
STaR-DRO: Reponderación Tsallis para predicción estructurada robusta a grupos
STaR-DRO optimiza la predicción estructurada con LLMs, mejorando el F1 en +14.46 y reduciendo la pérdida grupal. Descubre cómo supera al DRO tradicional.
STaR-DRO optimiza la predicción estructurada con LLMs, mejorando el F1 en +14.46 y reduciendo la pérdida grupal. Descubre cómo supera al DRO tradicional.

¿Código generado por IA en tu repositorio? HybridCodeAuthorship es el benchmark definitivo para detectarlo. ¡Descubre cómo!

HalluJudge detecta alucinaciones en revisiones de código con IA. Con F1 de 0.85 y bajo coste, alinea con preferencias de desarrolladores. ¡Mejora la confianza!
Mejora la detección de nodos raros en clasificación jerárquica multi-etiqueta con pérdida ponderada. Aumenta el recall hasta 5x y optimiza tus modelos.

Mejora la extracción de frases clave en documentos largos con expansión de atención. Resultados F1 superiores sin LLMs costosos.

Mejora la detección de fraudes con CFA: supera modelos individuales en AUC-ROC, AUPRC y F1. Ideal para datos desbalanceados.

Alinea sensores IMU y texto con entrenamiento contrastivo y prototipos optimizados para lograr 73% de precisión en HAR zero-shot.

Marco de evaluación para detección de deriva de conceptos. Nuevas métricas y protocolos. Resultados de benchmark en 7 datasets.

Descubre cómo combinar datos sintéticos con solo un 20% de datos reales iguala y mejora la detección de grietas en mampostería con CNN. ¡Resultados sorprendentes!
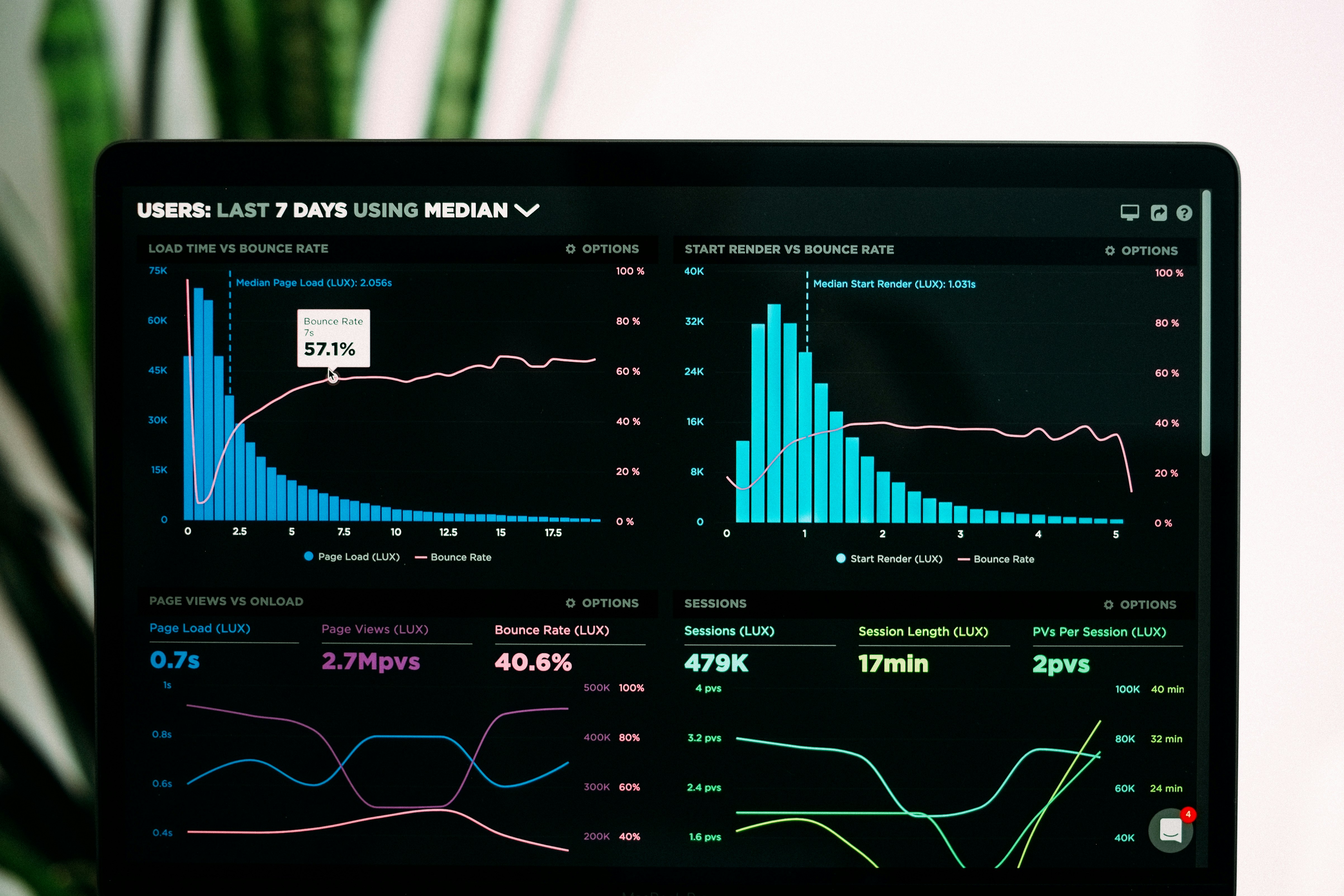
Descubre cómo combinar FT-Transformer y XGBoost con stacking para predecir el abandono de clientes en datos estructurados con alta precisión.
Descubre cómo la atención de rama reduce la interferencia de gradiente, mejorando el F1 de clases minoritarias de 0.261 a 0.522 en desequilibrio severo.

Ocho arquitecturas de recuperación en grafos: el razonamiento estructural requiere operadores específicos, más allá de la similitud vectorial.

El modelo TransGAN-WT combina Transformer y GAN para detectar anomalías en turbinas eólicas con F1 del 96.1% y FPR del 0.06%. Optimiza el mantenimiento predictivo.

Descubre cómo la selección adaptativa de datos mejora la predicción en wearables, especialmente con bajo rendimiento base. Ganancia de hasta 0.7 en AUROC.

SPADER utiliza aprendizaje por refuerzo con recompensas de exploración diversa para mejorar el recuerdo y F1 en QA multi-respuesta.

SPM-Bench: Benchmark automatizado que evalúa LLMs en microscopía de sonda. Descubre su pipeline AGS y la métrica SIP-F1 que revela la personalidad de la IA.