
Optimización de Política de Secuencia Suave
Descubre Soft Sequence Policy Optimization: un nuevo método off-policy que mejora la estabilidad y rendimiento en tareas de razonamiento y codificación para LLMs.
Descubre Soft Sequence Policy Optimization: un nuevo método off-policy que mejora la estabilidad y rendimiento en tareas de razonamiento y codificación para LLMs.
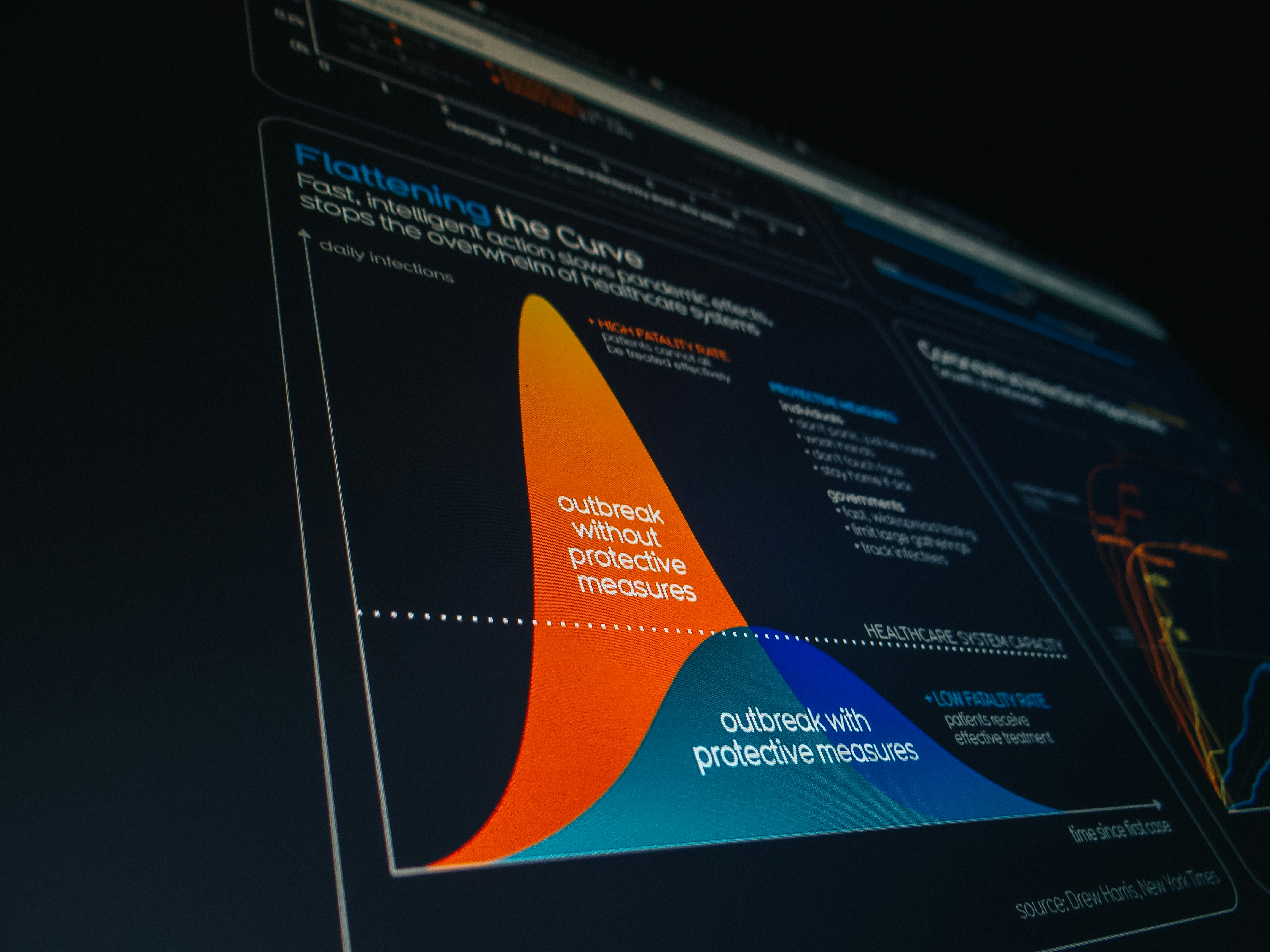
GIPO: optimización de políticas con muestreo por importancia truncado y pesos gaussianos logrando eficiencia y estabilidad superiores en RL post-entrenamiento.

Descubre cómo Fisher-MoE recorta dimensiones intermedias para comprimir modelos MoE al 50%, reduciendo memoria un 45% y acelerando inferencia un 21% sin perder capacidad.

Descubre cómo ATWU mejora el desaprendizaje en LLMs aprendiendo importancia de tokens sin supervisión, logrando equilibrio óptimo entre olvido y retención.

Aprende a construir una línea base de detección de fraude en Python con datos transaccionales. Características conductuales, modelo rápido y explicable. Ideal para fintech.

AISP alinea LLMs en tiempo de prueba usando muestreo de importancia en pre-logits. Logra mayores recompensas que best-of-n sin fine-tuning.

Descubre cómo CondPED-ANOVA estima la importancia de hiperparámetros en espacios condicionales. Ideal para optimizar modelos de IA.

El nuevo algoritmo RT-PG reutiliza trayectorias off-policy para acelerar la convergencia en métodos de gradientes de política, mejorando la eficiencia muestral.

Mejora el algoritmo MADDPG con inferencia de acciones y muestreo por importancia para optimizar la cooperación y exploración en entornos multiagente.

