
Agentes de código vs generadores de código: ¿cuál es la diferencia?
Descubre la diferencia clave entre agentes de código y generadores de código. ¿Cuál acelera tu desarrollo? Aprende cuándo usar cada uno para ahorrar tiempo.
Descubre la diferencia clave entre agentes de código y generadores de código. ¿Cuál acelera tu desarrollo? Aprende cuándo usar cada uno para ahorrar tiempo.
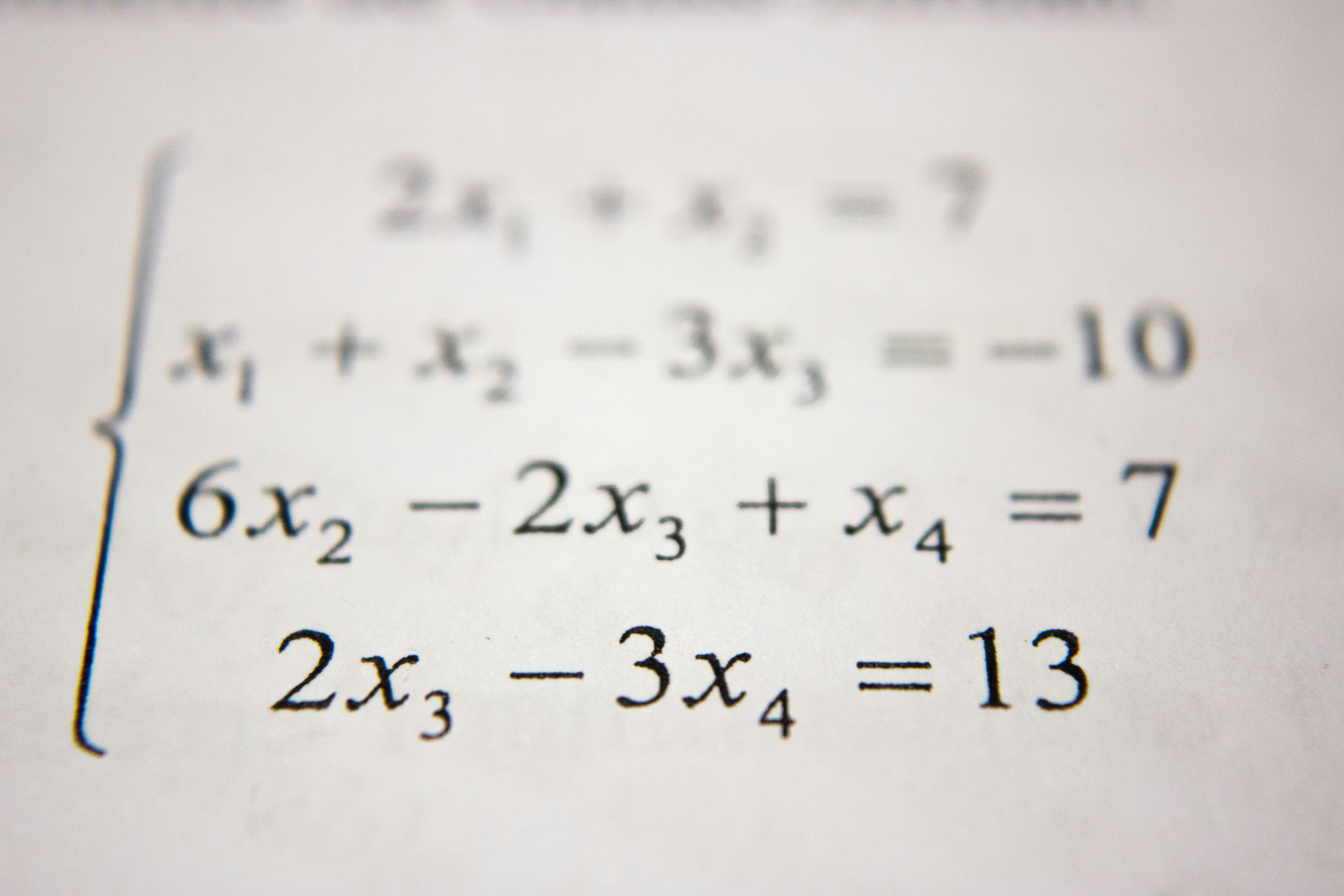
Descubre YAQA, el algoritmo de redondeo adaptativo que reduce el error de cuantización un 30% sin sobrecarga. Preserva la distribución del modelo original.

Descubre cómo entrenamiento condicionado por camino reescala redes ReLU para acelerar aprendizaje. Enfoque geométrico optimiza kernels y mejora inicialización.

Descubre Proof-Refactor, un marco agéntico que refactoriza pruebas formales generadas por LLMs para hacerlas más legibles y modulares, sin enfocarse solo en la longitud.

Descubre SDPLR+: resuelve SDP con millones de variables usando límites de suboptimalidad y bajo rango. Más rápido y escalable.

Descubre cómo el nuevo modelo FacRNN desenreda dinámicas neuronales latentes para una interpretabilidad sin precedentes en neurociencia computacional.

