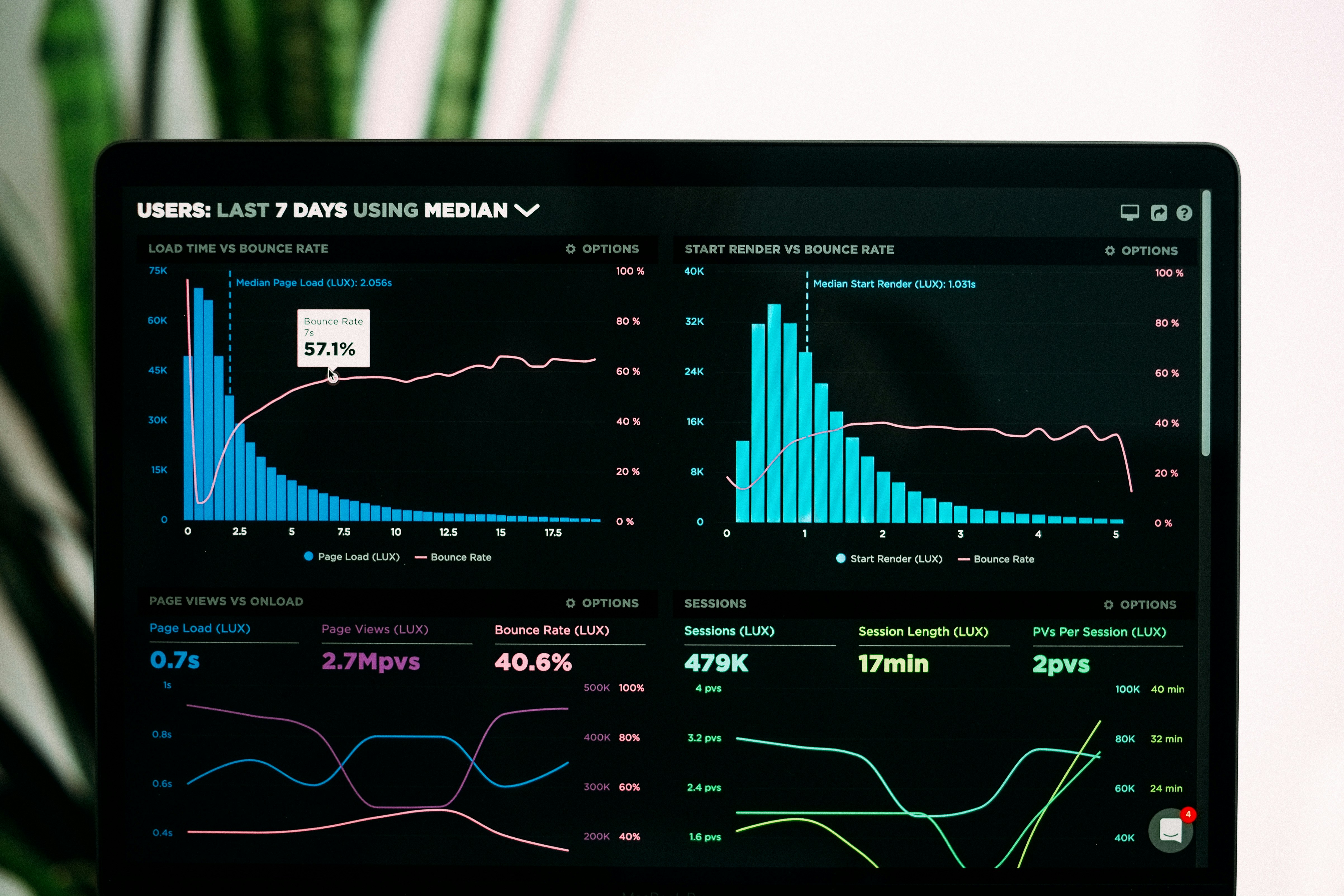
Portal web para gestionar agentes de IA y LLMs en Santa Cruz de Tenerife 2026
Portal web para gestión autónoma de agentes IA y LLMs en Tenerife. Configura prompts, monitorea costos, controla gobernanza sin depender de ingeniería.
Portal web para gestión autónoma de agentes IA y LLMs en Tenerife. Configura prompts, monitorea costos, controla gobernanza sin depender de ingeniería.
