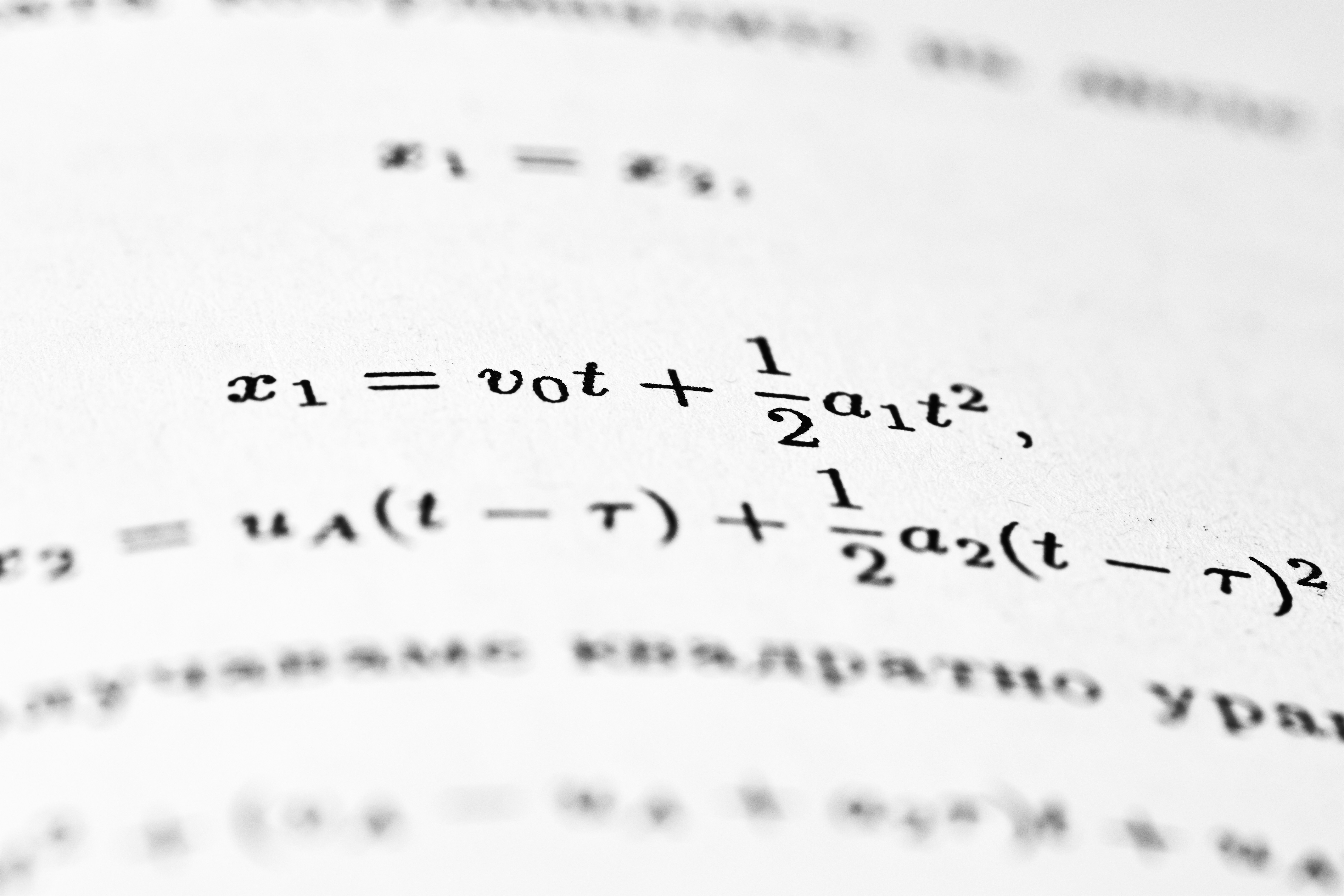
Teorema de Polyak-Ruppert para SA-Adam con momento y precondicionamiento adaptativo
Descubre cómo el teorema de Polyak-Ruppert aplica al optimizador SA-Adam con momento, mostrando que la adaptividad es asintóticamente invisible. Implicaciones
Descubre cómo el teorema de Polyak-Ruppert aplica al optimizador SA-Adam con momento, mostrando que la adaptividad es asintóticamente invisible. Implicaciones

Descubre cómo el ruido en el SGD guía la selección de mínimos planos mediante exploración y congelación transitoria, mejorando la generalización en deep

Aprende cómo el tamaño de lote, momentum y reducción de varianza moldean el sesgo implícito en el descenso más pronunciado con gradiente estocástico.

Aprende cómo los posteriores martingala (SMP) cuantifican la incertidumbre en DNN de forma eficiente, superando a MCMC.

Descubre un nuevo método de optimización sin gradiente para espacios infinito-dimensionales, que solo requiere derivadas direccionales. Ideal para PINNs y

Nuevo teorema de límite central valida la estimación de cuantiles con SGD. Método recursivo para intervalos de confianza robustos.

