
Prueba de estrés a 3 generadores 3D IA: datos y comparativa
Comparativa real de Meshy, Tripo y Rodin: latencia, coste y calidad. Analizamos 5 categorías y 4 métricas. Resultados sorprendentes.
Comparativa real de Meshy, Tripo y Rodin: latencia, coste y calidad. Analizamos 5 categorías y 4 métricas. Resultados sorprendentes.
¿Compartes pantalla sin cerrar WhatsApp? Esta extensión gratuita difumina tus chats automáticamente. Sin configuración ni riesgos.

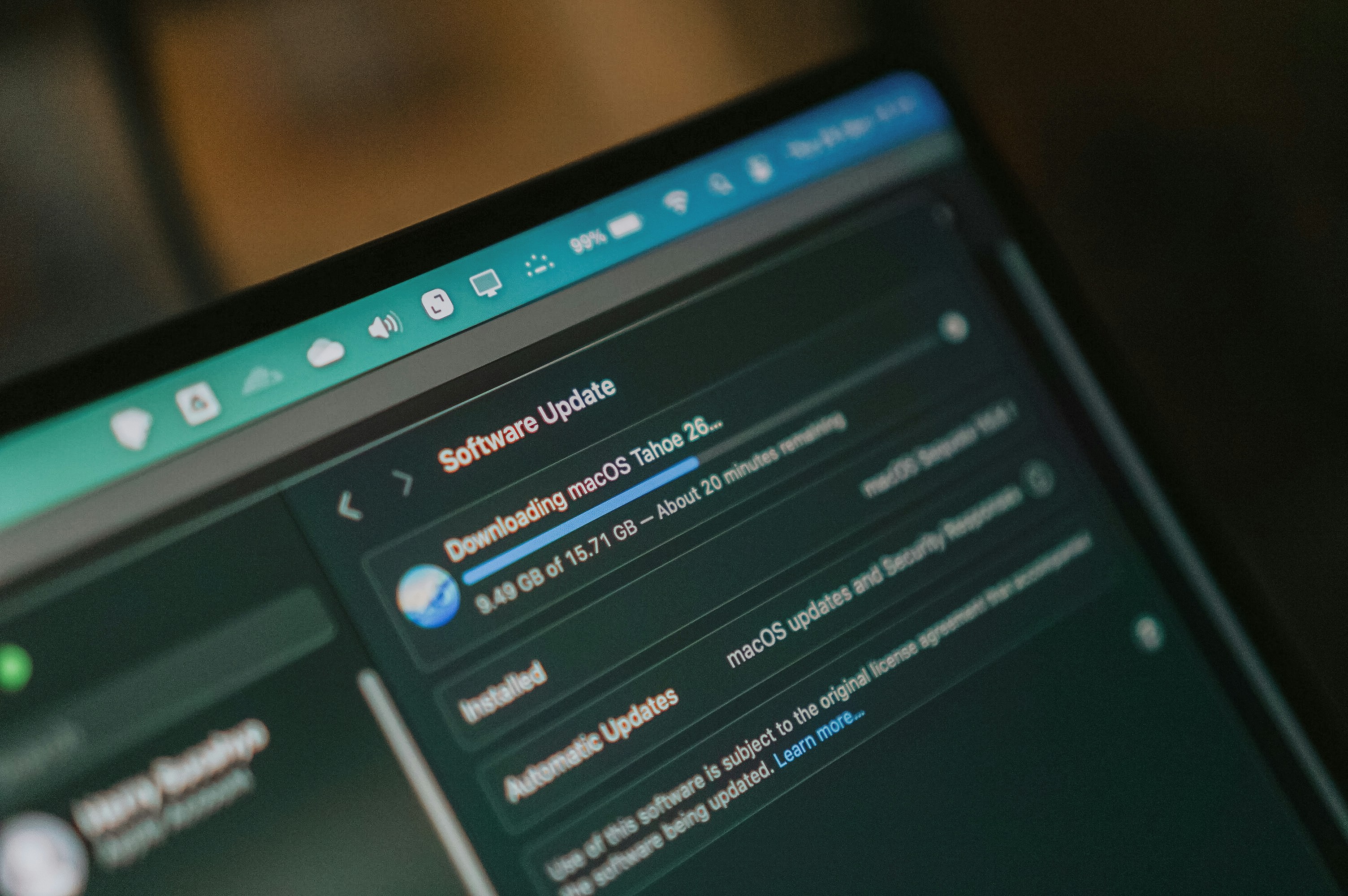
Descubre cómo llama.cpp b9455 iguala la velocidad de vLLM en 2x3090 con Qwen 27B. 70 t/s en decodificación y prefill ultrarrápido para agentes.