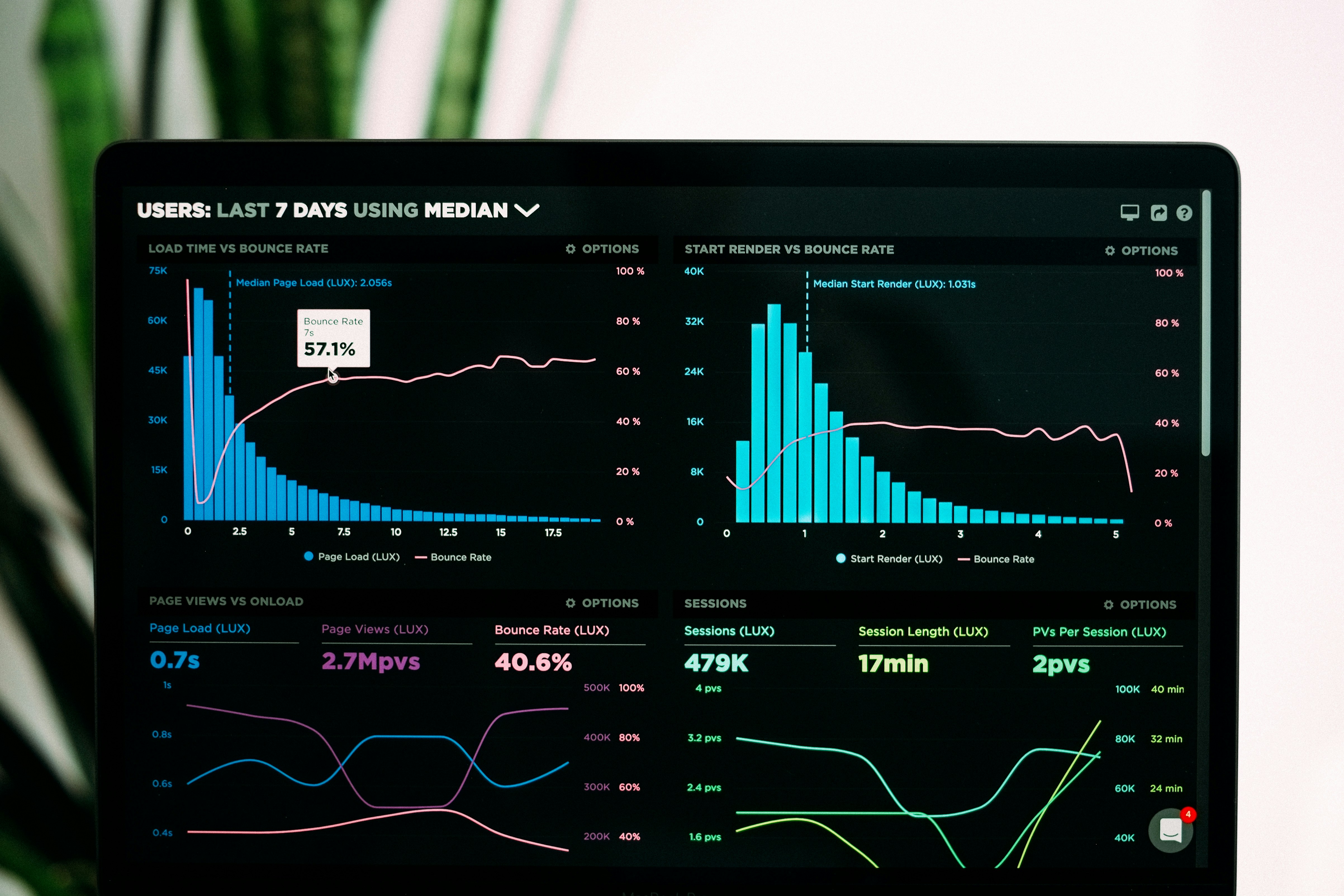
Descubre cómo Q2BSTUDIO construye portales web personalizados para gestionar agentes IA y LLMs en Sevilla, dándote autonomía sin depender de ingeniería.
