
Entrenamiento supervisado degrada alineación de corteza visual
Un estudio revela que el entrenamiento supervisado reduce drásticamente la alineación con la corteza visual V1. Descubre qué reglas de aprendizaje preservan mejor la estructura cerebral.
Un estudio revela que el entrenamiento supervisado reduce drásticamente la alineación con la corteza visual V1. Descubre qué reglas de aprendizaje preservan mejor la estructura cerebral.

Descubre cómo el empoderamiento aprende representaciones solo con lo relevante para el control, ignorando el ruido. Perspectiva causal desde la interacción.
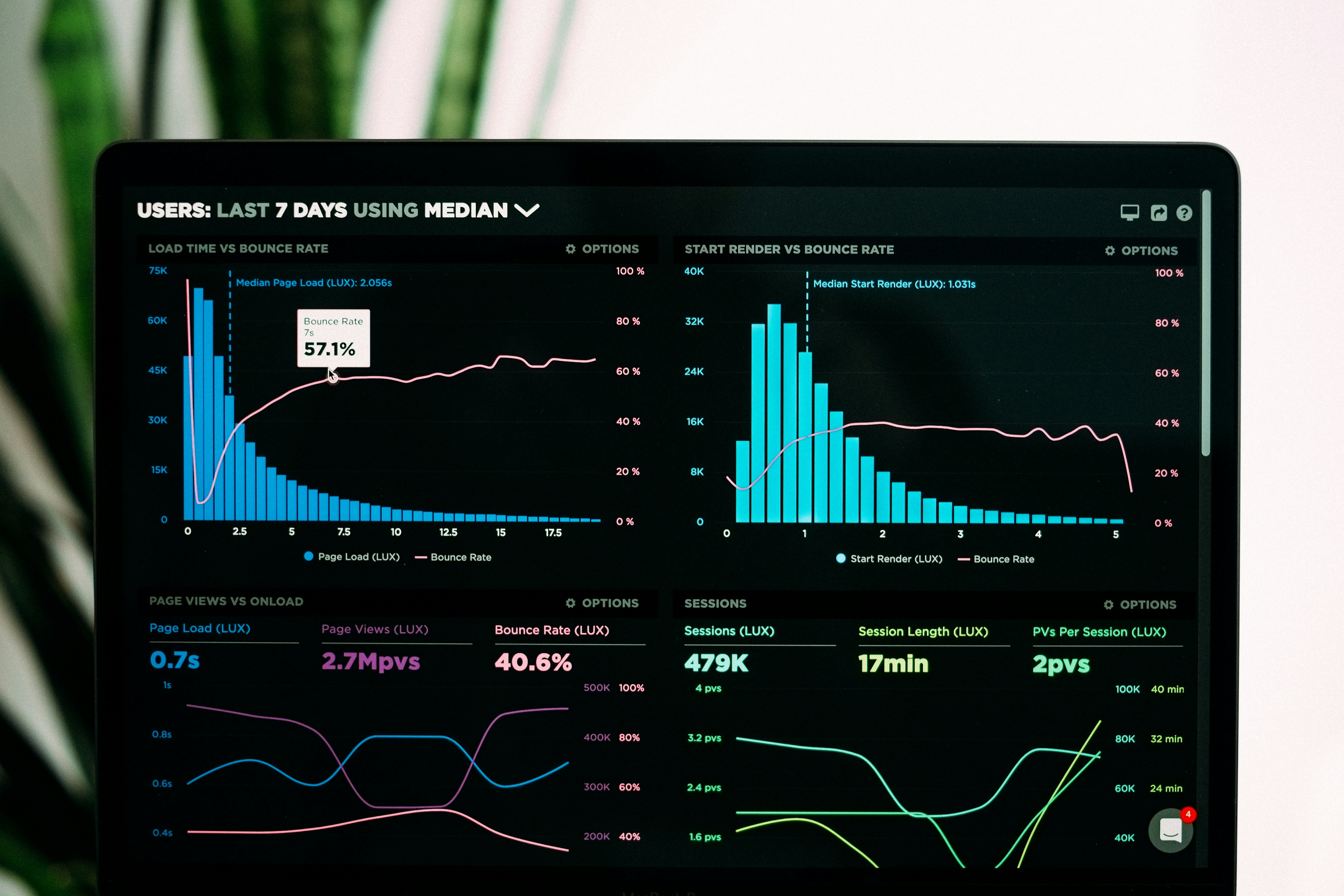
Descubre STEP, un método innovador que aprende representaciones interpretables de series temporales progresivas usando un compás latente. Predice estados y modos sin etiquetas.

Los Autoencoders Dispersos (SAEs) superan líneas base simples en el control de LLMs, igualando a LoRA en AxBench. Características seleccionadas con pipeline sup

Descubre cómo el nuevo método IAM usa la inconsistencia local para mejorar la generalización en modelos de deep learning, incluso sin etiquetas. Optimiza tu entrenamiento.

<meta name=description content=Explora en junio los mejores fondos de pantalla 2026. Dale un nuevo estilo a tu dispositivo.>

Descubre todo sobre criptomonedas en esta guía integral: desde conceptos básicos hasta estrategias de inversión y blockchain. Ideal para principiantes y expertos.
<meta name=description content=AgentTrove transmite 1.7M de trazas agentivas de ShareGPT y construye datasets SFT limpios en Python para entrenar modelos de IA.>
Descubre PiSAR, el benchmark de ajuste fino supervisado sensible a arquitectura para predicción de acciones en pantalla. Evalúa y mejora modelos con precisión.
<meta name=description content=DeepTool integra razonamiento y herramientas mediante aprendizaje por refuerzo supervisado por procesos. Descubre cómo optimiza la inferencia automatizada.>
Descubre FHRFormer, un transformer auto-supervisado que imputa y predice la frecuencia cardíaca fetal con alta precisión.

Descubre cómo los sistemas multiagente generan datos para lograr llamadas a funciones precisas y generalizables. Optimiza tu IA con esta técnica avanzada.

Descubre por qué el Reinforcement Learning (RL) preserva mejor los circuitos que el Supervised Fine-Tuning (SFT). Ventajas clave en ajuste de modelos.
Aprendizaje por refuerzo sin etiquetas con entropía cruzada entre modelos: innovadora técnica de IA que mejora la eficiencia del aprendizaje automático sin datos etiquetados.
<meta name=description content=Return-to-Go: alineación guiada por Q para aprendizaje supervisado condicionado. Más que un número, precisión optimizada.>

<meta name=description content=Descubre cómo el aprendizaje automático puede ser divertido y accesible. Aprende conceptos clave de forma clara y atractiva.>

GiPL: Pseudoetiquetado iterativo generativo para detección con pocas muestras en dominios cruzados. Mejora la adaptación entre dominios con mínimos datos etiquetados.
<meta content=La repetición en política como un proceso de ajuste fino supervisado continuo clave para entender su dinámica y evolución.>
Estudio sobre identificabilidad afín de CCA no lineal bajo priores latentes. Condiciones de unicidad y análisis teórico.

<meta name=description content=Descubrimiento no supervisado de habilidades jerárquicas: método automático para extraer estructuras de habilidades sin etiquetas. Ideal para robótica y aprendizaje por refuerzo.>