
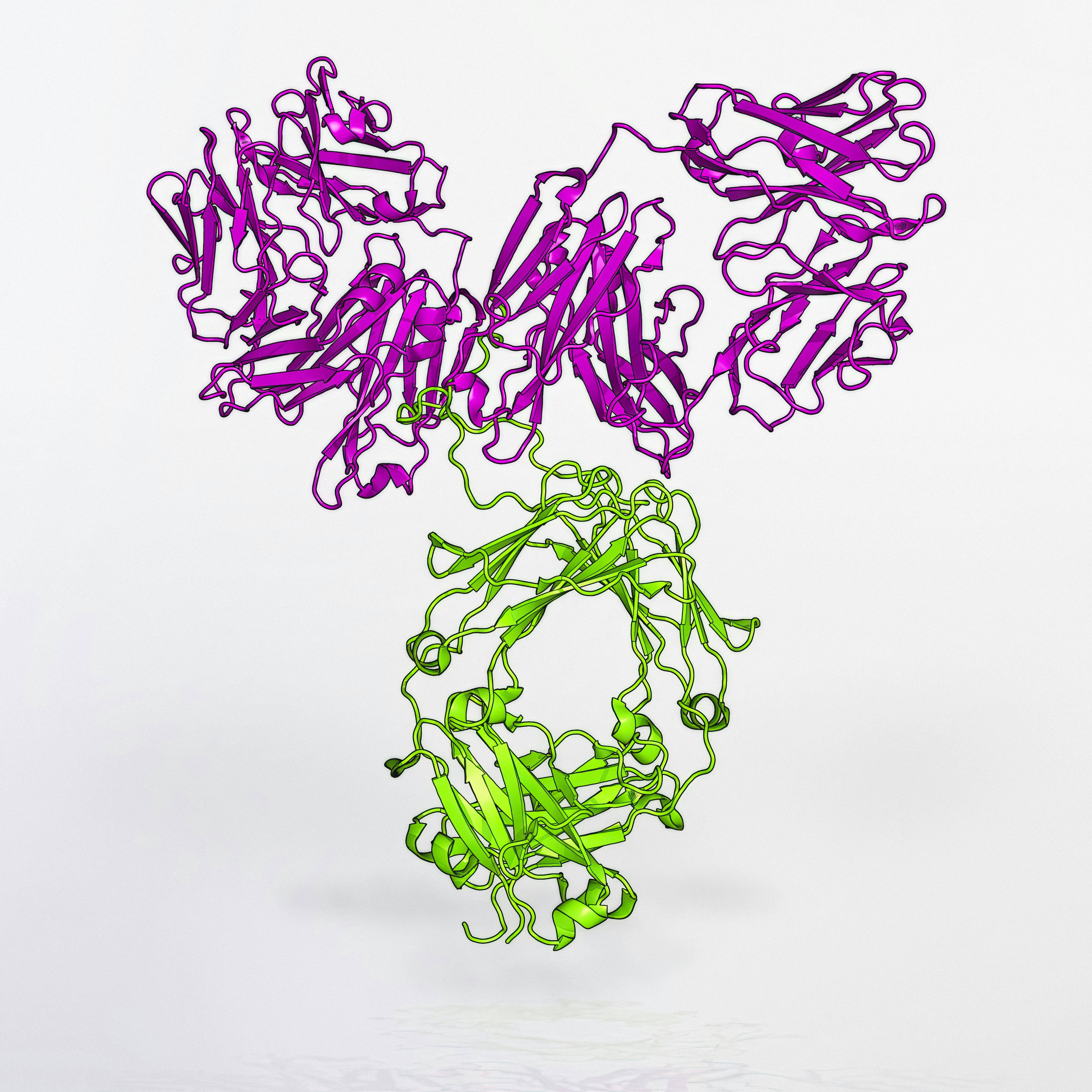
Sangue e Grafi: Enseñando a un modelo pequeño a leer el linaje
Un modelo de solo 4B parámetros supera a los gigantes en puzzles de herencia gracias a ontologías ejecutables. La estructura entrenable es la clave. ¡Pruébalo!
Un modelo de solo 4B parámetros supera a los gigantes en puzzles de herencia gracias a ontologías ejecutables. La estructura entrenable es la clave. ¡Pruébalo!

Aprende a desarrollar un centro de soporte integral que simplifique el acceso a tratamientos, gestione seguros y ofrezca asistencia financiera.

Descubre cuándo autoinformes de LLMs predicen su comportamiento. Estudio revela que Teoría del Comportamiento Planificado supera al Big Five en coherencia.

Descubre cómo ReSum, un nuevo marco de RL, mejora el razonamiento de LLMs un 4% y reduce el largo de las cadenas un 18.6% mediante auto-resúmenes.

IVIE combina LLMs y validación simbólica para generar mundos de ficción interactiva coherentes e inmersivos. Descubre cómo equilibra creatividad y consistencia.

Optimiza el equilibrio entre precisión y cómputo en VLMs con AVIS. Aprende cómo el escalado adaptativo mejora la eficiencia.
Descubre cómo la homología persistente revela estructuras emergentes en sistemas complejos, desde vórtices atmosféricos hasta redes neuronales.

Descubre VQLC, alternativa escalable al clustering para descubrir conceptos en LLMs con alta coherencia.

Descubre LASA, un método de supervisión débil que segmenta bocetos con vocabulario abierto usando atención multi-capa. Mejora mIoU hasta +15.7. ¡Lee más!

¿Crees que más contexto mejora la IA? El verdadero avance es el diagnóstico. Aprende cómo Scarab mantiene la coherencia del código.

Descubre cómo MGAP mitiga las alucinaciones en MLLM corrigiendo la desviación del manifold sin sacrificar coherencia. Método libre de entrenamiento.

Aprende cómo la coherencia hacia atrás estabiliza RNNs, reduciendo errores hasta un 58% y acelerando la convergencia en un 44%. Basado en teoría de cuasi-martingala inversa.

Descubre cómo la autocoherencia en modelos generativos mejora la calidad y detecta fallos. Aprende el principio de control residual para optimizar tu IA.

Nuevo marco cuántico IRAM-Omega-Q regula incertidumbre en agentes adaptativos. Compara órdenes de control y revela impacto en eficacia.
La perplejidad generativa no mide calidad. Aprende por qué las métricas de distribución son esenciales para evaluar modelos de lenguaje.

Descubre cómo C++23 elimina las declaraciones friend en CRTP usando parámetros de objeto explícitos. Mejora la encapsulación y simplifica tu código.

Descubre cómo la corrección de errores cuánticos mantiene viva la información frágil para el machine learning. Aprende los fundamentos para escalar la IA cuántica.

Identifica fallos en modelos de lenguaje mediante firmas a nivel de token: errores comprometidos y persistentes. Aprende a mejorar la detección y autocoherencia.

Descubre cómo la proyección de modelos permite heredar propiedades entre redes feedforward y convolucionales, logrando transfer learning eficiente y competitivo con ImageNet.
Descubre cómo un modelo de deep learning restaura la microvasculatura retiniana en 3D a partir de OCTA, mejorando PSNR y SSIM significativamente.