
Modelos Autorregresivos Lineales de Dos Capas Estiman Estados Latentes
Descubre cómo los modelos autorregresivos de dos capas estiman estados latentes imitando el filtrado de Kalman. Con resultados teóricos.
Descubre cómo los modelos autorregresivos de dos capas estiman estados latentes imitando el filtrado de Kalman. Con resultados teóricos.
Descubre cómo ESE acelera pronósticos hasta 70x. Preciso, escalable y robusto para economía, salud, y más.
Descubre cómo la invarianza causal mejora la adaptación de dominio con pocos datos. Un estudio sobre regresión lineal y márgenes de riesgo.
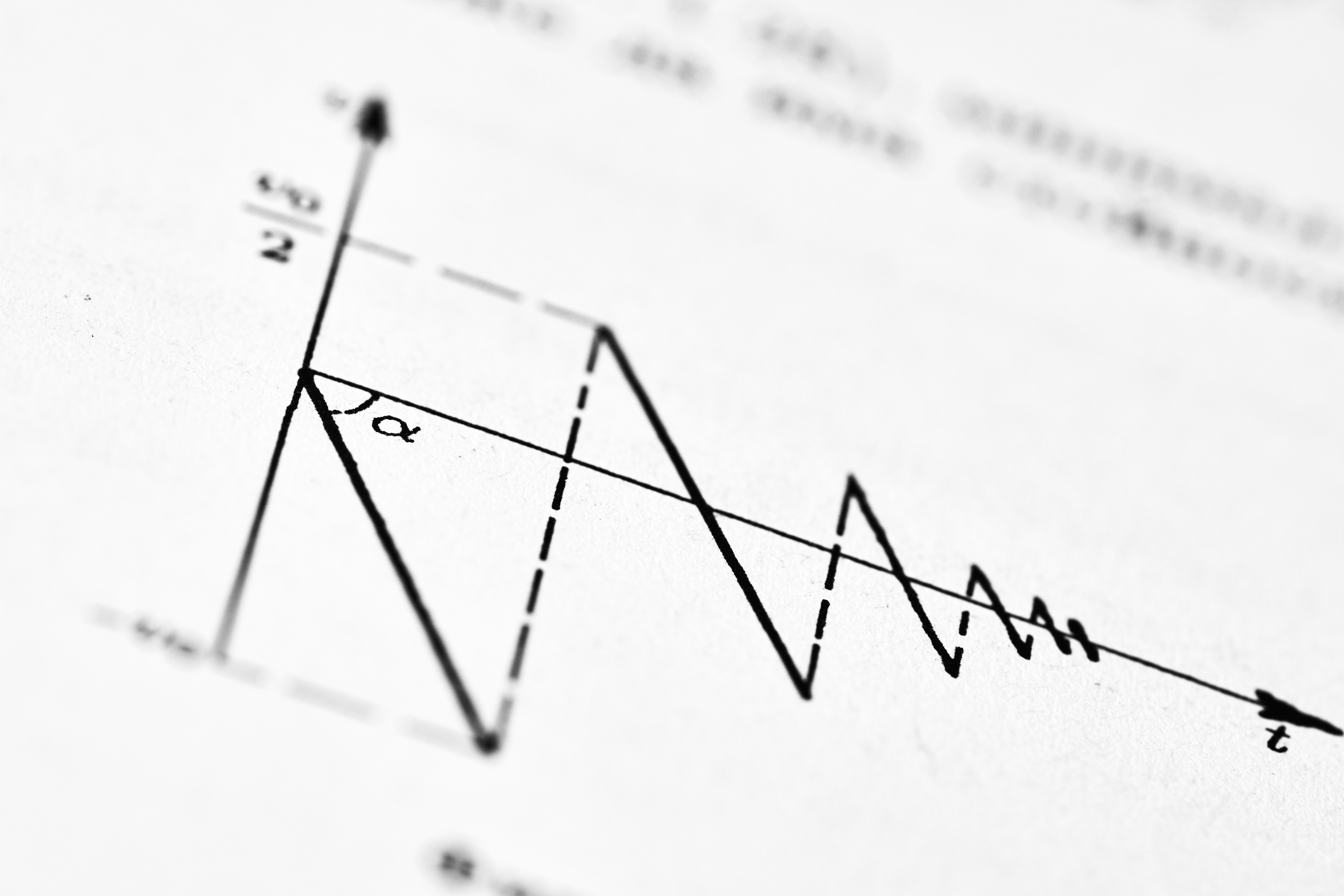
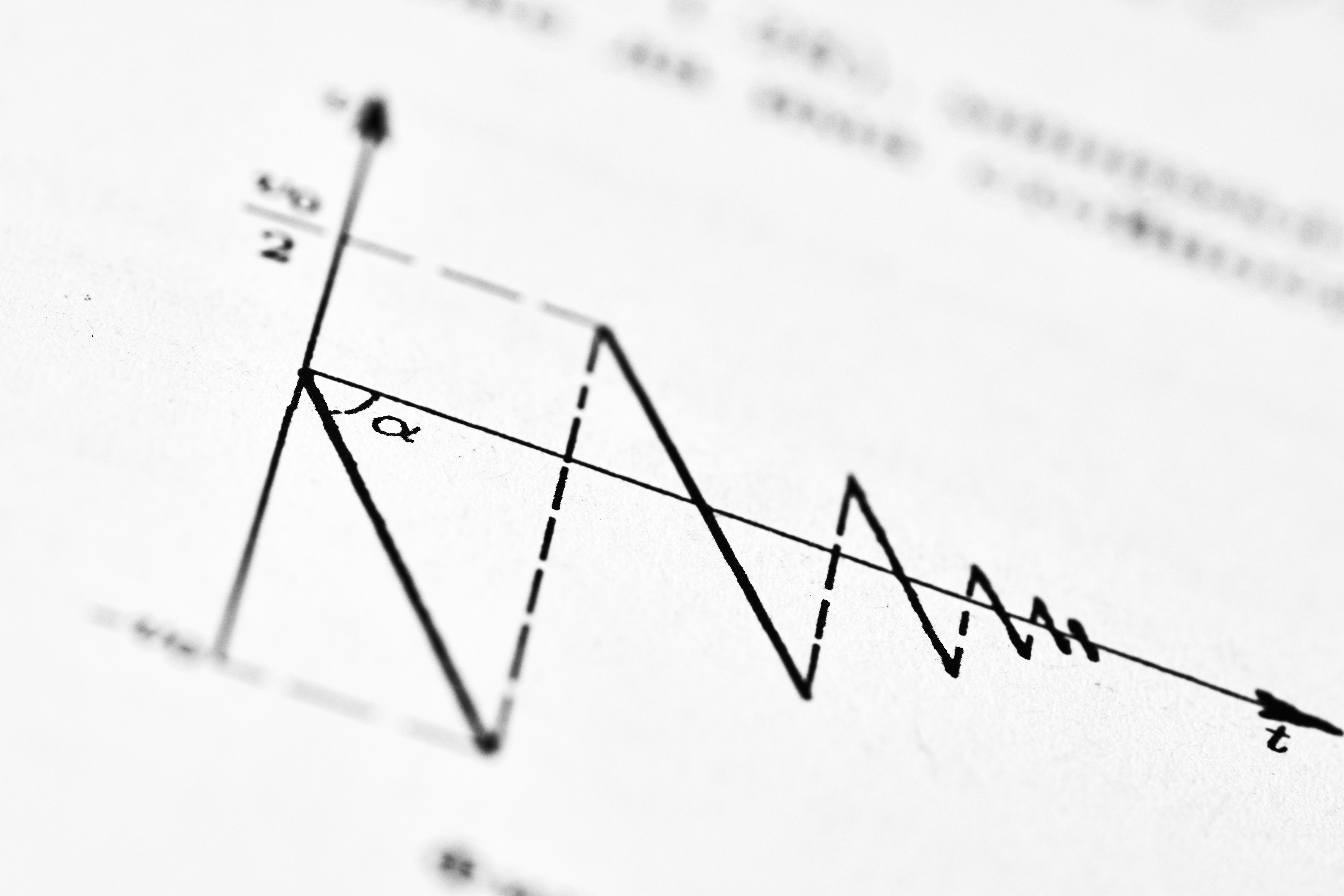
Implementaciones eficientes de SLOPE en R, Python, Julia y C++. Algoritmo híbrido de descenso coordenado para GLM. Benchmarks muestran rendimiento superior. ¡Descúbrelo!

