SpaTeoGL: Grafos espacio-temporales interpretables para zona de inicio de crisis
SpaTeoGL usa grafos espacio-temporales para localizar con precisión la zona de inicio de crisis en EEG intracraneal, mejorando la cirugía de epilepsia.
SpaTeoGL usa grafos espacio-temporales para localizar con precisión la zona de inicio de crisis en EEG intracraneal, mejorando la cirugía de epilepsia.

Nuevo método recupera características e interacciones locales importantes en Random Forest con garantías teóricas. Ideal para medicina personalizada.

Descubre PolyILR, descomposición ortonormal en árbol del símplex de Aitchison. Coordenadas interpretables para microbioma y genómica.
Bergson es una biblioteca open source que facilita la atribución de datos en modelos de lenguaje grandes. Implementa MAGIC, SOURCE y TrackStar. ¡Descúbrela!
Encuentra múltiples interpretaciones en conjuntos de datos analizando modelos con rendimiento similar pero características distintas. Mejora tu análisis de datos.

Aprende cómo la interpretabilidad audita datos de post-entrenamiento para moldear el aprendizaje y evitar sesgos en modelos de lenguaje.

Descubre cómo un autoencoder disperso revela los desafíos de interpretabilidad en un modelo fundacional de dinámica continua y sus discrepancias físicas.

Descubre cómo ICALens usa ICA para encontrar direcciones interpretables en LLMs sin entrenar diccionarios, superando a los SAEs en eficiencia y sondas.

Descubre cómo REACH reduce parámetros y FLOPs en estimadores de canal vehicular manteniendo la precisión con un enfoque de interpretabilidad.
Nuevo modelo de IA multimodal con regresión ordinal logra alta precisión en la clasificación de la severidad del Alzheimer usando MRI y datos clínicos.

Descubre cómo las KANs dispersas permiten una tomografía cuántica interpretable, revelando la estructura de Pauli en estados GHZ.

Descubre PianoKontext, un modelo de IA que genera interpretaciones expresivas de piano clásico a partir de partituras. Aprende cómo el flow matching en espacio latente logra timing natural.

Descubre cómo las características inestables en autoencoders dispersos no son ruido, sino parte de subespacios reproducibles. Un estudio clave para la interpretabilidad de redes neuronales.

Descubre cómo el SIM usa la mecánica lagrangiana para diseñar métodos interpretables. Una teoría que unifica y mejora la interpretabilidad.

Descubre por qué llamar 'razonamiento' a los tokens intermedios de los modelos de lenguaje puede llevar a malentendidos y malas prácticas en IA. Un análisis crítico.
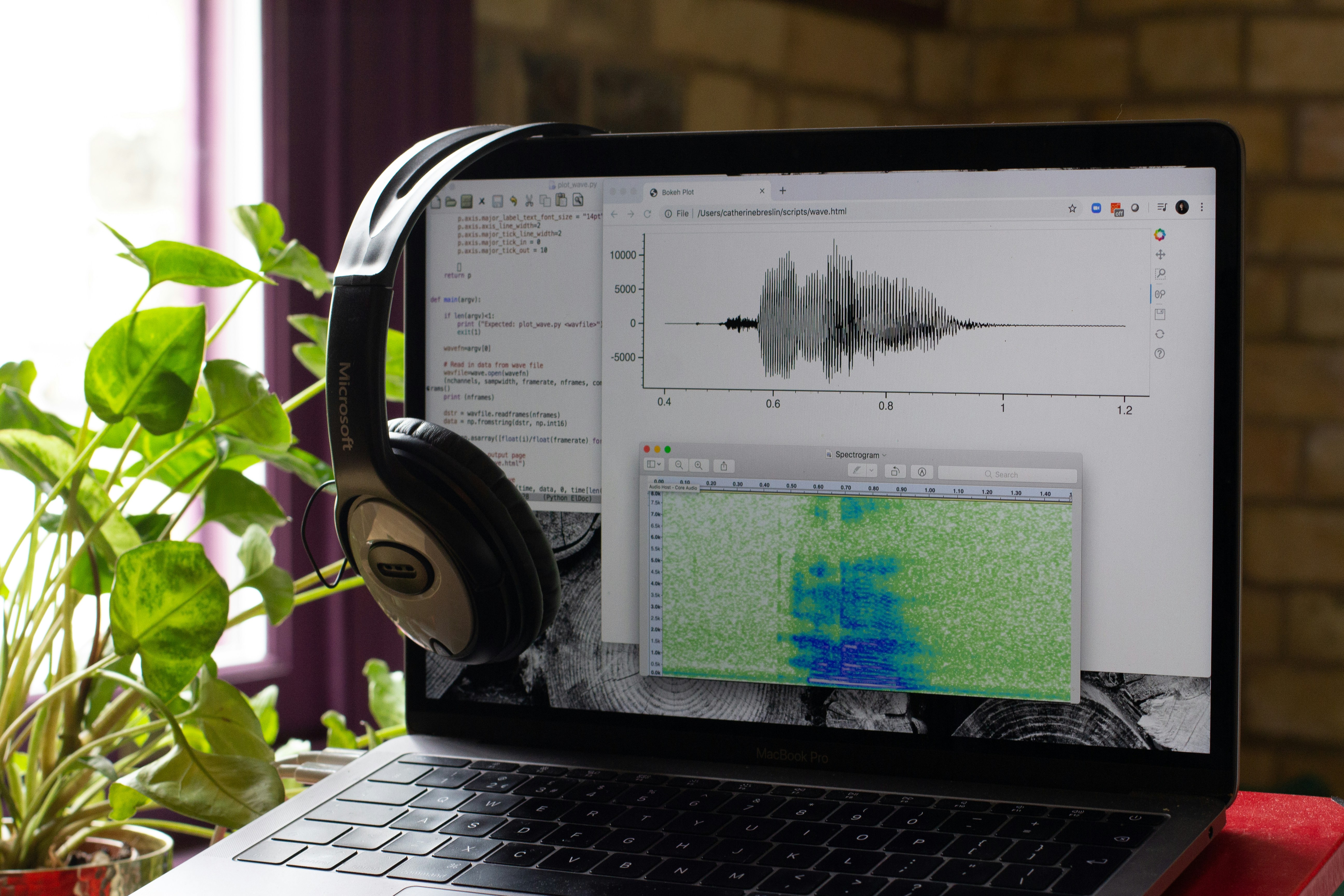
Descubre como los modelos multimodales combinan audio y video para decisiones. Las rutas internas de informacion en AVLLMs permiten inferencia eficiente.

LLMs open-source mejoran sintonía de controladores MIMO acoplados: mayor eficiencia e interpretabilidad en procesos industriales.

Corrección de segundo orden para parches de atribución: mejora la fiabilidad en modelos de lenguaje.

NOVA descubre modelos interpretables de conducción usando regresión simbólica. Logra un 67% de precisión en cambio de carril, superando alternativas.

¿Fuga de información en modelos conceptuales? No siempre es mala. Descubre cómo la fuga benigna puede mejorar la precisión y la intervenibilidad en IA real.