
GLIDE: Inferencia basada en predicciones para evaluar sistemas GenAI
GLIDE: biblioteca Python que combina anotaciones humanas y predicciones de LLM para evaluar sistemas GenAI y agentes sin sesgo, ahorrando costos de anotación.
GLIDE: biblioteca Python que combina anotaciones humanas y predicciones de LLM para evaluar sistemas GenAI y agentes sin sesgo, ahorrando costos de anotación.

Descubre cinco estrategias para reducir costos de inferencia en IA. Optimiza prompts, elige modelos eficientes y reduce tokens de salida.
Descubre cómo los kernels invariantes de árbol garantizan inferencia determinista con resultados bit a bit idénticos, eliminando el desajuste entre entrenamiento e inferencia en LLMs.

Descubre IntAttention: acelera la inferencia de Transformers en edge hasta 3.7x con pipeline entero sin conversiones. Sin pérdida de precisión.
La inyección de ruido secuencial en subespacios evita colapso de precisión en desaprendizaje certificado. Mejora la utilidad del modelo.

Descubre TRINE: motor FPGA adaptativo que acelera inferencia multimodal. Reduce latencia hasta 22.57x con solo 20-21W. Ideal para visión, lenguaje y grafos.

Nuevo método idSCD: identifica datasets de entrenamiento mediante correlaciones semánticas. Supera hasta un 60% a técnicas existentes.

Descubre el gap de inferencia en IA física: memoria limitada pero no ancho de banda. CUDA Graphs muestra un overhead oculto en GPUs rápidas como H100.

¿Los LLMs clínicos son inconsistentes ante cambios en las preguntas? Un estudio mide su estabilidad semántica y propone métricas para evaluarla.

Descubre DynaTree: recuperación de noticias con agentes y árboles dinámicos para alta precisión y frescura en tiempo real.

Descubre cómo los modelos de lenguaje infieren eventos a partir de series temporales usando datos deportivos. Un nuevo benchmark y técnicas de destilación mejoran el rendimiento.

ConSensus mejora la precisión de sensores multimodales un 7.1% usando fusión híbrida multiagente, robusta ante ruido y datos faltantes. ¡Entérate!

MedCoG optimiza el razonamiento médico de LLM con metacognición, logrando 6.2x más densidad de inferencia. Reduce costos y mejora precisión.

Los agentes LLM logran hasta un 79.2% de éxito en desanonimización del Netflix Prize con pistas débiles. Estudio revela riesgos de privacidad.

Descubre cómo las medidas de incertidumbre en tiempo de inferencia se alinean con la incertidumbre humana y mejoran la calibración en grandes modelos de lenguaje.

Descubre CoMem, un novedoso framework que desacopla la gestión de memoria en agentes de IA para reducir la latencia y mejorar el rendimiento en tareas de largo horizonte.
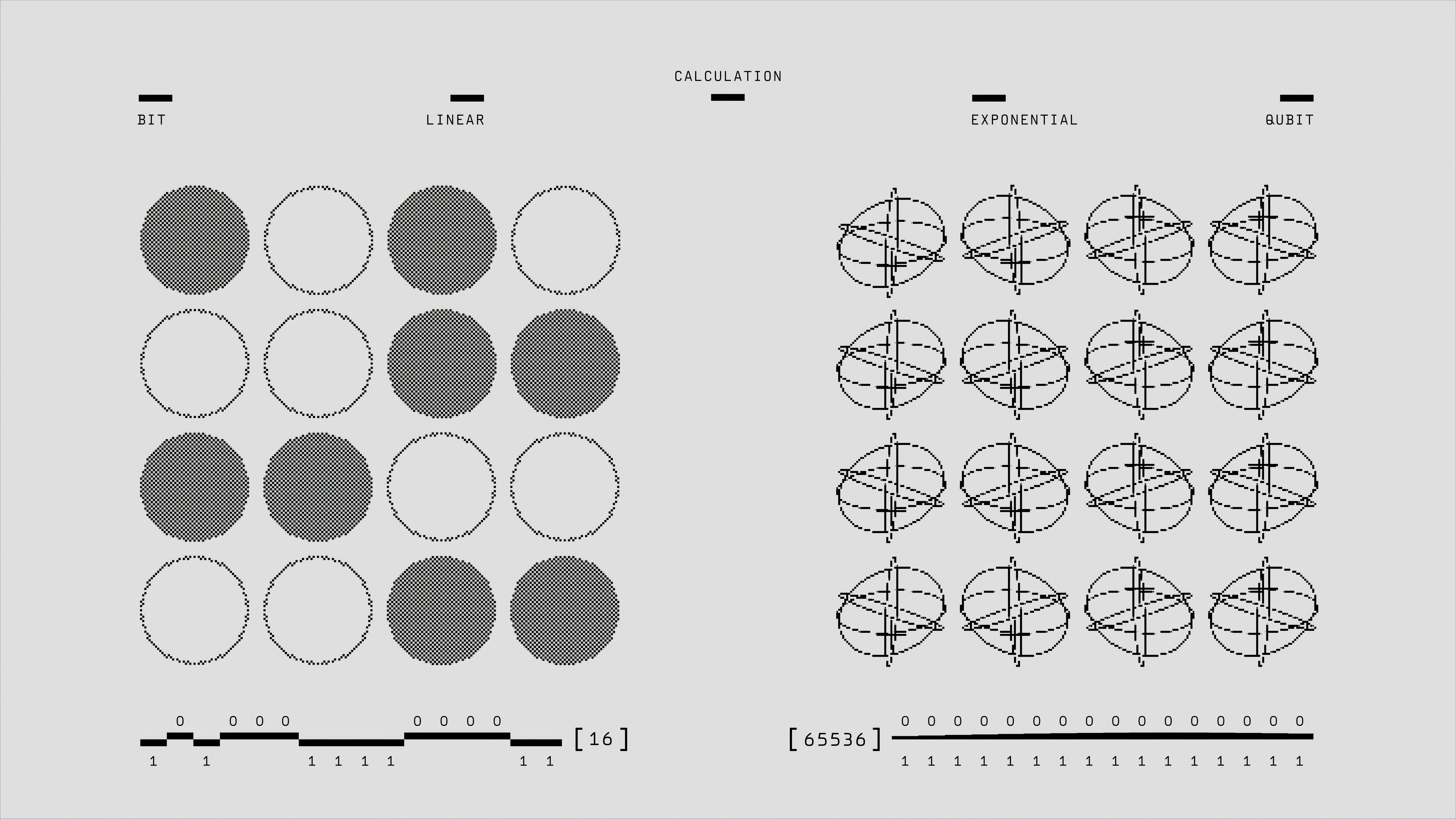
PATHS: temple paralelo para muestreo inicial en alineación de recompensas. Evita modas locales y explora regiones raras de alta recompensa en modelos generativos.

Aprende cómo la inferencia bayesiana escalable con procesos gaussianos resuelve problemas inversos en segundos, superando a métodos de deep learning.

Descubre cómo los embeddings como subespacios capturan jerarquías y composición lógica, superando vectores tradicionales en inferencia y negación.
SITA: annealing escalable que evita divergencias para muestreo molecular eficiente. Lider en alanina dipeptido y tripeptido.