Algoritmo SNMPBB: gradiente no monótono para NMF simétrica. 6x más rápido que alternativas y superior en clustering de grafos. ¡Optimiza!

Descubre cómo L2G-Net revoluciona las GNN espectrales con factorizaciones de Cauchy, escalando a grafos grandes con pocos parámetros.
Descubre SG-NTF, un innovador método de factorización de Tucker guiado por espectro para completar tensores de alta dimensión e incompletos con eficiencia paramétrica.

Descubre CORE-MTL, el nuevo enfoque de representaciones causales ortogonales que mejora la generalización en aprendizaje multitarea, reduce interferencias y supera métodos existentes.

Descubre cómo el modelo bayesiano no negativo (BNRM) mitiga el hackeo de recompensas en RLHF, mejorando la robustez y la interpretabilidad de los modelos de lenguaje.
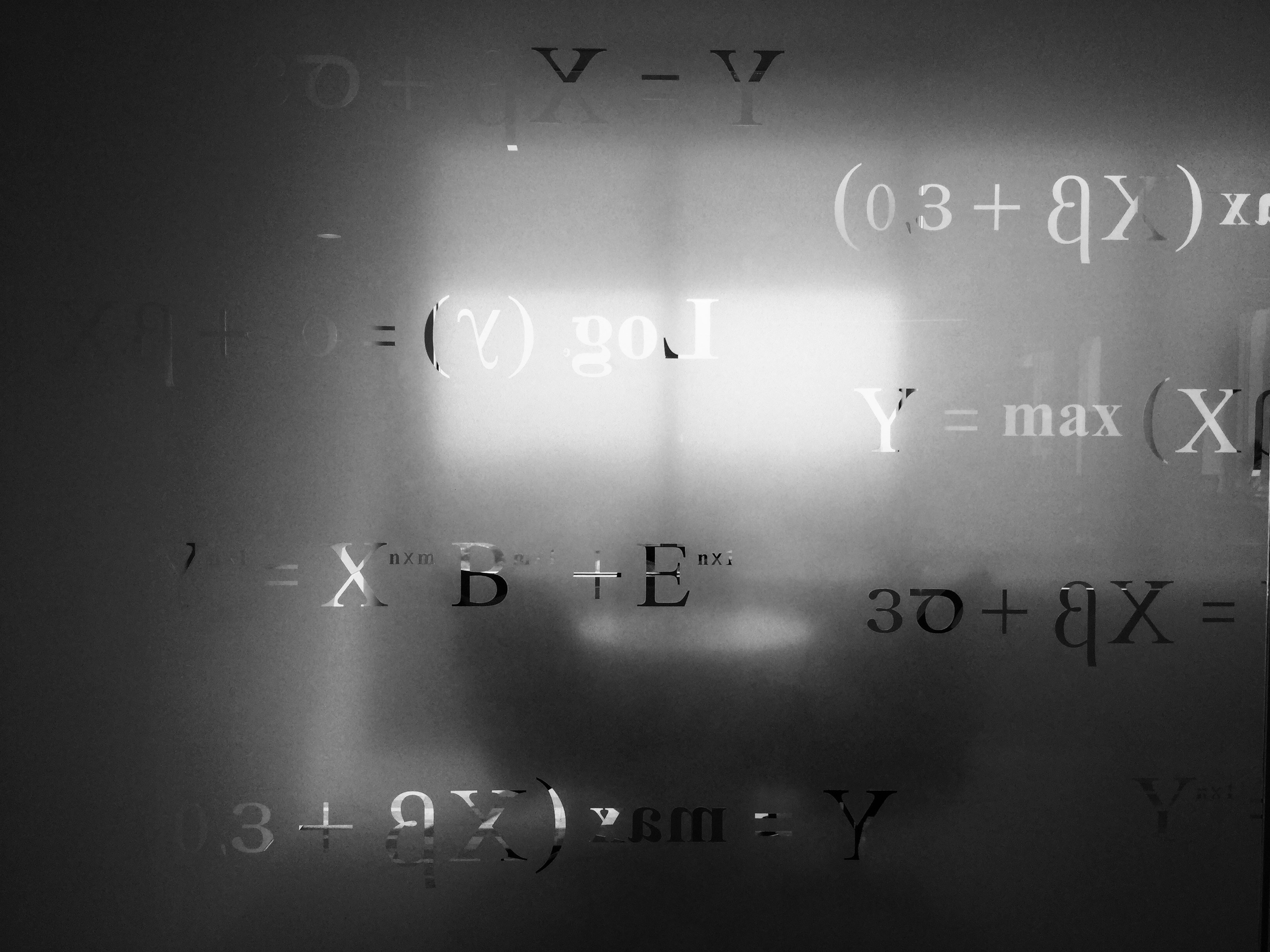
Descubre cómo las divergencias de Bregman distribuyen el error de aproximación espectral en optimizadores Kronecker y la propuesta de un optimizador adaptativo.

Descubre cómo el método EGGROLL entrena redes neuronales de picos sin gradientes, logrando un 79.21% de precisión y 2.23x más rápido en hardware neuromórfico.