
Análisis Graphop de GNN en Grafos Dispersos: Generalización y Aproximación
Descubre un enfoque unificado de graphop analysis para estudiar la generalización y aproximación universal de redes neuronales en grafos dispersos y densos.
Descubre un enfoque unificado de graphop analysis para estudiar la generalización y aproximación universal de redes neuronales en grafos dispersos y densos.

Un modelo de IA del MIT y Mass General Brigham identifica riesgo de violencia doméstica en historiales médicos, años antes de que se denuncie. ¿Es seguro?

Descubre cómo nuestro modelo de detección de suplantación reduce un 25.7% el error al eliminar el sesgo del hablante, sin usar etiquetas de identidad.
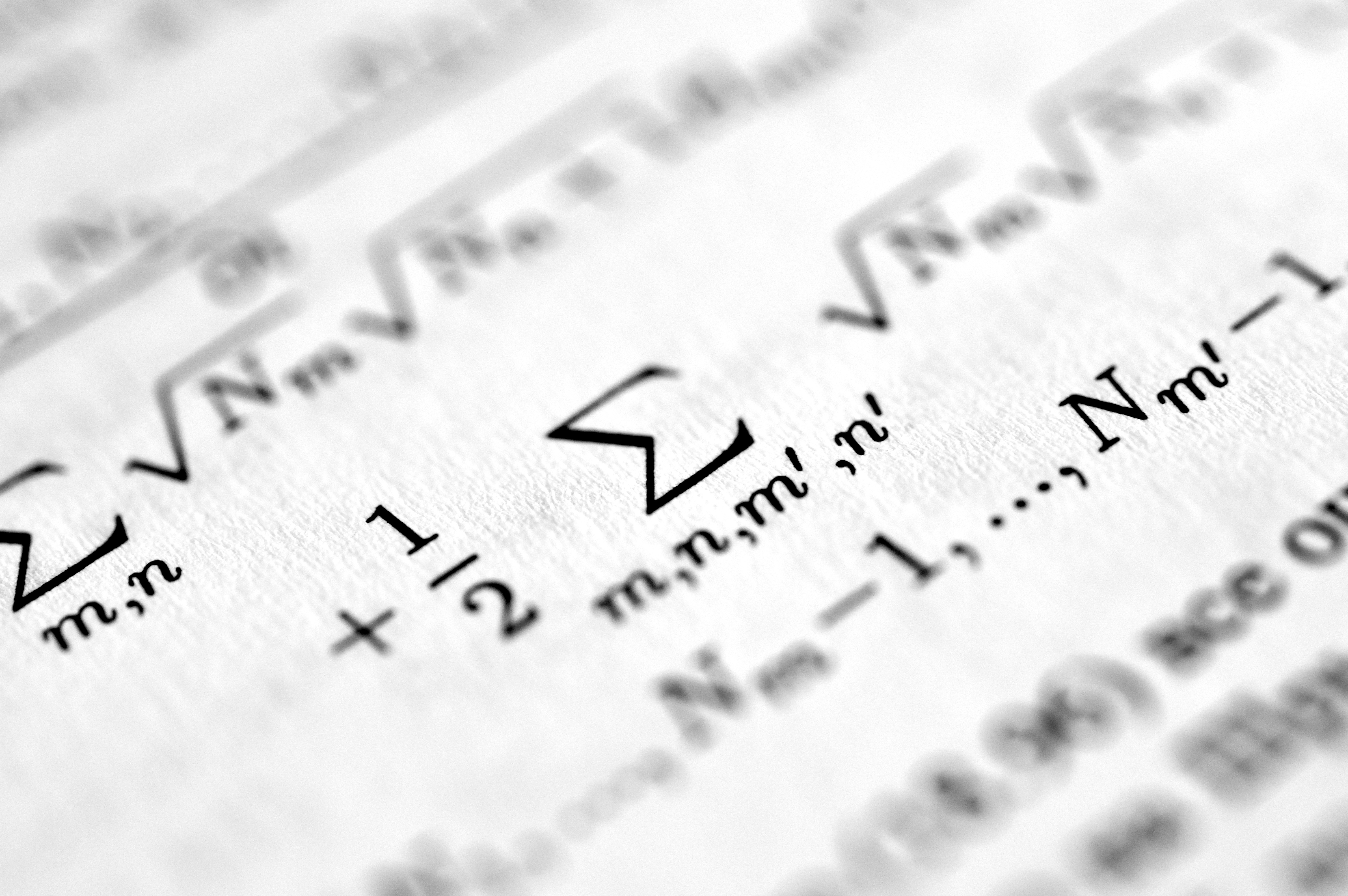
Aprende cómo la geometría de características aprendidas mejora la generalización en mínimos cuadrados no lineales, reduciendo la dependencia de parámetros.

