
Más allá de la evaluación estática: co-evolución de estrategias con LLM
Descubre cómo la co-evolución de evaluadores supera la evaluación estática, permitiendo a los LLMs generar estrategias innovadoras en juegos adversariales.
Descubre cómo la co-evolución de evaluadores supera la evaluación estática, permitiendo a los LLMs generar estrategias innovadoras en juegos adversariales.

Descubre cómo la verificación estricta paso a paso mejora la detección de errores en pruebas matemáticas complejas, superando las limitaciones de los LLMs tradicionales.

La memoria persistente hace que los LLMs te den la razón aunque estés equivocado. Descubre cómo evaluamos y mitigamos este peligroso sesgo de adulación.

¿Pueden los LLMs más avanzados superar un examen ofimático estandarizado? Descubre los resultados y las limitaciones actuales en automatización de oficina.

Descubre CIAware-Bench, el benchmark que mide si los LLMs de frontera detectan intervenciones de control. Resultados revelan baja conciencia y variabilidad entre modelos.

Descubre el Efecto Interlocutor: los LLMs filtran hasta un 23% más de datos personales cuando interactúan con otros agentes de IA. Implicaciones en seguridad.
Genera documentación de código automática con LLMs y evalúala con múltiples jueces IA. Optimiza calidad y reduce esfuerzo en software sanitario.

¿Pueden los LLMs identificar a sus pares? La huella estilométrica sobrevive a la anonimización. Implicaciones clave para la EU AI Act.

Descubre EstRTL, un framework basado en LLMs que mejora la corrección del código RTL mediante estimación funcional. Aumenta la precisión hasta un 9%.

Descubre LC-QAT, un método innovador que logra cuantización de 2 bits para LLMs con solo 0.1% de datos, superando a otras técnicas. ¡Optimiza tus modelos!

Descubre cómo los modelos multimodales fallan al identificar y planificar el uso de herramientas físicas reales. Un nuevo benchmark revela sus limitaciones.

Descubre cómo las técnicas de edición de conocimiento en LLMs fallan al incorporar consecuencias lógicas. Un nuevo benchmark revela brechas de hasta 24%.
Spatial-Omni integra audio espacial en LLMs multimodales con codificación FOA. Mejora localización y razonamiento espacial. ¡Descúbrelo!

Descubre cómo AuRA internaliza la comprensión del audio en LLMs mediante LoRA, superando a sistemas en cascada con mayor eficiencia y precisión.
Descubre AuRA: integra comprensión de audio en LLMs mediante LoRA para modelado conjunto y eficiente inferencia paralela. Supera a sistemas en cascada.

Explora cómo los modelos de visión-lenguaje componen y cambian personalidades múltiples dinámicamente, afectando el razonamiento y la descripción de imágenes.

Modelos de visión-lenguaje con múltiples personalidades: ¿cómo afecta al rendimiento? Conoce los hallazgos sobre equilibrio y residuales.

GASLoC unifica comunicaciones y actualizaciones locales para preentrenar LLMs de forma eficiente, superando a DiLoCo en entornos heterogéneos.

Descubre cómo FlowTracer rastrea el flujo de razonamiento en modelos de lenguaje para asignar crédito preciso a los tokens clave y mejorar el aprendizaje por refuerzo.
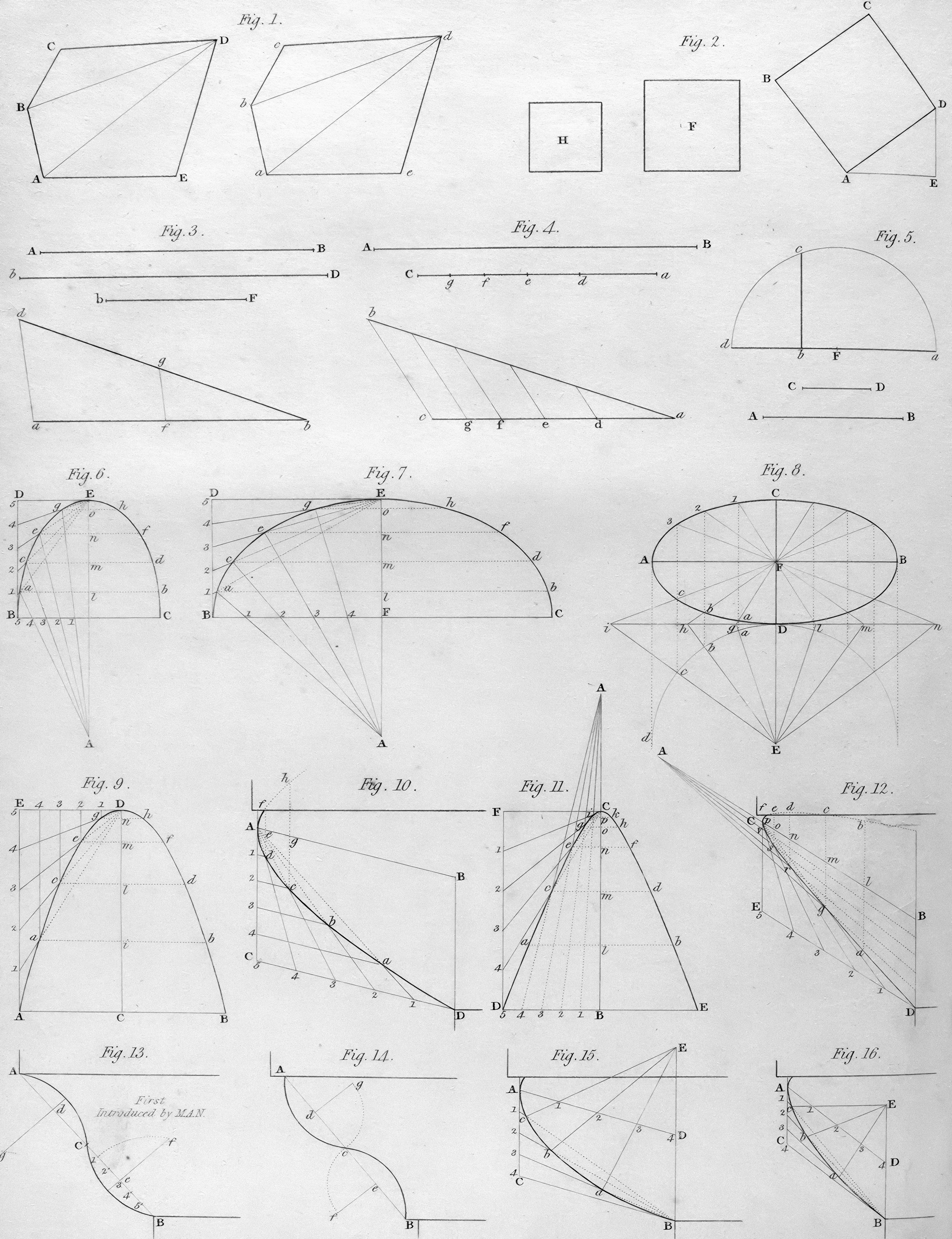
Descubre cómo los priores estructurales no paramétricos y los grafos de precedencia permiten a los LLMs predecir teoremas geométricos con un 89.29% de precisión, superando modelos supervisados.