Analizamos la unificación de dinámicas de aprendizaje y generalización en la ley de escalado de Transformers. Descubre fases de transición y leyes de potencia.

Descubre cómo la inyección de ruido simple en parámetros supera a técnicas complejas en SGD. Mejora el entrenamiento y generalización de redes neuronales con estrategias ligeras.

Aprende a diseñar un denominador determinista para SGLD localizado que evita el cambio de media y mejora la precisión, usando proxy score y cuantiles empíricos.

Aprende cómo la dimensión fractal de Fourier predice la generalización de redes neuronales sin datos de validación. Nueva métrica basada en frecuencia.

Descubre cómo un nuevo análisis de convergencia revela el verdadero impacto de la topología de red en el rendimiento del SGD descentralizado. Te sorprenderá.
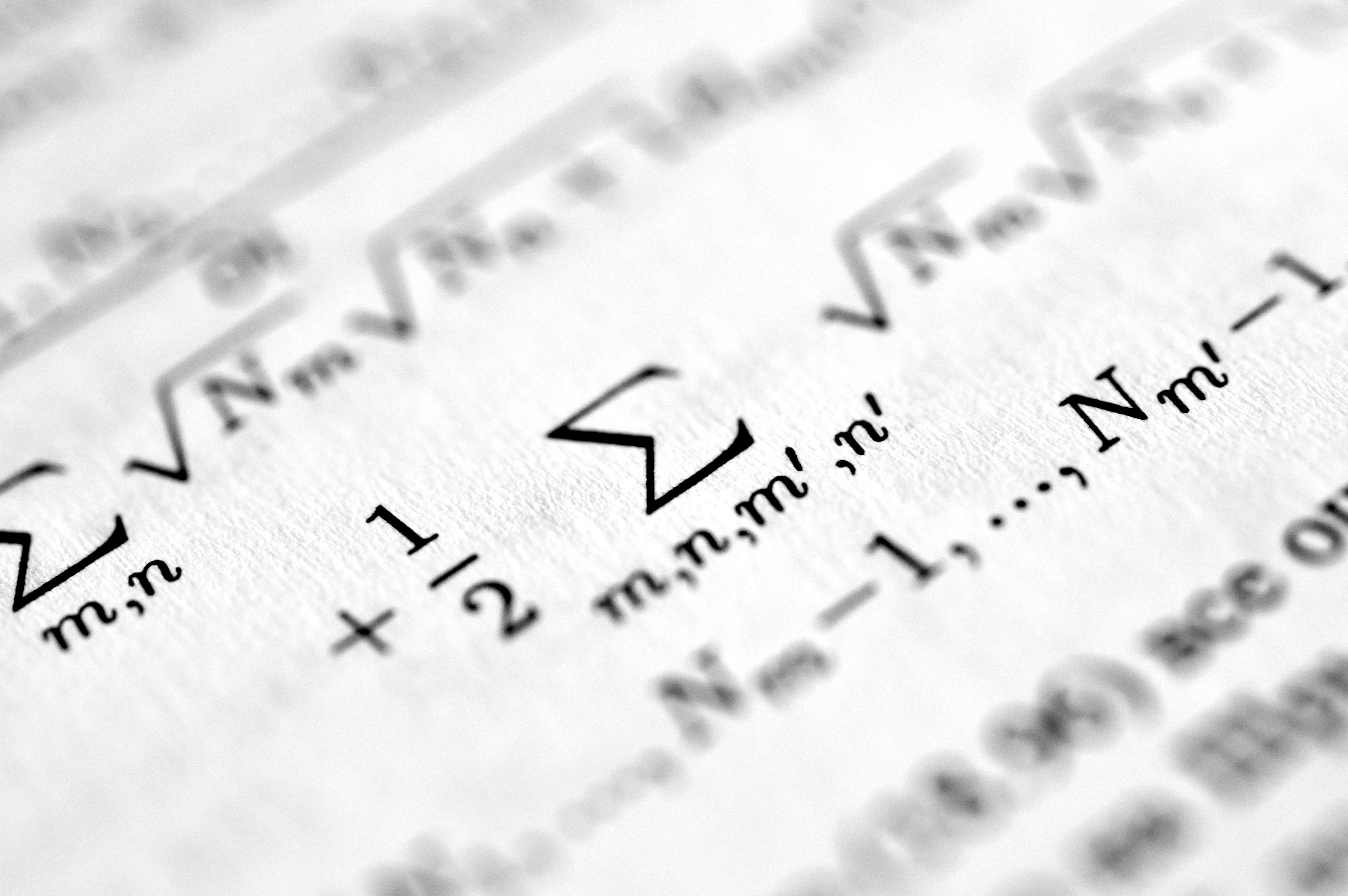
Descubre OptMuon, optimizador con momento ortogonalizado y control adaptativo en bucle cerrado. Logra tasas óptimas incluso sin ruido. Ideal deep learning.

Descubre cómo SVRG se relaciona con la corrección posterior bayesiana para acelerar el entrenamiento. Nuevas extensiones tipo Newton y Adam optimizan tu modelo.