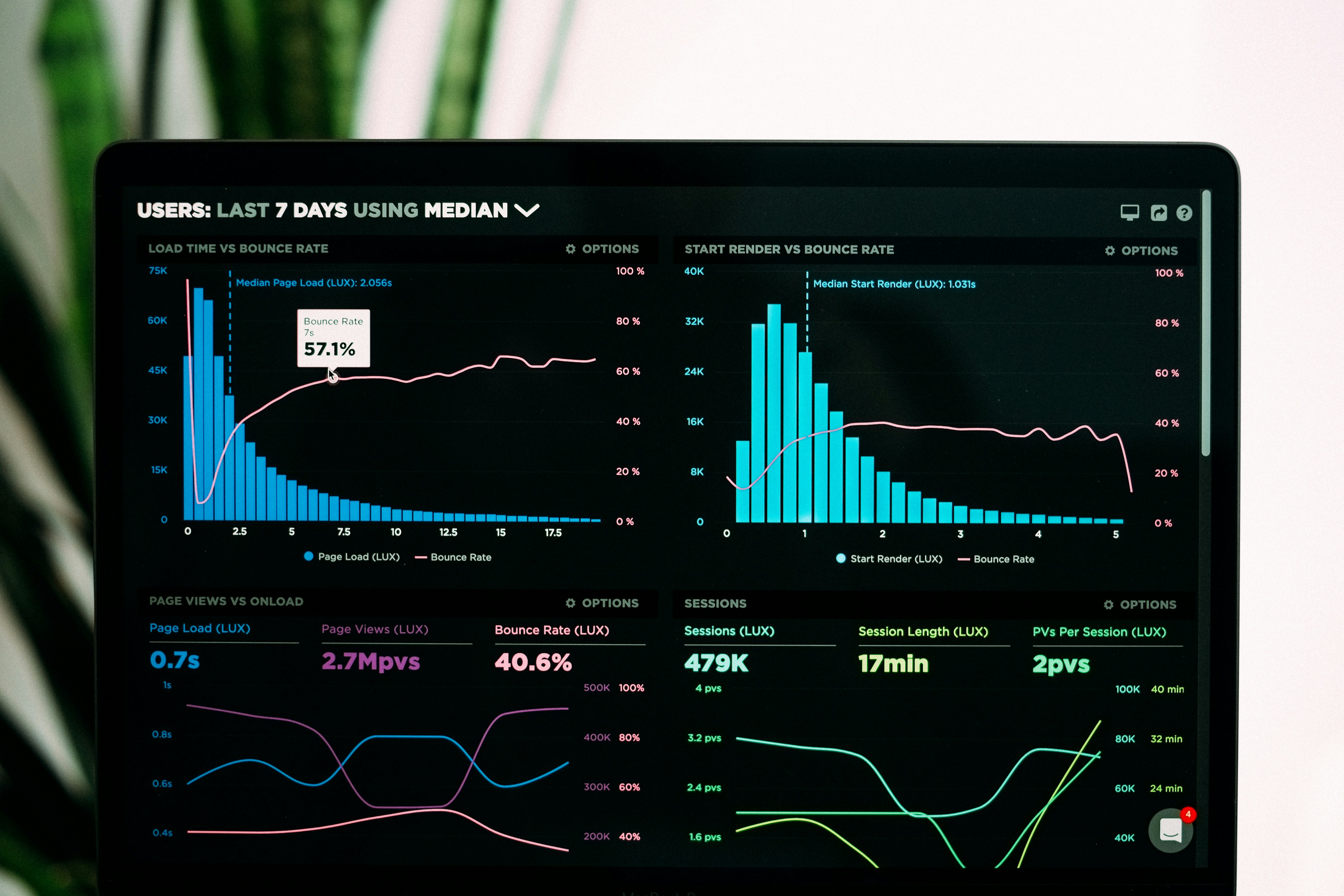
Descubre cómo Q2BSTUDIO construye portales web a medida para gestionar agentes de IA y LLMs. Controla prompts, costos y gobernanza sin depender de ingeniería.
