
LakeQA: Benchmark de QA exploratorio sobre lago de datos masivo
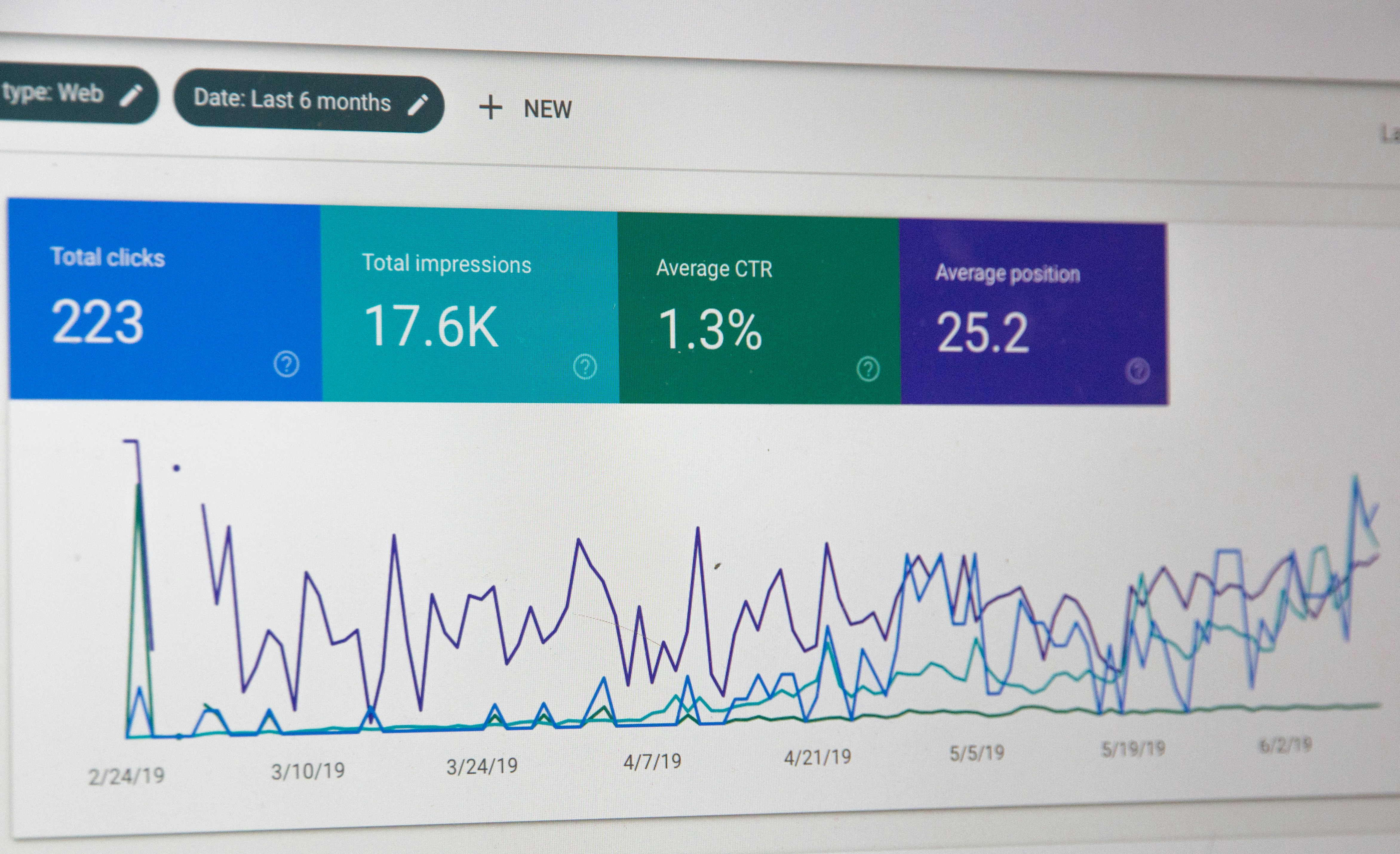
Descubre LakeQA, el benchmark que obliga a los LLMs a buscar y razonar en lagos de datos de 9.5 TB. GPT-5.2 solo acierta el 18.37%.
Descubre LakeQA, el benchmark que obliga a los LLMs a buscar y razonar en lagos de datos de 9.5 TB. GPT-5.2 solo acierta el 18.37%.
Automatiza la gestión de fotos, facturas y correos con IA usando el ciclo de vida de evidencia en tres fases. Agiliza tus reclamos con Nanonets.

Descubre cómo el razonamiento contrafáctico mejora la precisión y fiabilidad del VideoQA al separar evidencia causal de correlaciones espurias. Ideal para sistemas de IA más confiables.

Descubre cómo MA-RAG mejora el razonamiento médico: recuperación multi-ronda y autocoherencia reducen alucinaciones y aumentan precisión.
Descubre cómo extraer computables de benchmarks para obtener evidencia semántica inspeccionable y superar limitaciones del razonamiento textual.

Explora cómo los agentes SWE desarrollan su mentalidad al comprender código real. Estudio con 408 trayectorias revela patrones de navegación, evidencia y parada.

RadOT-Eval: framework auditable que usa transporte de evidencia estructurada para evaluar informes radiológicos, detectando errores clínicos con alta precisión.

Descubre cómo MetaAI demuestra el auto-diseño recursivo con evidencia reproducible del 20% al 50% en SWE-bench. Protocolo MetaAI-Mini.

Descubre por qué los estudios sobre desalineación antropomórfica en IA requieren mayor rigor científico para fundamentar decisiones críticas de seguridad y regulación.

¿Puedes distinguir una foto real de una generada por IA? Un estudio revela que ni humanos ni modelos avanzados son fiables. Descubre por qué.

Explora el sistema de diagnóstico visual con LLM basado en evidencia: interacción multironda, tratamiento multimodal y mayor transparencia en medicina china.

EP-HUBO usa optimización cuántica para seleccionar la mejor evidencia en razonamiento legal, superando el voto mayoritario y preservando hipótesis correctas.
StainFlow mejora el RL en agentes GUI con un modelo que rastrea manchas de entidades y vincula evidencia, aumentando un 3.2% el éxito en entornos dinámicos.
Descubre cómo la consistencia de grafos de evidencia (EGC) detecta alucinaciones en RAG, pero su efectividad varía según la familia de modelos. Un análisis revelador.

Analizamos la sensibilidad al orden en transformers para decisiones binarias y presentamos un nuevo enfoque para medir confianza y reducir alucinaciones.

FLOWREADER optimiza preguntas y respuestas en documentos multimodales con evidencia fragmentada usando flujo de costo mínimo. Supera al top-k retrieval.

Descubre cómo EASE-TTT alinea la atención con evidencia para mejorar la precisión en preguntas de contexto largo usando modelos pequeños.

Descubre cómo TRACE detecta objetivos maliciosos ocultos en agentes LLM conectando evidencia entre acciones distantes. Aumenta la seguridad con F1 de 0.713 y recall de 0.844.

Descubre Harness-1, un subagente de búsqueda de 20B que separa decisiones semánticas de la contabilidad. Logra un 0.730 de recall, superando a otros modelos abiertos.

Descubre la VIOFO A329S 3CH, la cámara de tres canales más completa. Graba frontal en 4K, interior y trasero en 2K. Protege tu vehículo con cobertura total.