
LoopVLA: Aprendizaje de Suficiencia en Refinamiento Recurrente para Modelos de Visión-Lenguaje-Acción
LoopVLA presenta refinamiento recurrente para modelos de visión-lenguaje-acción, mejorando la precisión y eficiencia en tareas multimodales.
LoopVLA presenta refinamiento recurrente para modelos de visión-lenguaje-acción, mejorando la precisión y eficiencia en tareas multimodales.

<meta content=Descubre VLADriver-RAG, el modelo VLA aumentado con recuperación para conducción autónoma. Mejora la precisión y el razonamiento en tiempo real. Tecnología innovadora para vehículos inteligentes.>
Métodos de inferencia asíncrona en modelos VLA: optimiza el procesamiento en tiempo real y la eficiencia computacional para sistemas robóticos avanzados.
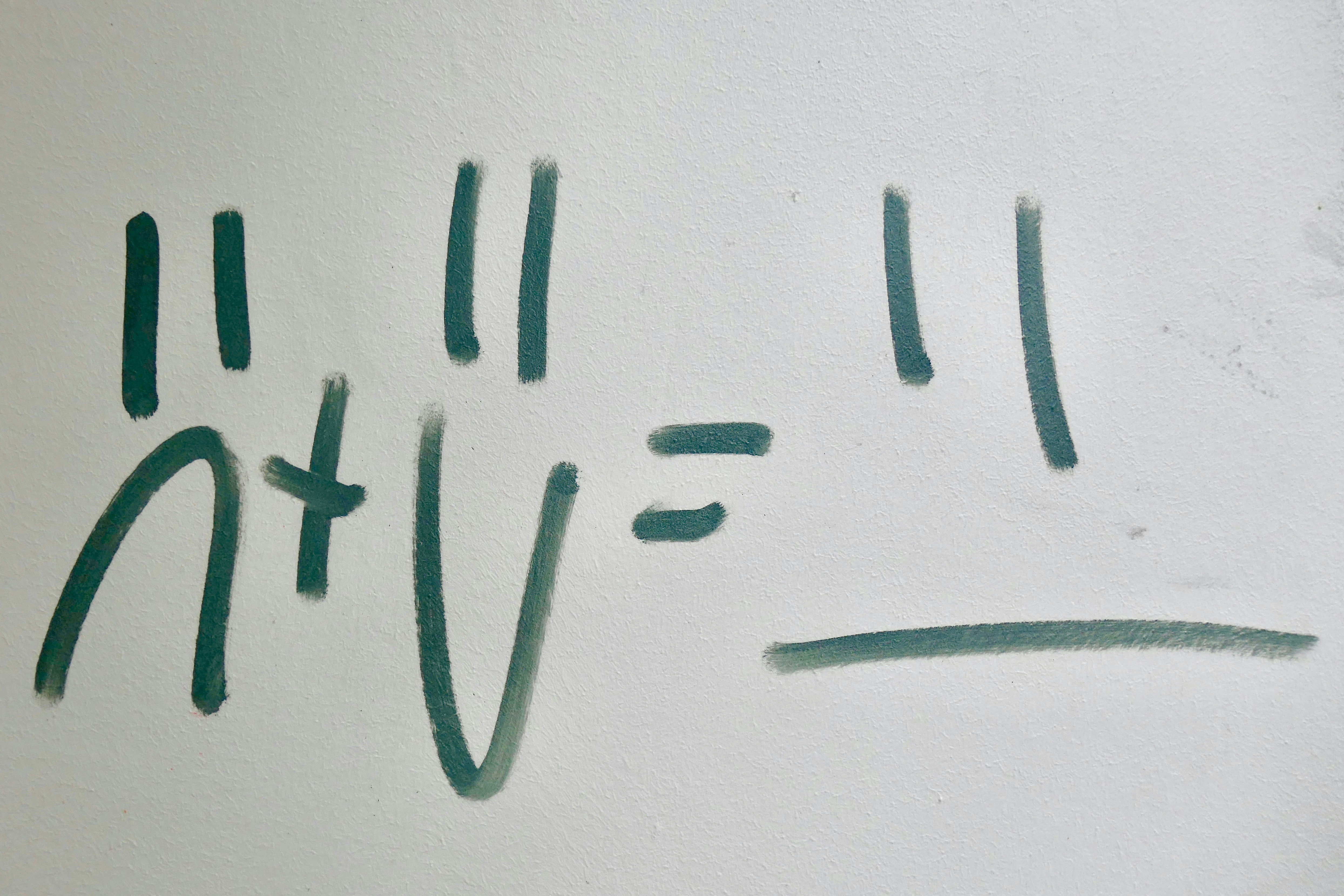
<meta name=description content=Transiciones latentes algebraicamente consistentes para modelos VLA. Descubre cómo mejoran la coherencia y eficiencia en tareas de visión-lenguaje-acción.>

<meta content=Agentes encarnados de horizonte largo con modelos VLA alineados a herramientas: inteligencia autónoma para acciones complejas y prolongadas.>

Aprendizaje rápido de preferencias lenguaje-acción para sistemas semi-autónomos. Optimiza la interacción humano-máquina con algoritmos adaptativos eficientes.

Descubre cómo el entrenamiento en tiempo de prueba optimiza modelos VLA con previsión visual. Mejora rendimiento y adaptabilidad en tiempo real.
CoWorld-VLA: modelo mundial multi-experto para conducción autónoma que mejora percepción y decisiones en entornos complejos.

Verificación de propiedad mediante puertas traseras en modelos VLA. Descubre métodos clave para garantizar seguridad y transparencia en inteligencia artificial.