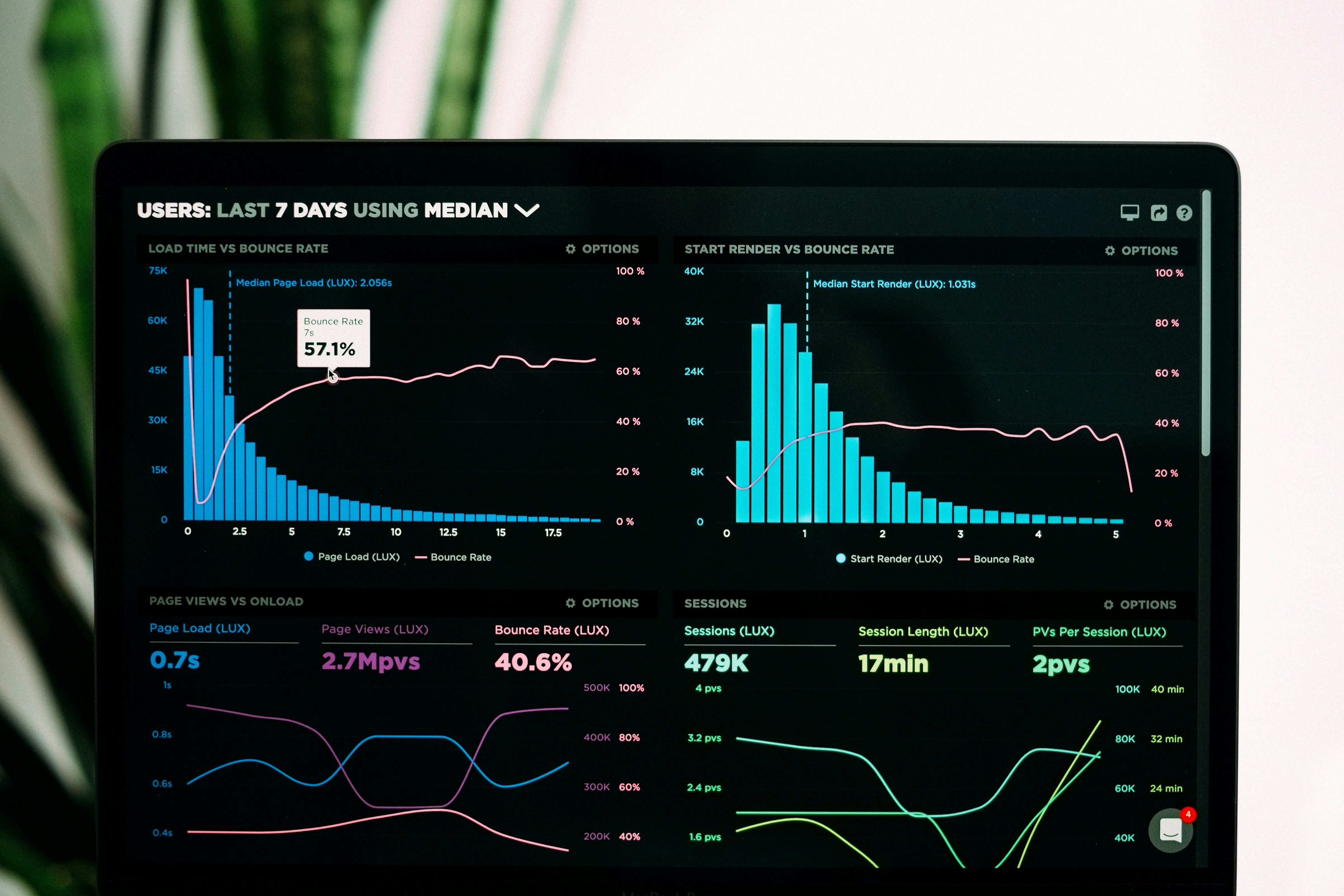
Descubre cómo un portal web de Q2BSTUDIO gestiona agentes IA y LLMs, reduce costos y acelera procesos en tu empresa en España.
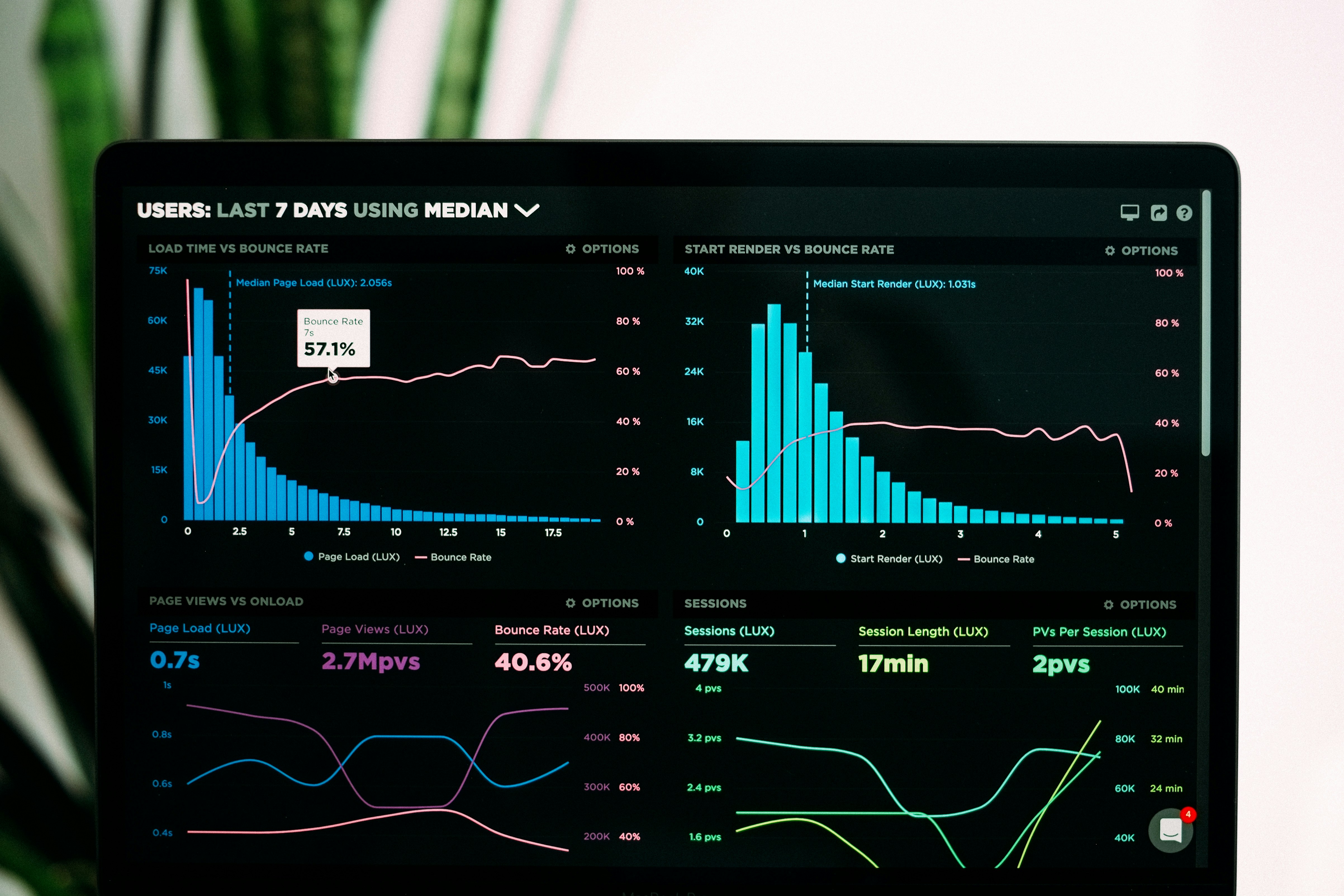
Descubre cómo Q2BSTUDIO crea portales web a medida para gestionar agentes de IA y LLMs en Valencia. Controla prompts, costes y gobernanza sin depender de ingeniería.

Descubre el portal web a medida de Q2BSTUDIO para gestionar agentes de IA y LLMs en Valladolid. Autonomía para tu equipo sin depender de ingeniería.
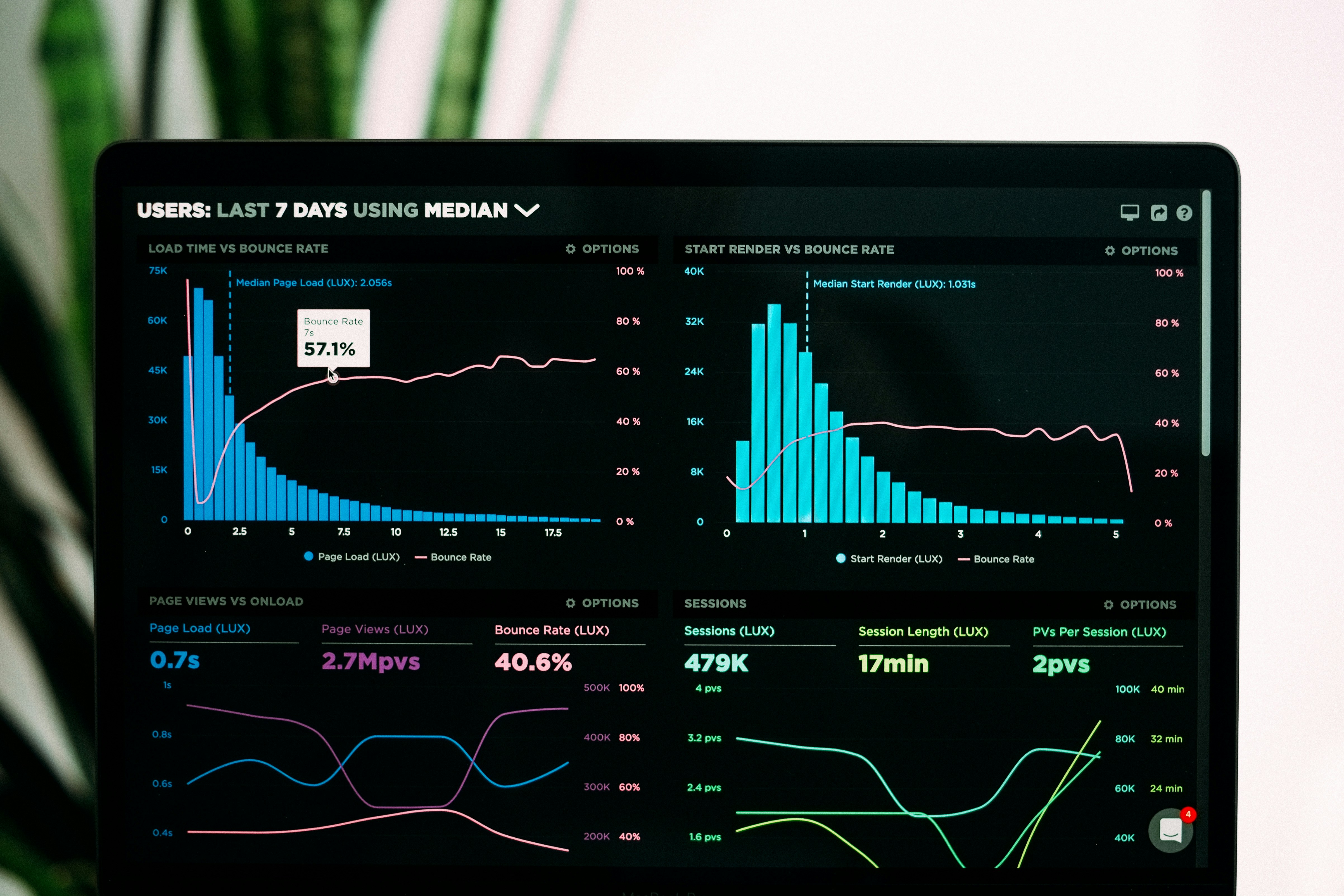
Gestiona agentes IA y LLMs en Zaragoza con portales web a medida de Q2BSTUDIO. Autonomía empresarial, ahorro de costos y gobernanza sin ingeniería.

Descubre PSEBench, el nuevo benchmark verificable para evaluar LLMs en el triaje de eventos de seguridad del paciente. Resultados clave y brechas identificadas.

