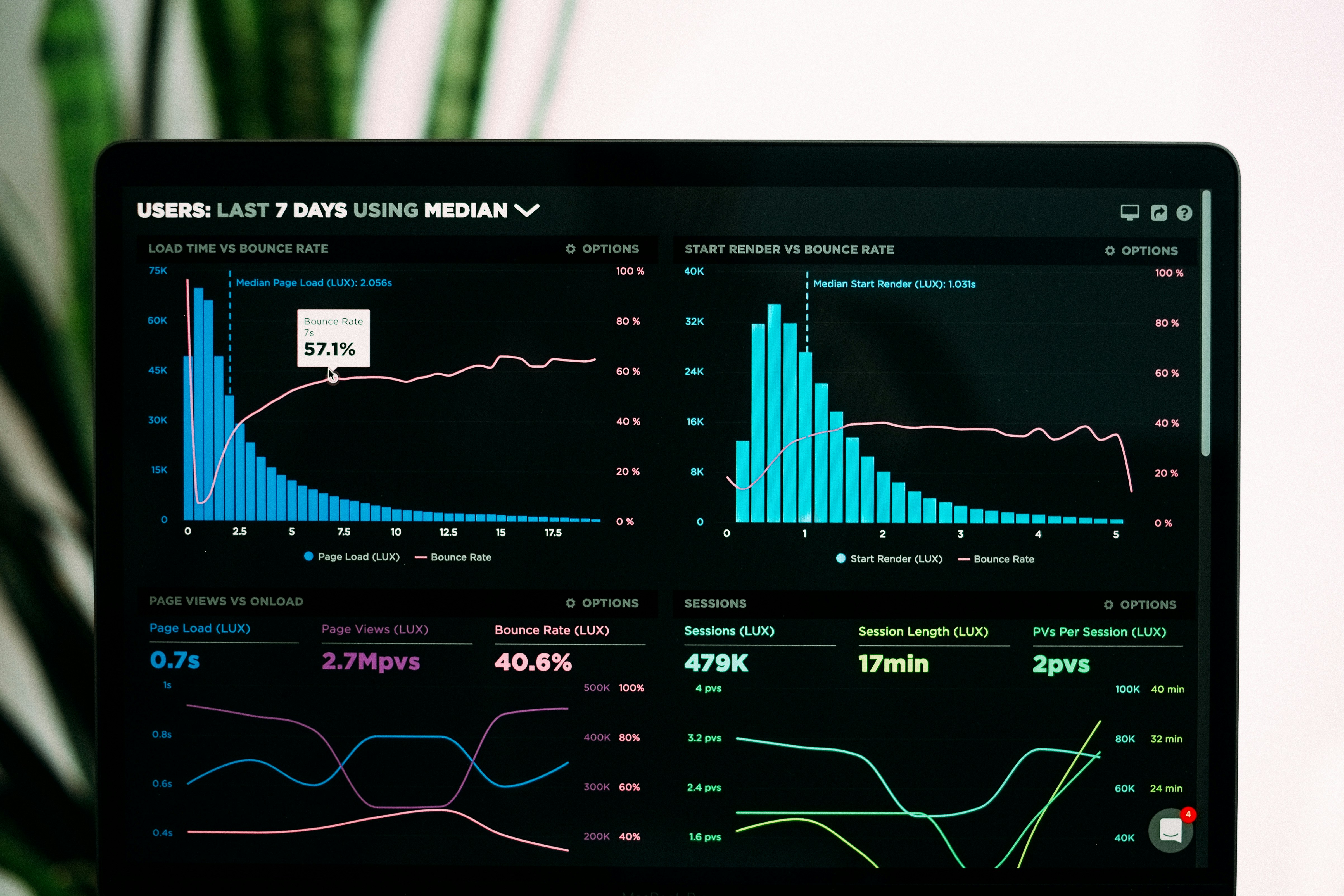
Pushdown queries: 5x menos latencia, 160x menos memoria
Descubre cómo las consultas pushdown reducen la latencia de API hasta 5x y el consumo de memoria 160x frente al filtrado en memoria. Resultados de benchmark.
Descubre cómo las consultas pushdown reducen la latencia de API hasta 5x y el consumo de memoria 160x frente al filtrado en memoria. Resultados de benchmark.
DataShield identifica eficientemente muestras que degradan seguridad en el ajuste benigno de LLMs. Protege tus modelos con esta innovadora solución.

Nuevo método bayesiano que combina filtrado de Kalman y selección de modelos para dinámicas neuronales, mejorando incertidumbre y escalabilidad. ¡Descúbrelo!

Detecta texto generado por IA con control de falsos descubrimientos usando filtrado knockoff. Sin reentrenar, con garantías estadísticas.

Descubre cómo el enmascaramiento de observaciones obsoletas afecta a los agentes de búsqueda. Aprende cuándo mejora y cuándo empeora el rendimiento.
WaveFilter mejora el rendimiento de LLMs de difusión en contexto largo mediante filtrado guiado por wavelets del caché KV.

El servicio de trampas para GTA Atlas Menu fue hackeado: datos de miles de usuarios expuestos y acusaciones de espionaje. Conoce los detalles.

Descubre los fundamentos de la seguridad Sandbox: aislamiento, filtrado de syscalls, segmentación de red, límites de recursos y monitoreo. Crucial para agentes de IA y contenedores.

El creador de Borderlands, Randy Pitchford, publicó imágenes de un supuesto Google Pixel Watch 5 hallado bajo el agua. ¿Filtración o casualidad?
Descubre SAGE, el innovador gate que optimiza la memoria de LLMs agenticos: reduce costos de API 3.4x y latencia 2.5x manteniendo calidad.

Nuevo marco híbrido CNN-CodeBERT detecta filtraciones de credenciales con 93% de recall y reduce alertas falsas en 33%

Descubre cómo HERec, un nuevo marco hiperbólico, rompe las burbujas de información al equilibrar exploración y explotación, mejorando la diversidad en tus recomendaciones.

La brecha de consistencia dinámico-probabilística en modelos caóticos se resuelve con KAFFEE. Un marco de filtro de Kalman mejora la predicción.

ZAPS-DA: reduce hasta 21x la vibración en acciones sin retardo ni filtros. Probado en MetaDrive y Webots. ¡Mejora el control continuo en RL!

Descubre cómo las capas probabilísticas bayesianas mejoran la memoria en modelos de secuencias, reduciendo incertidumbre y aumentando robustez más allá del entrenamiento.

Descubre por qué la memoria recurrente lineal es efectiva en RL parcialmente observable. Justificación teórica con filtros lineales y HMM.

¿Tu bot antispam de Telegram falla? Descubre los 5 niveles de spam que no detecta y cómo evitarlos.
<meta name="description" content=Descubre por qué los mejores ingenieros de software son rechazados incluso antes de leer su currículum. Errores clave y cómo evitarlos para destacar en tu búsqueda laboral.>
Aprende técnicas clave de filtrado de datos para entrenar modelos de lenguaje con mayor precisión y eficiencia.
<meta name=description content=California demanda a 23andMe por filtración de datos de salud en 2023. Conoce los detalles de la demanda y sus implicaciones para la privacidad genética.>