De grafos a esquemas: validación contrafactual para Text-to-SPARQL
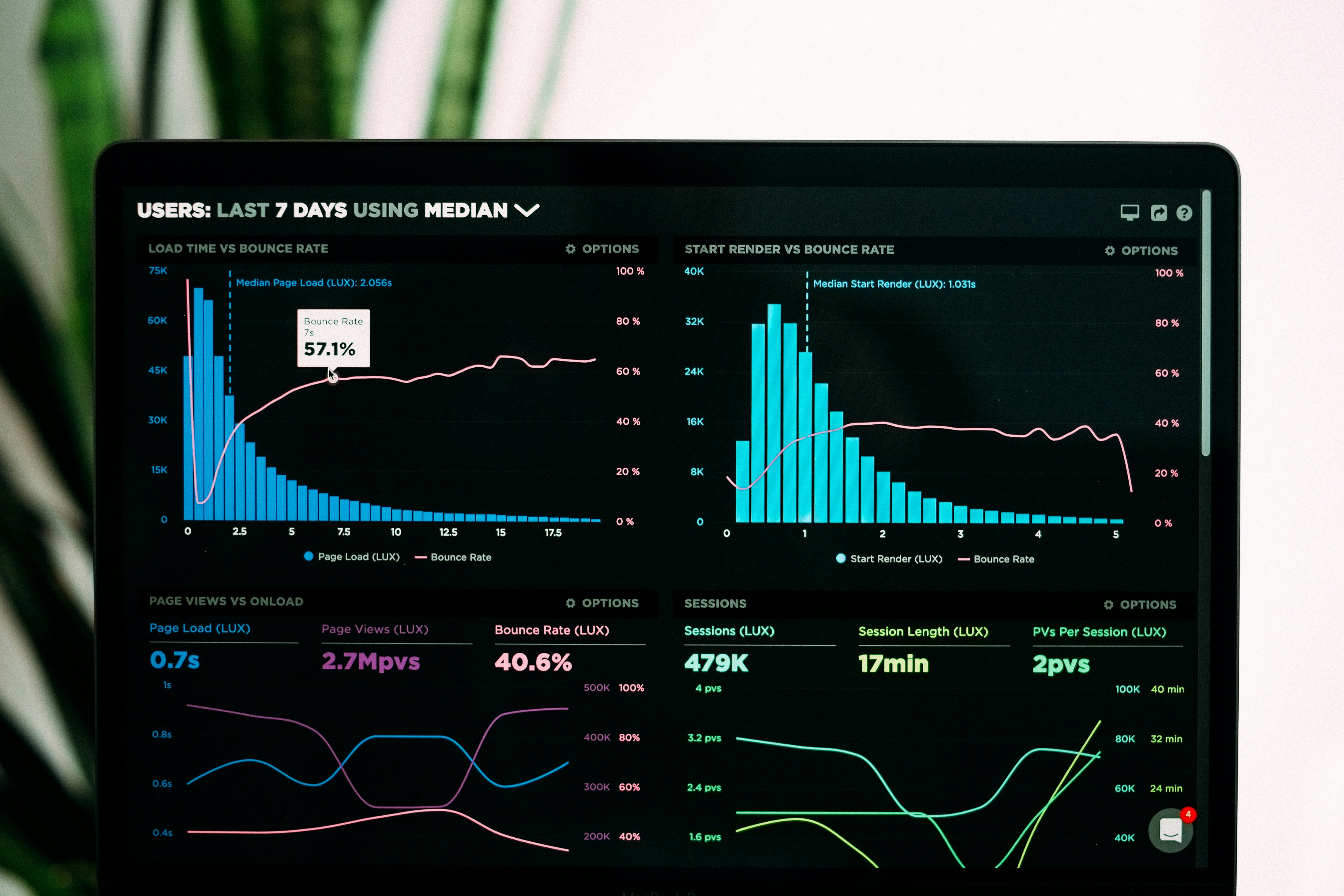
SchemaForge mejora precisión en consultas SPARQL heterogéneas con validación contrafactual. Aumenta accuracy 11.5% en benchmarks clave.
SchemaForge mejora precisión en consultas SPARQL heterogéneas con validación contrafactual. Aumenta accuracy 11.5% en benchmarks clave.

Descubre qué ocurre si el sistema falla al reemplazar Access con una app moderna. Conoce el plan de respuesta de Q2BSTUDIO para recuperación rápida y segura.

Descubre v-HUB, el nuevo benchmark para evaluar cómo los modelos multimodales entienden el humor en videos. ¿Puede la IA captar la comedia visual y sonora?

Evaluamos el rendimiento de seis apps de videollamada con IA. ¿Qué importa más: latencia o capacidad del modelo? Resultados sorprendentes.

Descubre cómo reemplazar tu base de datos Access por una app moderna protege la información confidencial con cifrado, permisos granulares y auditoría completa. Mejora la seguridad.

StreamingVLM revoluciona la comprensión de video en tiempo real: procesa flujos infinitos con solo 8 FPS en un H100, superando a GPT-4O mini. ¡Descubre su arquitectura!

Reemplazar Access por una app moderna transforma la productividad de tu equipo. Descubre los beneficios para cada área y cómo Q2BSTUDIO te ayuda.

Descubre cómo HUVR+SIREN logra mayor fidelidad en terrenos de alta resolución sin almacenamiento extra. Benchmark revela claves.
CoFi mejora la planificación a largo plazo con difusión composicional. Hasta 8 veces menos evaluaciones. Ideal para robótica, video e imágenes.

Descubre R3-CoVR, un marco zero-shot sin entrenamiento que alcanza 91.9% R@1 en recuperación de videos compuestos mediante razonamiento multimodal y reordenamiento.
Descubre por qué la percepción visual supera al razonamiento en preguntas de video. Análisis del modelo Perception First para el desafío VRR 2026.
Descubre MPMWorlds, un dataset de simulaciones físicas con el Método de Puntos Materiales. Comparamos generación de código y difusión de video para inferir y extrapolar dinámicas. ¡Lee más!

Descubre TLG, un sistema que mejora la precisión en razonamiento temporal de video del 46.9% al 71.37% usando anotaciones reales y lógica formal. ¡Aumenta el rendimiento en preguntas de video!

Un enfoque algebraico unifica resultados contradictorios sobre la expresividad de modelos recurrentes: desde autómatas finitos hasta completitud de Turing.

Descubre cómo el Anclaje de Contexto Resonante (RCA) reduce alucinaciones en LLMs sin sacrificar fluidez, una técnica ligera de inferencia.
Descubre cómo identificar regímenes latentes y estructuras causales en series temporales no estacionarias con modelos de Markov y efectos instantáneos.

Descubre cómo el método RPU reduce las alucinaciones en solucionadores de problemas inversos basados en difusión, mejorando la fidelidad de las reconstrucciones. Estudio en FFHQ e ImageNet.

MAVL es un benchmark multilingüe multimodal para traducir canciones animadas. SylAVL-CoT usa audio-video y restricciones silábicas para letras cantables.
DPsurv utiliza fusión evidencial de doble prototipo para predecir supervivencia en imágenes patológicas, ofreciendo interpretabilidad y medición de incertidumbr
Un nuevo modelo generativo identifica componentes independientes en datos de conteo temporal con cambios de régimen. Aplicaciones en microbioma y clima.