Descubre cómo OPT* entrena LLMs con razonamiento paso a paso en optimización. Usa recompensas verificables y RL para espacios de búsqueda complejos.

Descubre cómo Bucket-Level MOO resuelve conflictos de gradientes en el ajuste fino multilingüe, mejorando el rendimiento de los LLMs en múltiples idiomas.
Descubre qué modelos de LLM son más efectivos para generar pruebas formales en Lean 4. Gemini y Claude lideran, pero Nemotron es el más eficiente.

Descubre cómo los VLMs fallan al razonar sobre el tiempo, usando atajos visuales en lugar de lógica cronológica. Nuevo benchmark y datasets para mejorar la IA.
Descubre por qué los LLMs corrigen errores ajenos pero no los propios: un artefacto del chat-template que revela una ilusión de autocorrección.

Descubre cuándo los agentes conversacionales con IA deben integrar memorias sensibles y cómo la evaluación RBI-Eval revela sesgos en modelos como GPT y Claude.

Vortex es un sistema que acelera el diseño de algoritmos de atención dispersa, logrando hasta 3.46x más rendimiento en LLMs. Ideal para agentes de IA que buscan optimizar la inferencia.
Descubre Benchmark Agent, un sistema autónomo que crea benchmarks de alta calidad para evaluar LLMs y MLLMs sin intervención humana. Ideal para investigación.

Con Synapse, enruta herramientas federadas entre LLMs heterogéneos sin compartir datos, con privacidad diferencial y precisión casi sin pérdida.

Descubre cómo optimizar la planificación clásica con grounding parcial semántico mediante LLMs. Reduce acciones y objetos irrelevantes, agilizando el proceso.
Optimiza tus modelos de lenguaje con CMPQ: cuantización de precisión mixta por canal que ahorra memoria y mejora el rendimiento en dispositivos edge.

Descubre por qué el decodificado contrastivo no mitiga alucinaciones en MLLMs según nueva investigación. Las mejoras en POPE son engañosas. ¡Entra para más!