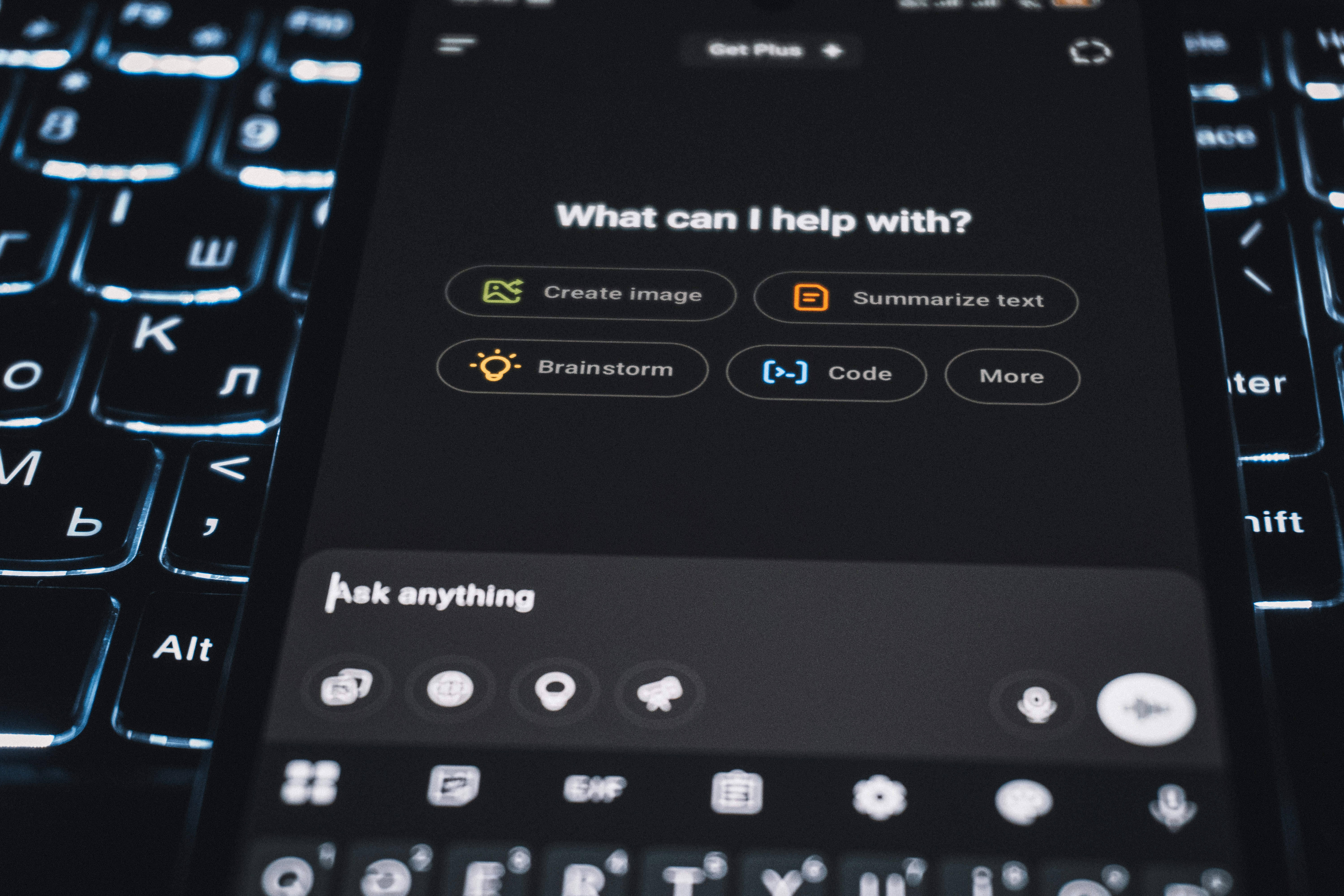
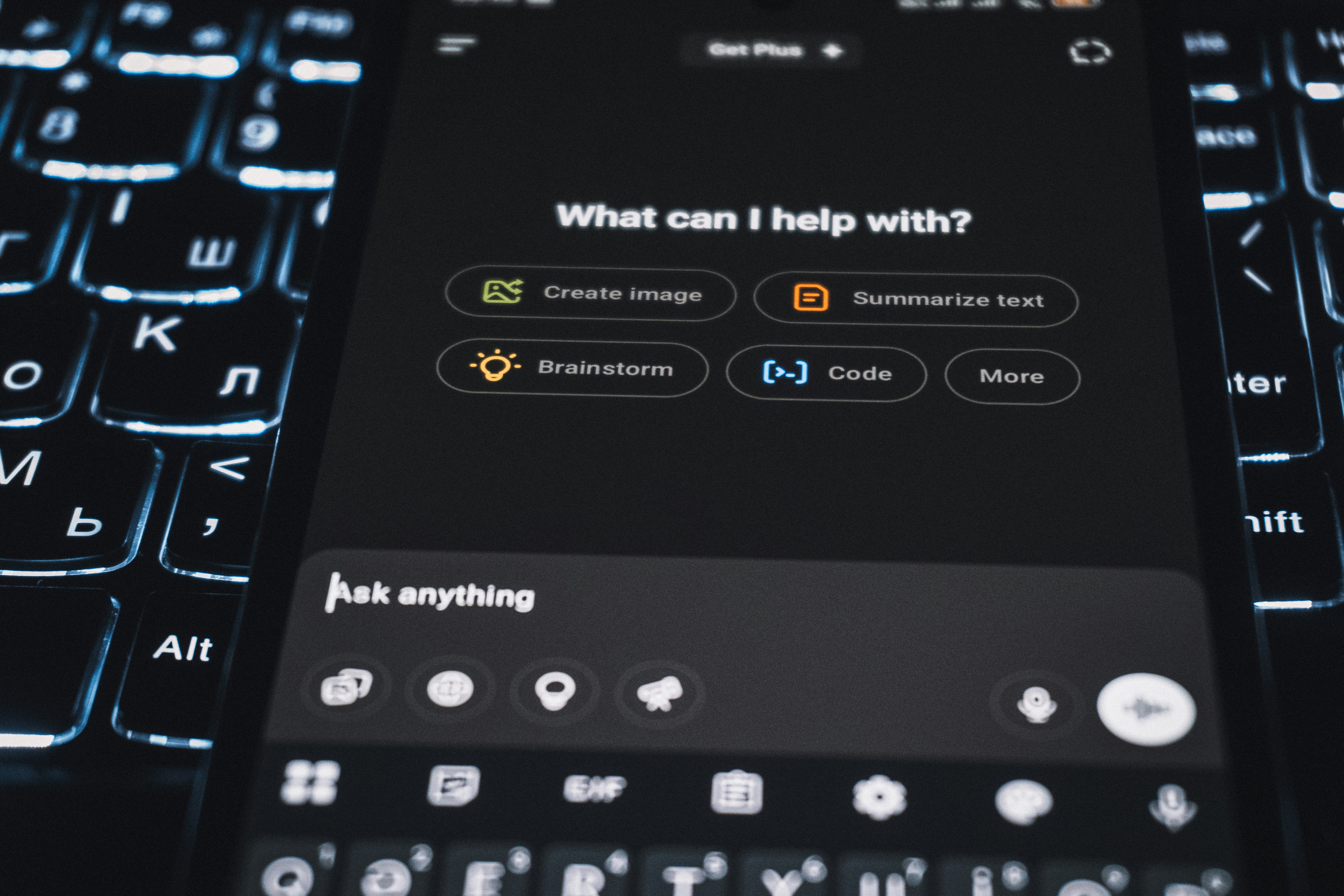
Descubre cómo MAVEN, un scaffold ligero de verificación, mejora la generalización en agentes de IA, logrando un 71% de precisión sin entrenamiento adicional y a 1/10 del coste.

