
Inferencia válida con datos sintéticos mediante intercambiabilidad de tareas
¿Cómo usar datos sintéticos sin sesgos? Descubre la intercambiabilidad de tareas, un nuevo método para inferencias válidas en investigación científica con IA.
¿Cómo usar datos sintéticos sin sesgos? Descubre la intercambiabilidad de tareas, un nuevo método para inferencias válidas en investigación científica con IA.

Nuevo marco automatizado evalúa la creatividad de modelos de lenguaje en tareas abiertas: mide novedad, diversidad y cumplimiento.
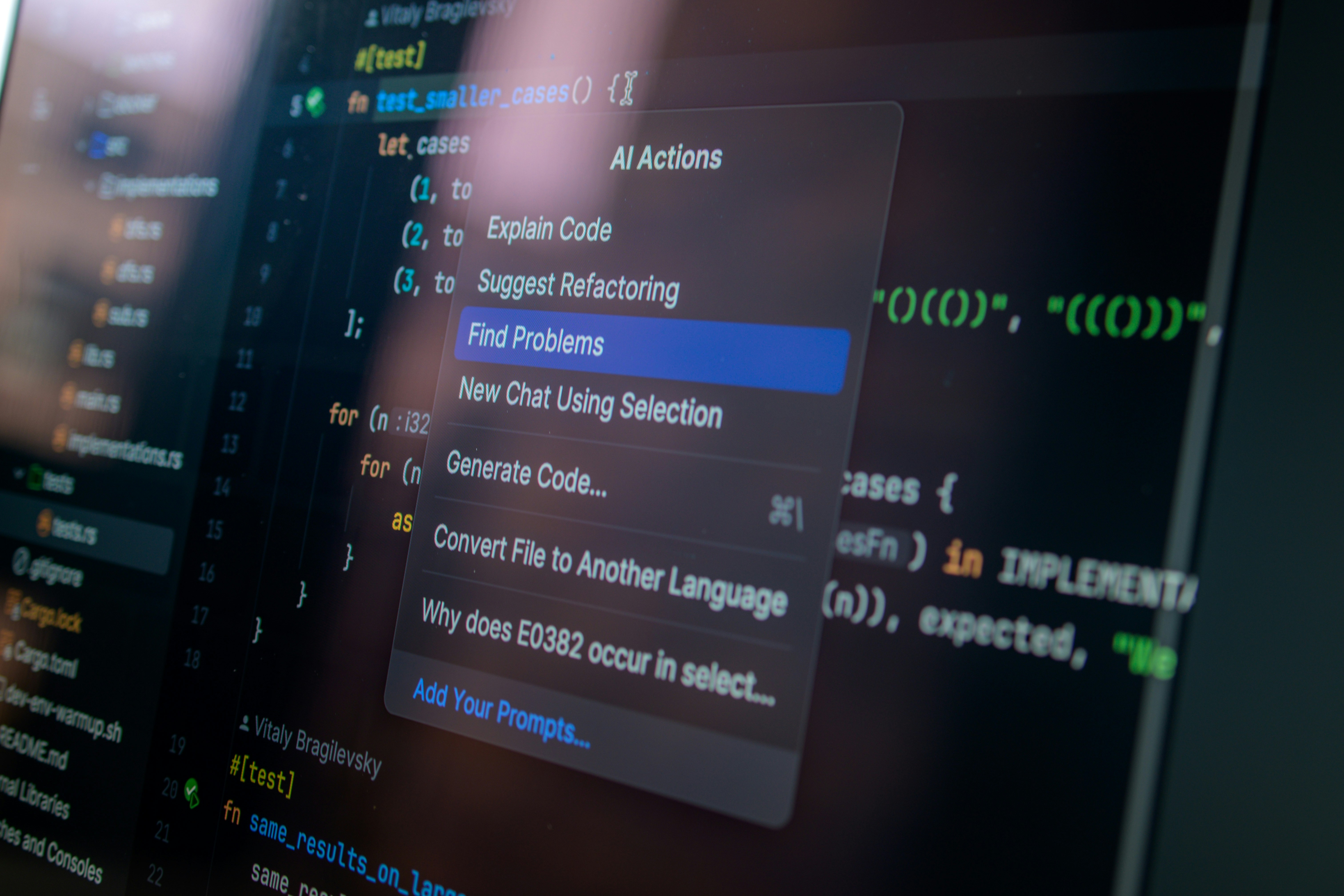
Genera documentación de código automática con LLMs y evalúala con múltiples jueces IA. Optimiza calidad y reduce esfuerzo en software sanitario.

¿Los modelos de IA mienten? Este estudio usa log-probabilidades y juez LLM para evaluar razonamiento en debates multi-agente y detectar fallos críticos.

Los LLM como jueces fallan: solo detectan el 22% de los defectos. Conoce los puntos ciegos y cómo afectan a agentes transaccionales multi-turno.

Las comparaciones por pares con Elo generan rankings de precisión casi perfectos en modelos de IA, minimizando sesgos de estilo y juez. ¡Descúbrelo!

Descubre cómo un Juez LLM independiente evita errores de agentes en auditorías empresariales. Lecciones prácticas de implementación con LangGraph.

Los jueces LLM son estables en reevaluaciones neutrales, pero vulnerables a retos dirigidos. El ERS mide su robustez interaccional. Conoce sus implicaciones.

Descubre SAGE, el framework que combina juicio humano y LLM para evaluar la relevancia en búsquedas a gran escala, con 92% menos costo y +0.25% de usuarios activos en LinkedIn.

¿50 o 200 trazas? Aprende a determinar el tamaño de muestra para validar un LLM como juez según el balance de clases. La clave está en el kappa de Cohen.

POLARIS entrena modelos pequeños (9B) para escribir historias largas y de calidad, usando un juez LLM y referencias humanas. Compite con modelos mucho mayores.

Aprende cómo CHERRL reproduce y detecta reward hacking en RL con rúbricas, identificando sesgos del juez LLM para entrenar IA más segura.

Descubre cómo el cómputo de inferencia calibrado por distribución mejora la fiabilidad de LLM como juez, reduciendo errores y superando métodos tradicionales de votación.

Descubre cómo la evaluación semántica con LLM supera a TEDS y GriTS en precisión, con correlación humana de 0.93. Benchmark de 21 parsers PDF.

Descubre cómo un nuevo método de perturbación perceptual y modelado de recompensa corrige el sesgo en evaluaciones de LLMs multimodales. Más preciso y alineado con humanos.

Descubre BADGER, el marco unificado de Merkle que integra evaluación de SQL y agentes en IA empresarial, con métrica híbrida y 87.3% de precisión.

GLIDE: biblioteca Python que combina anotaciones humanas y predicciones de LLM para evaluar sistemas GenAI y agentes sin sesgo, ahorrando costos de anotación.

Descubre cómo diagnosticar la fiabilidad de los LLM como jueces usando la teoría de respuesta al ítem (IRT) para evaluar consistencia y alineación con expertos humanos.

Descubre SCOUT: defensa dinámica contra inyecciones de prompts, reduce ataques 46% y mejora eficiencia.

REAL: nuevo método de RL con regresión que mejora la evaluación de LLMs. Aumenta correlación hasta +18. Ideal para desarrolladores de IA.