Un portal de socios con certificaciones alinea personas, procesos y tecnología. Mejora eficiencia, reduce riesgos y escala sin costos extra. Descubre cómo con Q2BSTUDIO.

Descubre cómo fusionar noticias largas con predicciones de series temporales usando modelos de recompensa para mayor precisión.
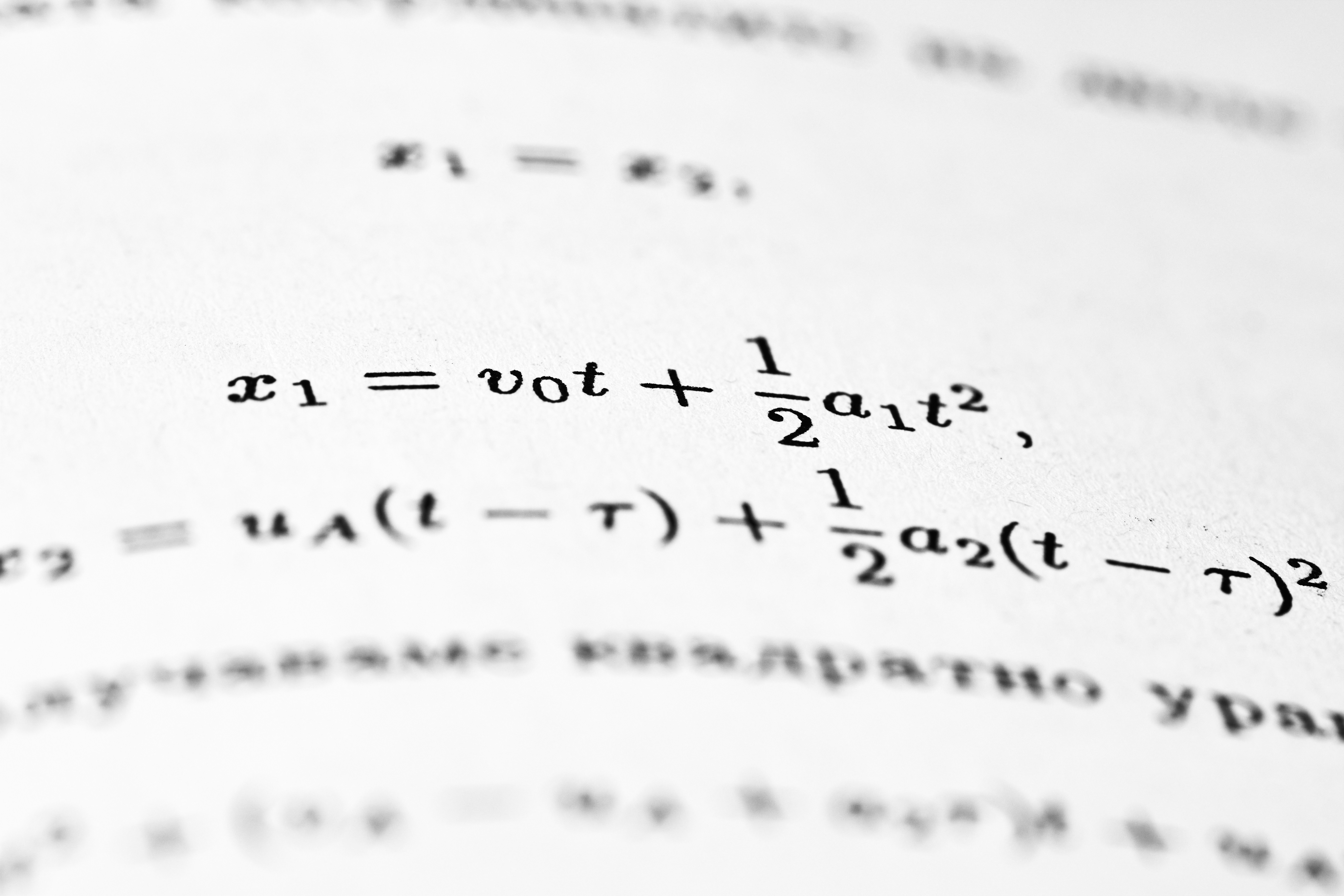
El recocido con semilla Rashomon optimiza la inferencia bayesiana en diseños factoriales, superando multimodalidad y combinando evidencia con incertidumbre.

Mejora la transparencia en optimización de caja negra con IEMSO: métricas inclusivas que explican el proceso de surrogate optimization y aumentan la confianza.

Mejora la precisión al estimar valores Shapley con pocas evaluaciones. ShaplEIG usa diseño bayesiano para selección adaptativa de coaliciones. Ideal para costos.

Aprende cómo GIM, un nuevo método de retropropagación, mejora la localización de circuitos en modelos de lenguaje al tener en cuenta interacciones.

Nueva técnica de aprendizaje off-policy con zero-shot adapta políticas óptimas sin reentrenamiento, usando sucesores y densidades estacionarias. Benchmark en ExoRL y OGBench.

Aprende cómo el método Zero-Shot Off-Policy Learning permite adaptar políticas a nuevas tareas sin reentrenamiento, usando medidas sucesoras y corrección de distribución para una rápida adaptación.

Descubre CRePE, método de poda post-entrenamiento para LLMs que reduce costos sin perder precisión, y PHO que acelera la búsqueda de hiperparámetros.

POPO elimina muestras ineficaces acelerando el fine-tuning de LLM para razonamiento matemático, planificación y geometría visual con menos rollouts.

FedMTFI optimiza el aprendizaje federado heterogéneo con destilación multi-maestro y valores Shapley, mejorando precisión e interpretabilidad.