
FM-IRL: Flow-Matching para modelado de recompensas y regularización en RL
Descubre cómo FM-IRL combina Flow-Matching con RL para mejorar la exploración y generalización en políticas de aprendizaje por refuerzo.
Descubre cómo FM-IRL combina Flow-Matching con RL para mejorar la exploración y generalización en políticas de aprendizaje por refuerzo.

Descubre cómo los algoritmos adaptativos mejoran la exploración en bandidos con estado latente, reduciendo el arrepentimiento dinámico mediante resúmenes y pruebas de actualización.

iML es un marco AutoML de código ejecutable que garantiza fiabilidad, fundamentación en datos y exploración amplia (90% de envíos válidos en benchmarks).
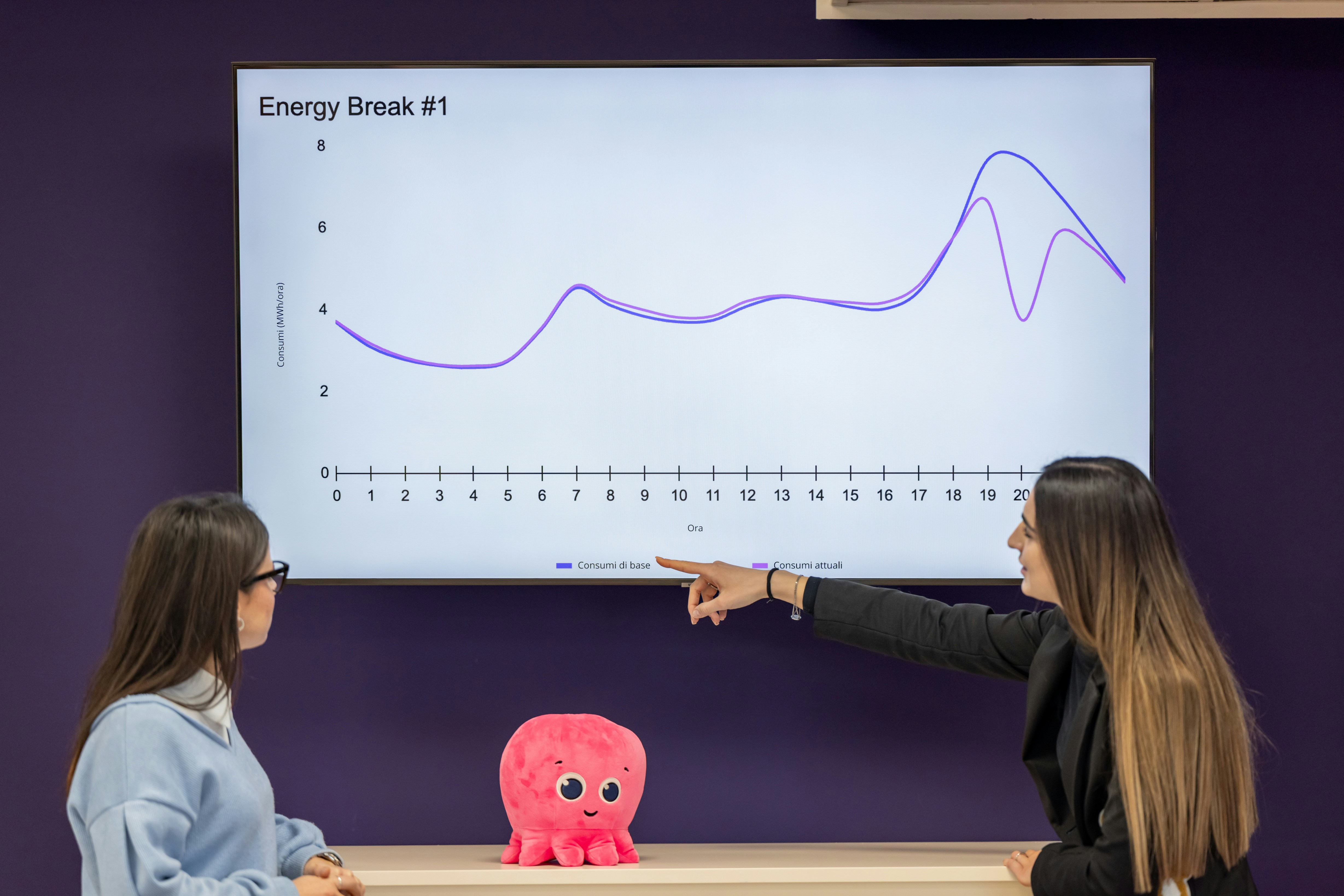
Descubre cómo MFPO acelera el entrenamiento e inferencia en aprendizaje por refuerzo superando limitaciones de modelos de difusión.

InFerActive: árbol interactivo para evaluar seguridad de LLMs. Reduce hasta 5x las muestras necesarias y mejora la cobertura de respuestas dañinas.

El ajuste dinámico de entropía en RL mejora el control de drones, evitando olvido catastrófico y optimizando la exploración. Comparativa SAC vs TD3.

El método OVR reduce la varianza del punto óptimo en optimización bayesiana con garantía de arrepentimiento. ¡Descubre sus fundamentos!
Descubre cómo manejar la incertidumbre en modelos de aprendizaje por refuerzo para evitar la explotación y lograr un aprendizaje seguro y eficiente en robótica.
Sabías que los modelos en RL siempre fallan? Aprende a manejar la incertidumbre para evitar explotación y lograr aprendizaje seguro y eficiente.

Descubre cómo LEMAE usa LLMs para identificar estados clave y acelerar la exploración multiagente, con menos redundancia. Resultados superiores en SMAC y MPE.

Descubre cómo VESTA equipa agentes de IA con herramientas visuales dinámicas para explorar y refinar modelos estadísticos con mayor precisión.
Optimiza la inferencia en tiempo de prueba con el algoritmo OCL, mejorando eficiencia y calidad de soluciones en planificación generativa.

La diversidad en exploración supera a la frecuencia de uso de herramientas. Descubre el colapso y cómo la regularización de entropía mejora el razonamiento.

Descubre cómo ReMax y RePPO logran exploración emergente en RL optimizando políticas mediante reintentos. Resultados en MinAtar y Craftax.
La exploración explícita clave para optimizar preferencias Nash en modelos de lenguaje: nuevo algoritmo logra mejor equilibrio y menor arrepentimiento.

SPADER utiliza aprendizaje por refuerzo con recompensas de exploración diversa para mejorar el recuerdo y F1 en QA multi-respuesta.

Descubre JAMEL: entrena memoria y exploración con señales de novedad. Supera a modelos abiertos y reduce tokens. ¡Más info!

SCALE permite a agentes web automejorar mediante exploración cognitiva, superando limitaciones en entornos dinámicos. Mejora el rendimiento de MLLMs.

Mejora la toma de decisiones de los LLMs con Iterative RMFT: un método que minimiza el arrepentimiento y optimiza el equilibrio exploración-explotación.

Descubre cómo HERec, un nuevo marco hiperbólico, rompe las burbujas de información al equilibrar exploración y explotación, mejorando la diversidad en tus recomendaciones.