Descubre cómo el análisis de campo medio explica el entrenamiento de autoencoders no lineales con cuello de botella y su convergencia al óptimo.
Descubre las fórmulas de interpolación de kernel de segundo orden: incorporan curvatura, ruido de gradiente estocástico y momentum para mejorar predicciones en ML.

MG-ADSGD acelera la optimización descentralizada con comunicación eficiente, logrando la mejor complejidad comunicacional para problemas fuertemente convexos.

Descubre cómo las neural ODEs unifican modelos dinámicos y deep learning, con teoría de campos medios para entrenamiento en alta dimensión.
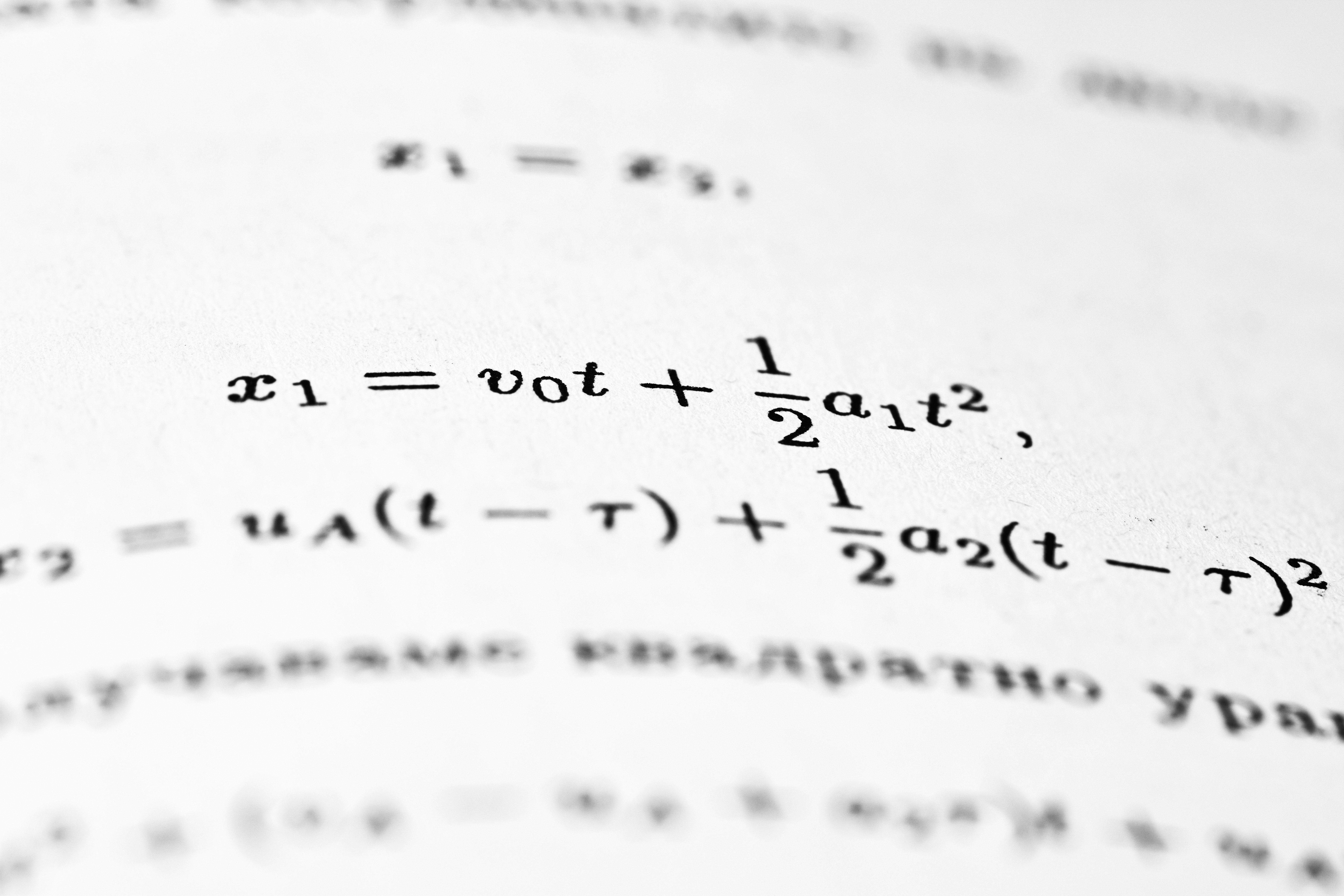
Descubre cómo las envolventes deterministas corrigen el sesgo en SGLD domesticado, mejorando la estabilidad sin distorsionar el gradiente.

Optimiza la dinámica de Fokker-Planck con campos gauge no reversibles, Hamiltonianos supersimétricos y aprendizaje de fuerzas finitas mediante actor-critic.

Descubre DP-MacAdam, un mecanismo que combina recorte y momentum adaptativos para entrenar modelos con privacidad diferencial y mayor utilidad.