
Datos de trayectorias bastan para evaluar políticas en RL offline
Nuevo estudio muestra que los datos de trayectorias bastan para evaluar políticas en RL offline con eficiencia estadística. ¡Descúbrelo!
Nuevo estudio muestra que los datos de trayectorias bastan para evaluar políticas en RL offline con eficiencia estadística. ¡Descúbrelo!

El Horizonte Determinista: ¿Cuándo falla el razonamiento extendido? Descubre por qué delegar en herramientas es clave para alcanzar precisión superior.

Descubre cómo TaskWeave permite a agentes LLM simular dinámicas organizacionales coherentes durante un año usando memoria estructurada. Optimiza la planificación y ejecución en entornos empresariales.

Reduce hasta un 25% el error en predicción de trayectorias con perfil dinámico de horizonte de riesgo. Ideal para conducción autónoma segura.
ClinEnv evalúa LLMs como médicos en un EHR interactivo. Mide decisiones y proceso: el diagnóstico es más fiable que las acciones (0.51 vs 0.17 F1).
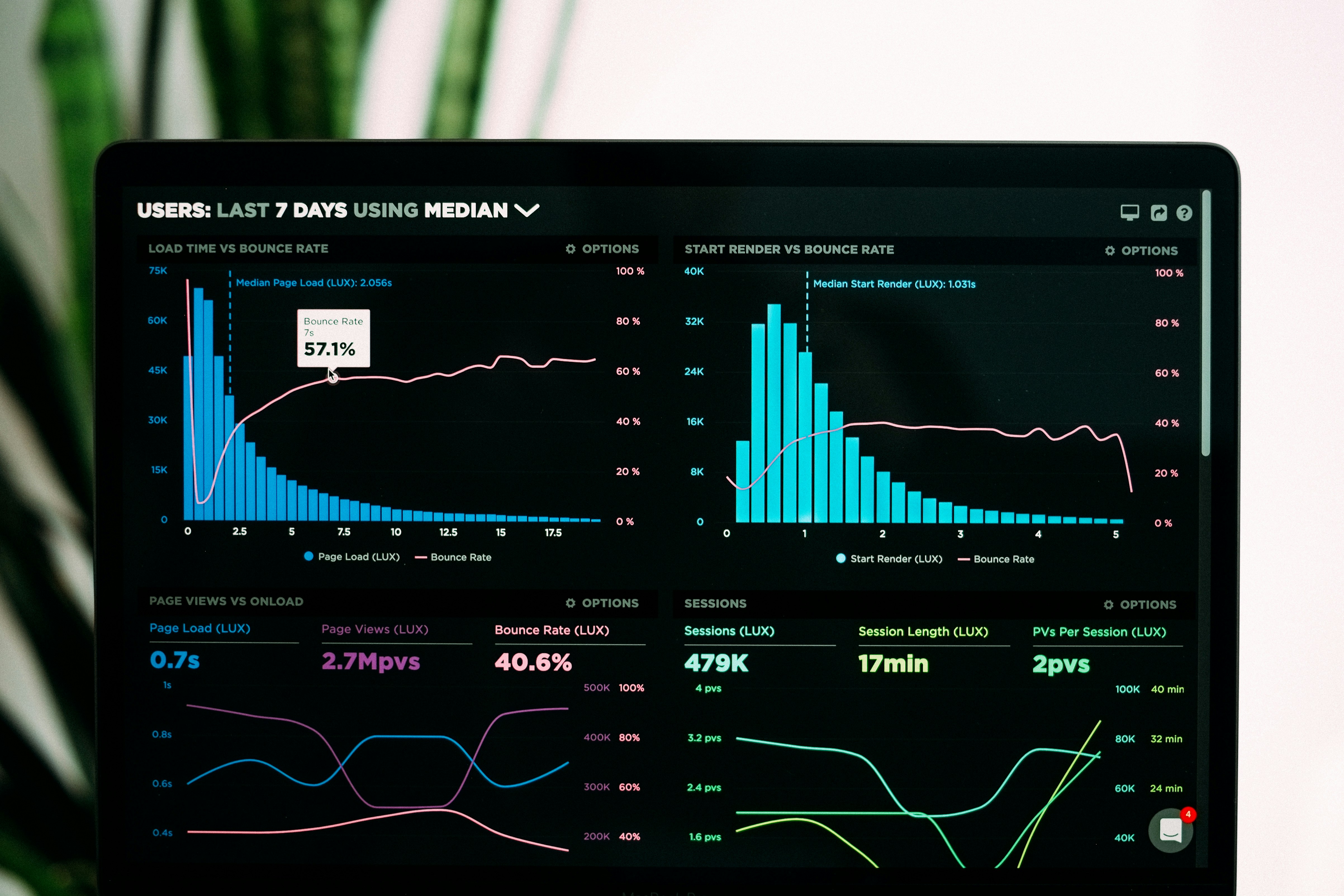
Descubre LongDS-Bench: el benchmark que expone cómo los agentes fallan en análisis de datos prolongados. Solo 48% de precisión. ¡Lee más!

Descubre cómo Survival RL supera el dilema del contraste, logrando 2x a 8x mejor rendimiento en robótica de largo plazo. ¡Auto-supervisado y escalable!