
VESTA: Exploración Visual con Agentes de Herramientas Estadísticas
Descubre cómo VESTA equipa agentes de IA con herramientas visuales dinámicas para explorar y refinar modelos estadísticos con mayor precisión.
Descubre cómo VESTA equipa agentes de IA con herramientas visuales dinámicas para explorar y refinar modelos estadísticos con mayor precisión.
Optimiza la inferencia en tiempo de prueba con el algoritmo OCL, mejorando eficiencia y calidad de soluciones en planificación generativa.

La diversidad en exploración supera a la frecuencia de uso de herramientas. Descubre el colapso y cómo la regularización de entropía mejora el razonamiento.

Descubre cómo ReMax y RePPO logran exploración emergente en RL optimizando políticas mediante reintentos. Resultados en MinAtar y Craftax.

La exploración explícita clave para optimizar preferencias Nash en modelos de lenguaje: nuevo algoritmo logra mejor equilibrio y menor arrepentimiento.

SPADER utiliza aprendizaje por refuerzo con recompensas de exploración diversa para mejorar el recuerdo y F1 en QA multi-respuesta.

Descubre JAMEL: entrena memoria y exploración con señales de novedad. Supera a modelos abiertos y reduce tokens. ¡Más info!

SCALE permite a agentes web automejorar mediante exploración cognitiva, superando limitaciones en entornos dinámicos. Mejora el rendimiento de MLLMs.

Mejora la toma de decisiones de los LLMs con Iterative RMFT: un método que minimiza el arrepentimiento y optimiza el equilibrio exploración-explotación.

Descubre cómo HERec, un nuevo marco hiperbólico, rompe las burbujas de información al equilibrar exploración y explotación, mejorando la diversidad en tus recomendaciones.
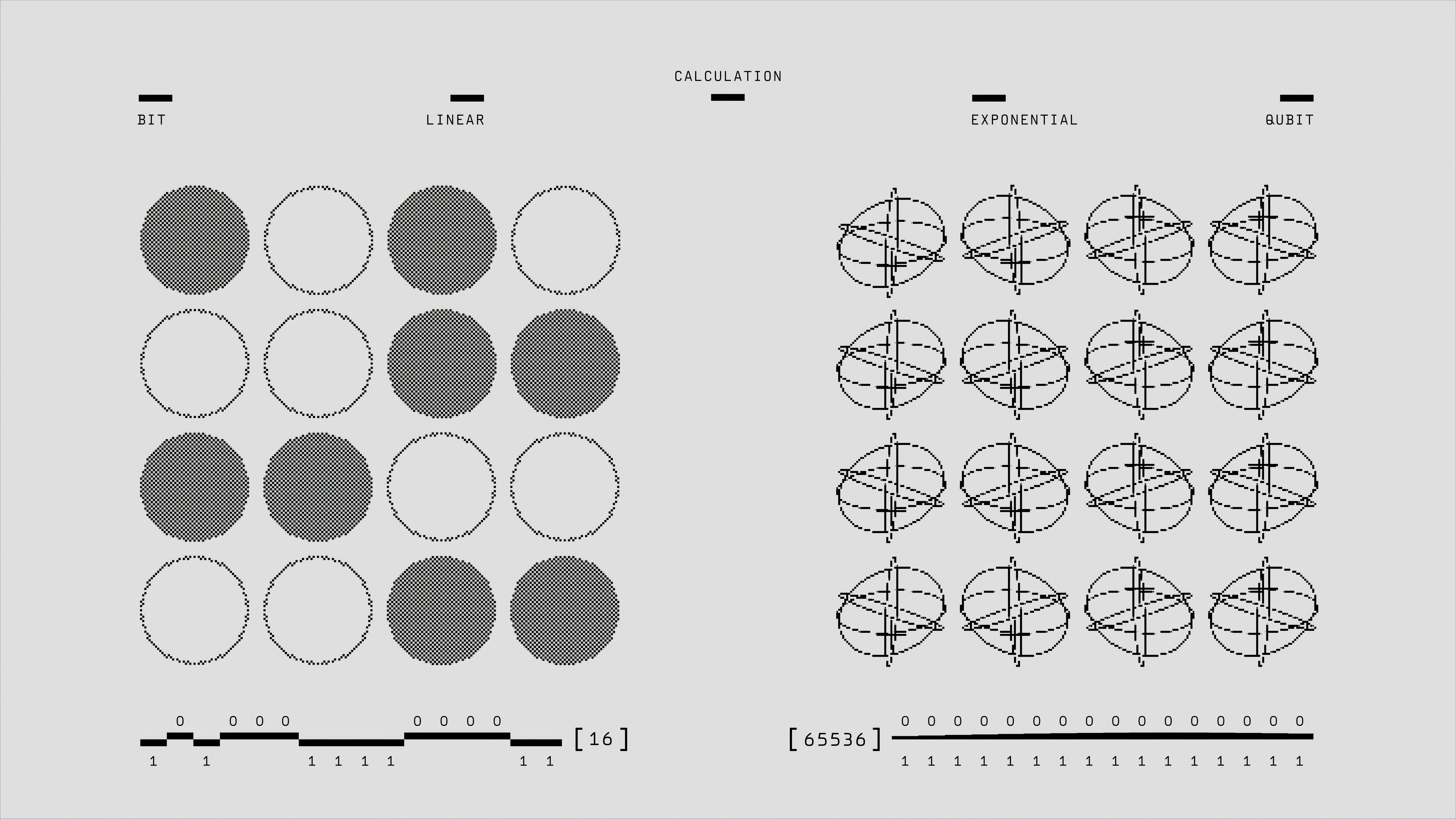
PATHS: temple paralelo para muestreo inicial en alineación de recompensas. Evita modas locales y explora regiones raras de alta recompensa en modelos generativos.

¿Cuándo son suficientes los LLMs como optimizadores de políticas en RL? PromptPO iguala o supera algoritmos clásicos. Conoce sus límites en control continuo.

Descubre cómo los modelos pequeños mejoran la diversidad en GRPO y entrenan modelos grandes con mayor eficiencia. Aumenta el rendimiento en razonamiento matemático.

Descubre el marco DUAL que optimiza el aprendizaje por refuerzo offline a online, mejorando el rendimiento mediante cuantificación de incertidumbre.

Agentes Text2SQL sobreexploran API y generan consultas inexactas. Sophrosyne introduce directivas que reducen sobreexploración 4.6x y mejoran precisión 12.4%.

Feeble Little Horse explora la rareza digital en bitknot. Descubre cómo el grupo indaga en lo único y tecnológico del arte digital.

Explora las tendencias en IA e interacción humano-IA: un enfoque híbrido que revoluciona los ensayos clínicos.
Exploración de comportamiento guiada por conocimiento para agentes GUI ligeros. Mejora la navegación y eficiencia en interfaces gráficas.
Planificación con Vistas mediante Autoexploración de Escena. Aprende a planificar vistas de forma eficiente explorando automáticamente la escena para optimizar resultados.

SAAS aprendizaje autoconsciente para mitigar búsqueda excesiva en búsqueda agentiva. Descubre cómo optimiza la eficiencia en sistemas inteligentes.