
Avances en auditoría de privacidad empírica con canarios sintéticos
Descubre cómo los canarios sintéticos mejoran la auditoría de privacidad en LLMs. Aprende a medir memorización y fuga de datos en fine-tuning eficiente.
Descubre cómo los canarios sintéticos mejoran la auditoría de privacidad en LLMs. Aprende a medir memorización y fuga de datos en fine-tuning eficiente.

Descubre cómo una app móvil para equipos de campo se adapta a startups y grandes empresas, ofreciendo escalabilidad, control y automatización sin perder agilidad.
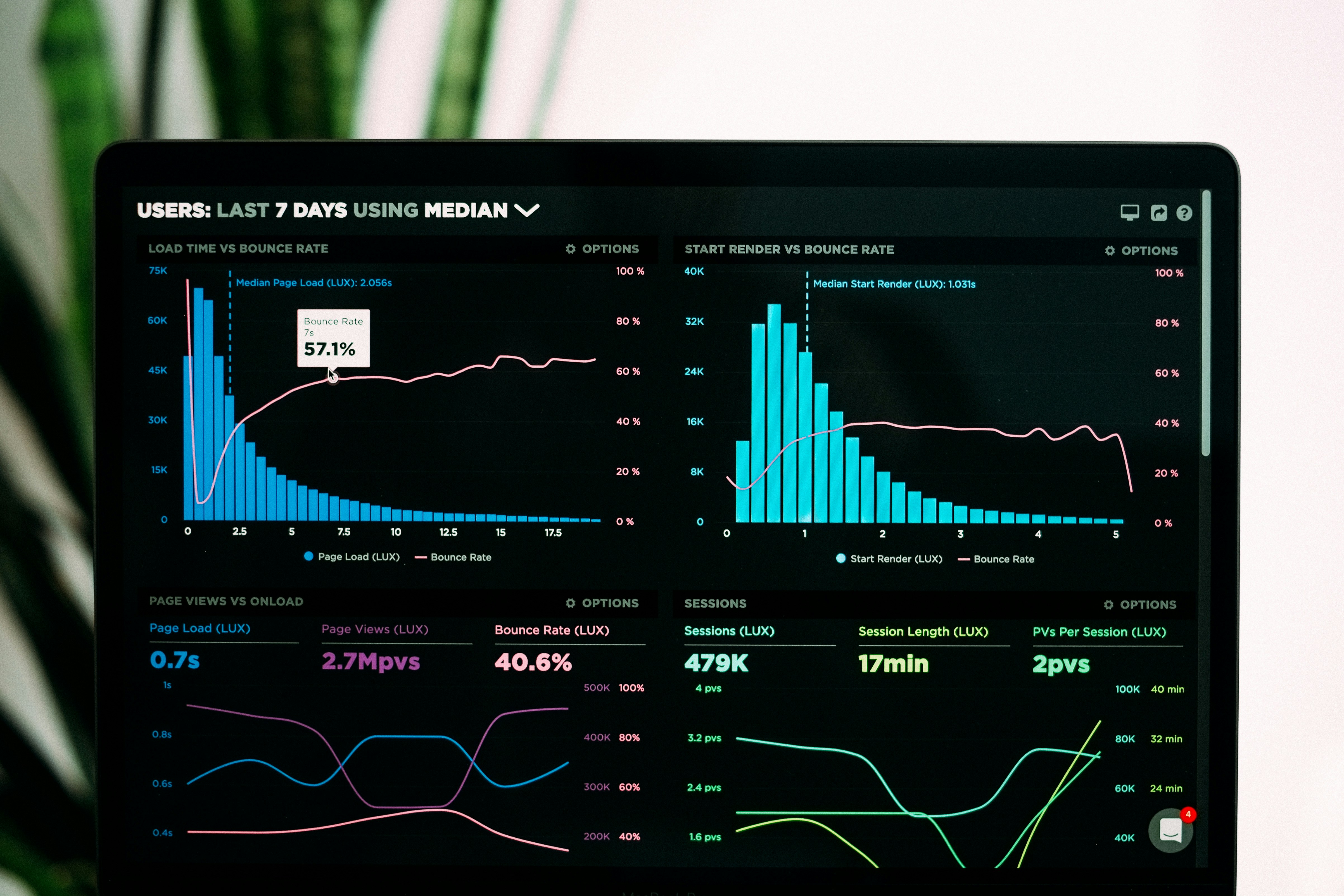
La inferencia estadística secuencial permite monitorear LLMs, detectando alucinaciones, sesgos y cambios de comportamiento. Mejora la confiabilidad.
Descubre el innovador marco de regresión mejorado con LLMs que decodifica emociones continuas desde señales cerebrales fMRI. Léelo en Q2BSTUDIO.

GPT-Micro acelera 400x el descubrimiento de modelos constitutivos, reduce datos un 70% y asegura cumplimiento termodinámico. Ideal para manufactura.

El nuevo método SFF (Smoothed Full Fine-tuning) suaviza el paisaje de pérdida no convexo para optimizar el ajuste fino de grandes modelos de series temporales. ¡Descubre sus beneficios!

DCMDP reformula el RL para LLM corrigiendo la discrepancia train-inference. Mejora el rendimiento en modelos como Qwen-3 incluso con recursos limitados.

Evaluamos cómo la distribución de datos y métodos como LoRA impactan la privacidad en LLM con privacidad diferencial. Claves para proteger datos sensibles.

Descubre cómo destilar modelos de lenguaje entre familias sin compartir tokenizador. Nuevo algoritmo de mapeo de tokens logra mayor eficiencia.
La integración ERP y automatización se adapta a startups y grandes empresas. Mejora precisión, velocidad y control con módulos y cloud. Con Q2BSTUDIO.

La Hipótesis de Alineación Superficial cuantificada: el post-entrenamiento colapsa la complejidad de tareas en LLMs. Resultados sorprendentes en razonamiento y traducción.

Descubre cómo los LLMs muestran una transición de fase al variar la temperatura, generando textos con patrones de ley de potencia como el lenguaje natural.

Descubre cómo la atención en los LLM revela un ritmo de preplan y anclaje que optimiza políticas con aprendizaje por refuerzo granular, mejorando el razonamiento.

Cómo las variables sombra débiles de modelos preentrenados permiten acotar estimaciones con datos faltantes, reduciendo sesgo y mejorando precisión

Acelera el entrenamiento de LLMs con paralelismo de contexto flexible. Logra hasta 2.24x de velocidad incluso con datos heterogéneos.

Primer principio de grandes desviaciones para CNN bayesianas. Un avance teórico sobre covarianza condicional y distribución posterior en aprendizaje profundo.

Descubre cómo CATPO revoluciona el aprendizaje por refuerzo con crítica aumentada, mejorando la precisión en LLMs hasta un 37.5% en benchmarks clave. Optimiza tus modelos.

¿Cómo saber si un modelo de lenguaje genera código fiable? Un nuevo método basado en tres ejes ortogonales mejora la estimación de incertidumbre hasta un 8%.
Descubre cómo el aprendizaje federado permite entrenar grandes modelos de lenguaje preservando la privacidad. Exploramos avances, retos y direcciones futuras en FedLLM.

Descubre cómo Chronos, un modelo de LLMs, predice la carga eléctrica con cero o pocos datos, superando métodos tradicionales. ¡Lee más!