
VistaHop: Evaluando razonamiento multi-salto para Visual DeepSearch
Descubre VistaHop, el benchmark que evalúa el razonamiento visual multi-salto. Solo el 24% de aciertos revela grandes desafíos para la IA.
Descubre VistaHop, el benchmark que evalúa el razonamiento visual multi-salto. Solo el 24% de aciertos revela grandes desafíos para la IA.

Descubre el rasgo que he buscado en cientos de candidatos: la capacidad de ser persuadido por la evidencia, incluso cuando demuestra que estaban equivocados.
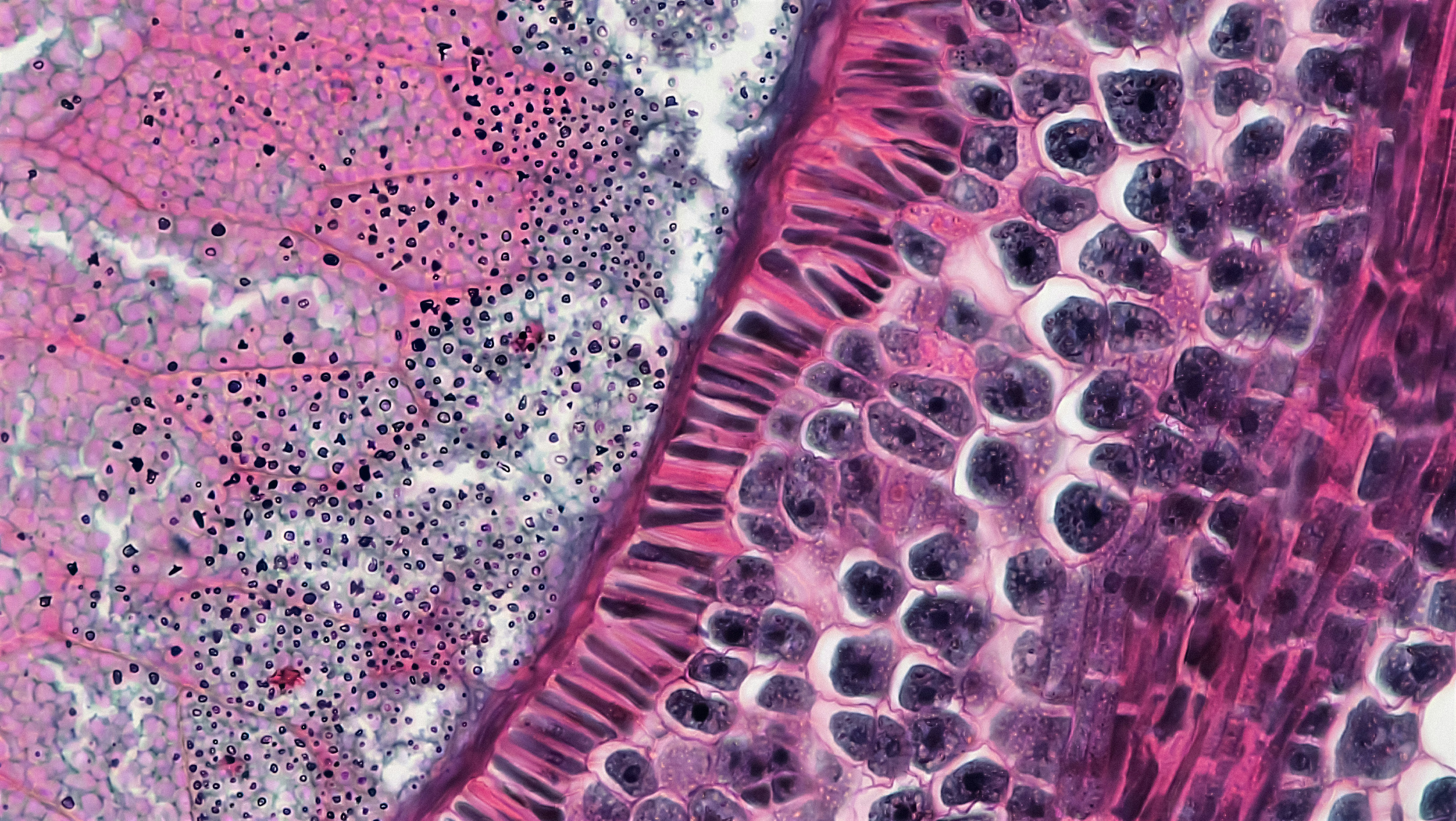
DPsurv utiliza fusión evidencial de doble prototipo para predecir supervivencia en imágenes patológicas, ofreciendo interpretabilidad y medición de incertidumbr

¿Confías en el resumen de tu agente de IA? Descubre por qué necesitas paquetes de evidencia para auditar cambios reales en el código.

TIGER reduce alucinaciones en generación multimodal mediante enrutamiento gráfico de evidencia. Repara hechos falsos en imágenes, audio y video manteniendo la calidad.

TRACE comprime evidencia de riesgo en trayectorias de agentes para mejorar la seguridad en tareas de largo plazo. ¡Alta precisión!

Descubre Ryze, un sistema que automatiza la creación de datasets enriquecidos con evidencia visual a partir de papers biomédicos, superando a GPT-5.

Descubre cómo la minería de procesos transforma datos clínicos en información valiosa para optimizar la gestión hospitalaria, estandarizar triajes y planificar capacidades durante la pandemia.

Los LLMs fallan al predecir efectos de perturbaciones celulares. CORE organiza evidencia contrastiva para mejorar la precisión hasta un 28.6%. Descubre cómo.
Descubre cómo RefMem-Bench y REMIND evalúan y mejoran la memoria reflexiva en diálogos largos, superando la simple recuperación de hechos.
HOPM: mutación de prompts con doble retroalimentación mejora documentos de evidencia +11% en tasa de victorias. Estudio de caso.

Marco RAG con agentes y grafos que analiza literatura técnica en 13 pasos autónomos, verifica citas y busca evidencia externa. Ideal para investigadores.

Descubre AsyMoE: nueva arquitectura para LVLMs que reduce alucinaciones y mejora eficiencia con expertos hiperbólicos y priorización de evidencia.

Usa LLM como expertos en optimización bayesiana multiobjetivo calibrando dinámicamente su confianza con un mecanismo de puerta de evidencia. Mejora la robustez.
Descubre TCAR-Gen, un nuevo marco que combina redes neuronales de grafos, fusión temporal y razonamiento en árbol para responder preguntas complejas sobre casos criminales históricos.

Alinea la evidencia visual de múltiples agentes para consenso preciso en VQA. EAGLE: sin entrenamiento, resultados confiables.

Descubre cómo las transformaciones de probabilidad inducidas en tiempo de inferencia en LLMs siguen patrones log-ratio reproducibles. Un análisis empírico de 4,975 problemas.

Descubre cómo DCRC, un compilador centrado en datos, elimina las alucinaciones numéricas en sistemas de preguntas financieras online, mejorando precisión y auditabilidad.
Aprende las claves para fortalecer el compromiso en la pista de auditoría y trazabilidad, mejorando la transparencia y el control de tus procesos.