Descubre q-PDGD, un método primal-dual cuantizado que logra convergencia lineal en optimización distribuida con gradientes estocásticos y comunicación de bits limitados.

Un estudio revela que al rolear, los LLMs cambian lo que dicen pero no su representación interna. La desalineación emergente sí altera las creencias.

Descubre cómo el control jerárquico y el codiseño de topología mejoran la robustez de sistemas en red, aplicado a microrredes DC con enfoques basados en modelos y datos.
Descubre cómo descomponer capas lineales en primitivas geométricas usando álgebra de Clifford, reduciendo parámetros de O(d²) a O(log²d) sin perder rendimiento.

Descubre KLA: Atención Lineal de Kalman, un filtrado bayesiano paralelo que supera a Mamba y GLA en modelos de lenguaje.
Conoce cómo el algoritmo MLMS garantiza estabilidad y bajo arrepentimiento en datos no estacionarios, perfecto para streaming.
Descubre cómo RuleSHAP combina regresión bayesiana y valores Shapley para detectar efectos no lineales en datos epidemiológicos con incertidumbre cuantificada.
Descubre cómo el estimador de distancia mínima con Hellinger logra estimar densidades en tiempo casi lineal para mezclas gaussianas y log-cóncavas. ¡Lee más!
Descubre la formulación integral de QENDy que elimina las derivadas temporales, logrando identificación robusta de sistemas no lineales frente al ruido.

Descubre cómo el enfoque de gradiente mejorado elimina las restricciones de lotes en el Lasso renovable para alta dimensionalidad. Resultados precisos con datos en streaming.

Descubre cómo la teoría bayesiana explica la aparición abrupta de patrones de copia en la atención de transformers. Un estudio sobre transiciones de fase.

Exploración paralela por dominio en agentes LLM supera a la lineal en localización de cambios multiarchivo. Resultados en SWE-bench.
Descubre Blurry Window Attention (BLA), un método innovador que mejora la eficiencia en atención de transformers para contextos largos, superando limitaciones de cuadrático y memoria.
DLA optimiza la atención en LLMs fusionando estados dinámicamente, reduciendo errores y manteniendo rendimiento en contextos largos.

Descubre cómo el promedio geométrico de actualizaciones de objetivo duro estabiliza el Q-learning lineal. Un nuevo enfoque para mejorar el aprendizaje por refuerzo.

Estructuras lineales locales en pesos y activaciones son recuperables pero evolucionan rápido, desafiando direcciones de tarea fijas. Estudio con GPT-2 y LoRA.