Descubre cómo NVIDIA RTX Spark y DGX Spark revolucionan los agentes de IA locales con 1 petaflop de potencia, seguridad avanzada y optimizaciones para creadores.

Nueva función en Android 12+ verifica llamadas con señal silenciosa, protegiéndote de estafas telefónicas.

Descubre cómo Google combate las estafas con deepfake mediante su nueva detección de llamadas falsas. Protege tu identidad y evita fraudes telefónicos con IA.

Descubre cómo la última actualización de Android protege contra estafas de voz creadas con IA. Además, otras novedades de junio.
Descubre cómo Google combate las llamadas deepfake con IA en la actualización de junio. Activación automática y cómo funciona la verificación por RCS.

Descubre CSD, técnica de destilación que evita suavizado softmax y optimiza logits, mejorando modelos de lenguaje grandes. Ideal para IA eficiente.

Evaluamos el rendimiento de seis apps de videollamada con IA. ¿Qué importa más: latencia o capacidad del modelo? Resultados sorprendentes.
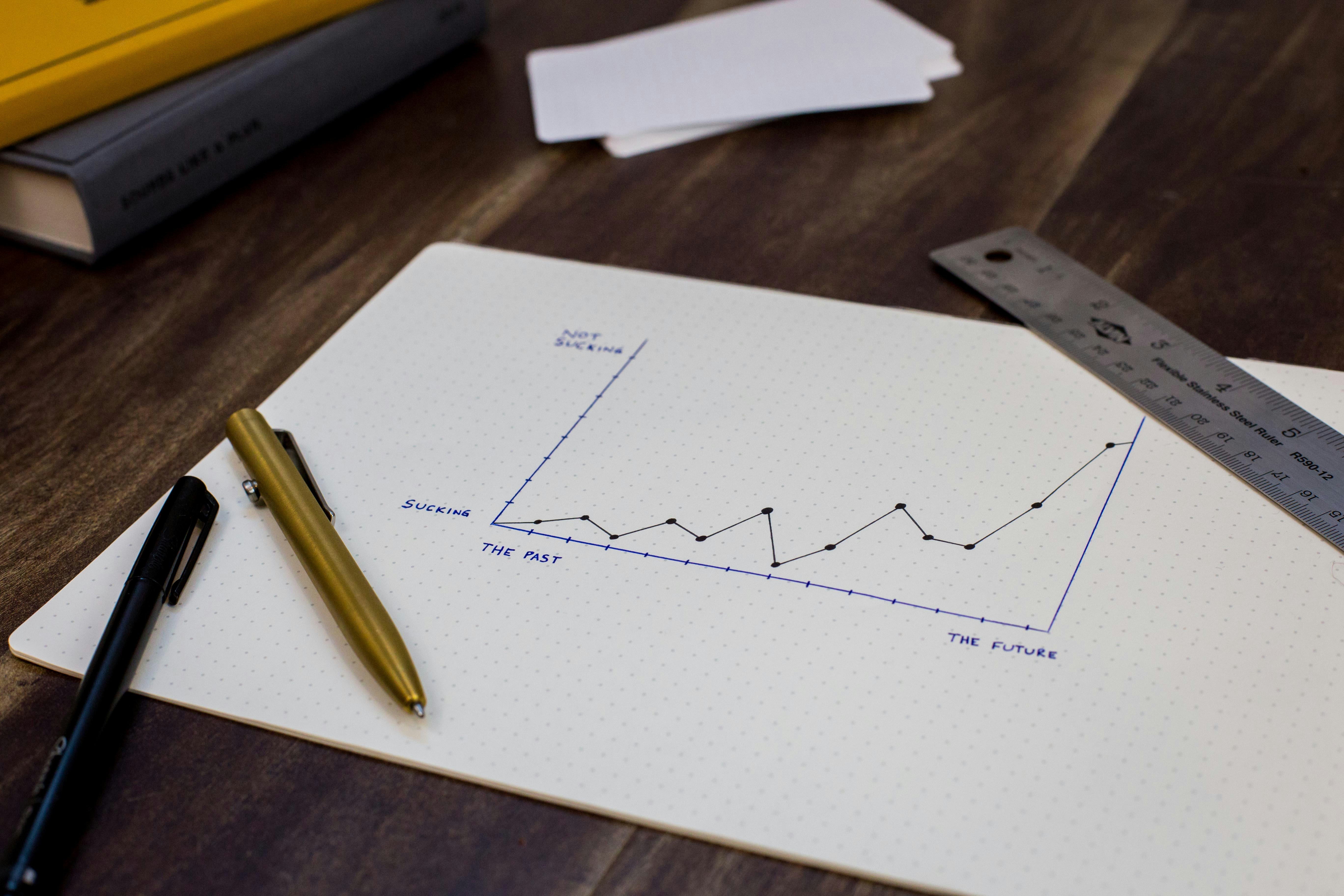
Descubre 5 consejos simples y efectivos para mejorar rápidamente el rendimiento de tu equipo de ventas. Aprende a concentrar leads, involucrarte más y cerrar más deals.

Descubre cómo una nueva gramática de flujos de trabajo evita la filtración de datos en tiempo de llamada. Implementación en Python y R.

Solicite una consultoría para modernizar aplicaciones heredadas. Comparta objetivos y desafíos, participe en descubrimiento y reciba propuesta con ROI claro.

Descubre SABER: refinamiento selectivo para transferencia positiva en aprendizaje continuo sin olvidar.

Descubre cómo los LLMs como BERT, T5 y Llama se adaptan para detectar Alzheimer mediante fine-tuning y probing, logrando nuevos récords en datasets clínicos.

Descubre cómo las llamadas fantasma de agentes especulativos filtran tu intención al instante y cómo los contratos de privacidad pueden evitarlo. ¡Lee más!

Descubre LlamaStash, el lanzador de llama.cpp para terminal con TUI, CLI y proxy OpenAI. Ejecuta modelos de IA localmente sin sobrecarga y con gran rendimiento.

La policía de Irlanda del Norte alerta sobre estafadores que suplantan su número oficial. Aprende cómo evitar el fraude telefónico y proteger tus datos.
Descubre cómo LLMs listos para usar mejoran el razonamiento matemático sin entrenamiento, superando la votación mayoritaria hasta 28%.