Mejora la eficiencia de los FNO usando puntos de red rango-1 y cruz hiperbólica: menos parámetros, menos muestras, más precisión en PDEs.
Descubre las curvas de error de generalización en regresión kernel con decaimiento de potencia y su impacto en redes neuronales anchas.
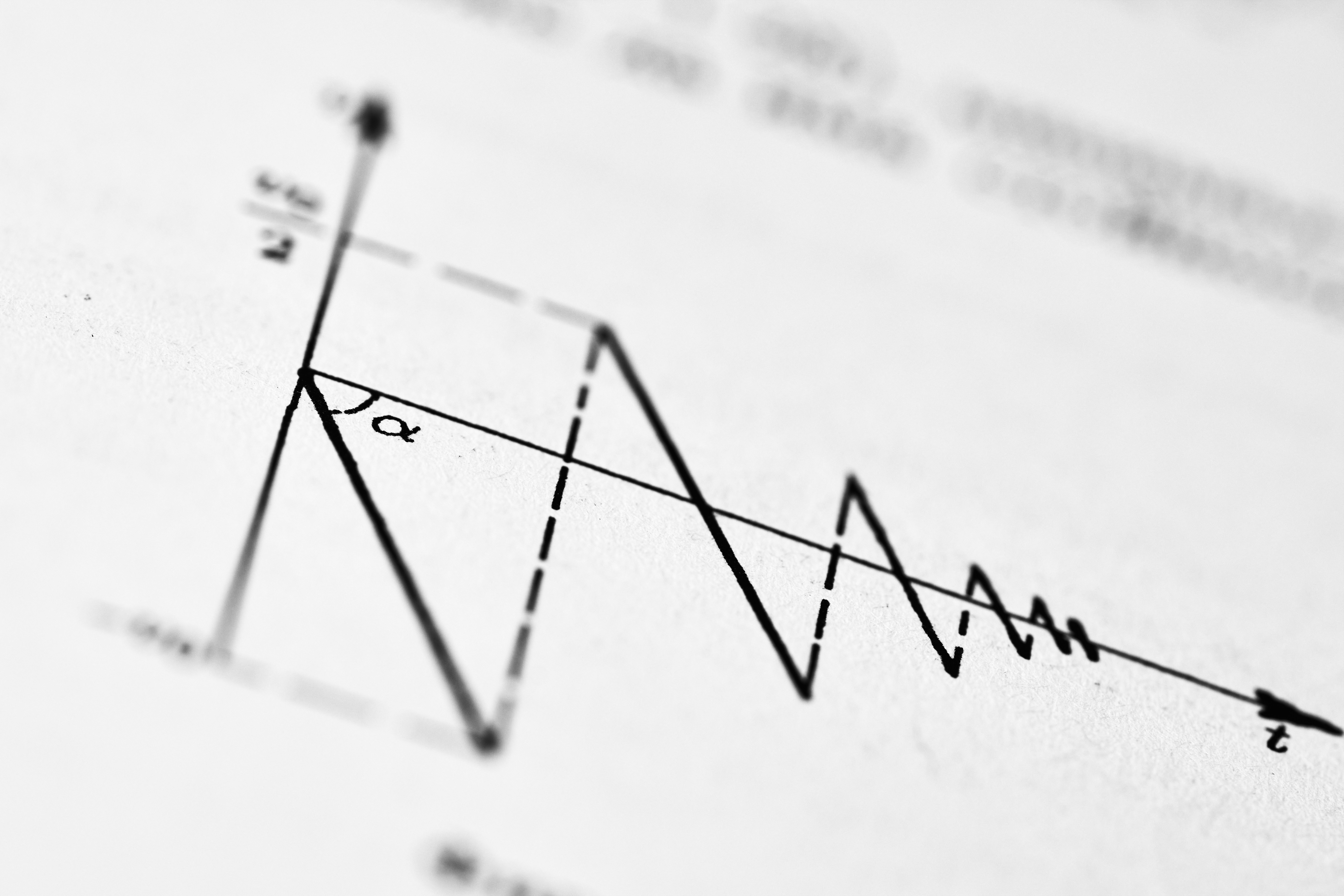
Descubre cómo las predicciones afectan su propio resultado. Analizamos el equilibrio entre cambiar el mundo y aprender de él con nuevos límites de generalización.

Descubre GEAR-VLA, el marco VLA que logra un 90% de éxito en agarre universal con objetos no vistos. Representaciones geométricas unificadas para robots.

Descubre cómo el estudio PRIME revela que la IA aprende a explotar recompensas proxy antes de hackear, ofreciendo una señal temprana de desalineamiento.

Descubre cómo el ajuste secuencial ofrece una nueva visión sobre el sesgo espectral en redes neuronales, más allá del análisis de Fourier tradicional.

AxisGuide mejora la manipulación robótica al visualizar coordenadas de acción en imágenes RGB. Aumenta el rendimiento y la generalización en tareas de recogida.

Descubre cómo GD y SGD alcanzan tasas óptimas de generalización en redes ReLU profundas, con resultados minimax comparables a kernels.

Las redes profundas entrenadas con gradiente logran rendimiento óptimo de generalización, comparable a kernel. Un avance clave.

Descubre cómo descompilar Transformers a RASP revela algoritmos interpretables. Un método innovador para entender la generalización de longitud en IA.

Descubre cómo el descenso de gradiente con pasos grandes opera en el borde de estabilidad, logrando convergencia no monótona y mejorando la generalización.

El redondeo determinista perjudica la generalización de GD y SGD; el estocástico introduce dependencia dimensional inesperada.

Nuevas cotas de generalización para aprendizaje cuántico: privacidad y estabilidad van de la mano. Descúbrelo aquí.

Descubre cómo la diversidad de tareas de entrenamiento mejora el aprendizaje en contexto en transformers lineales. Un análisis teórico con subespacios de baja dimensión.

Descubre cómo la estabilidad L_p genera límites de generalización robustos con pérdidas pesadas, superando diferencias acotadas.

ADIGen genera contrafactuales debiasados e invariantes automáticamente. Aprende cómo su robustez doble mejora la toma de decisiones bajo intervenciones complejas.