
¿Qué preguntas hacer antes de adoptar un portal de inquilinos con consumo energético?
Descubre las preguntas estratégicas, operativas y técnicas que debes formular antes de implementar un portal de inquilinos con consumo energético en 2026.
Descubre las preguntas estratégicas, operativas y técnicas que debes formular antes de implementar un portal de inquilinos con consumo energético en 2026.
Analizamos 7 sistemas de IA en APIEval-20: desde LLMs hasta agentes de código. Sorprendentes hallazgos sobre detección de bugs y consistencia. ¡Descúbrelo!

Descubre cómo el marco GAMBLe analiza sistemas de investigación con IA, revelando que combinaciones adecuadas mejoran rendimiento hasta 67% y eficiencia 39x.

Los benchmarks ignoran cuándo un agente debe detenerse. La capacidad de abstención es clave para la seguridad en IA. Aprende a medirla.

Descubre cómo el marco TBS separa el razonamiento privado de la expresión pública en simulaciones multiagente, analizando la dinámica del silencio.

Nuevo benchmark curricular GTBench evalúa LLMs como asistentes en teoría de grafos. GPT-5 lidera, Llama falla.

Explora ClinicalMC, el benchmark que evalúa LLMs en la toma de decisiones clínicas multicurso. Conoce los resultados y su impacto en la salud.
MedCUA-Bench: benchmark interactivo que evalúa agentes de IA en 18 escenarios clínicos. Los mejores modelos apenas alcanzan 54% de éxito. ¿Superarán el reto?

La superinteligencia solipsista no será cooperativa. El diseño actual de IA genera una brecha entre entrenamiento y despliegue. Conoce el nuevo paradigma de coexistencia.

Descubre por qué la detección de contaminación en benchmarks de IA falla por cambio de distribución y escala. Estudio con 335 evaluaciones muestra la brecha.

Conoce la primera definición formal y meta-modelo para la Teoría de la Mente en IA, basada en psicología y neurociencia.

SAGE muestra que agentes estancados en auto-aprendizaje logran avances con experiencias de pares. Resultados clave en planificación y juegos.
Descubre TSQAgent, un marco de agentes de IA que evalúa la calidad de series temporales mediante razonamiento y herramientas analíticas. Mejora la selección de datos y el rendimiento.

Evalúa el razonamiento químico de los LLMs con ChemCoTBench-V2, un benchmark verificable paso a paso que detecta fallos en la lógica ocultos tras respuestas correctas.
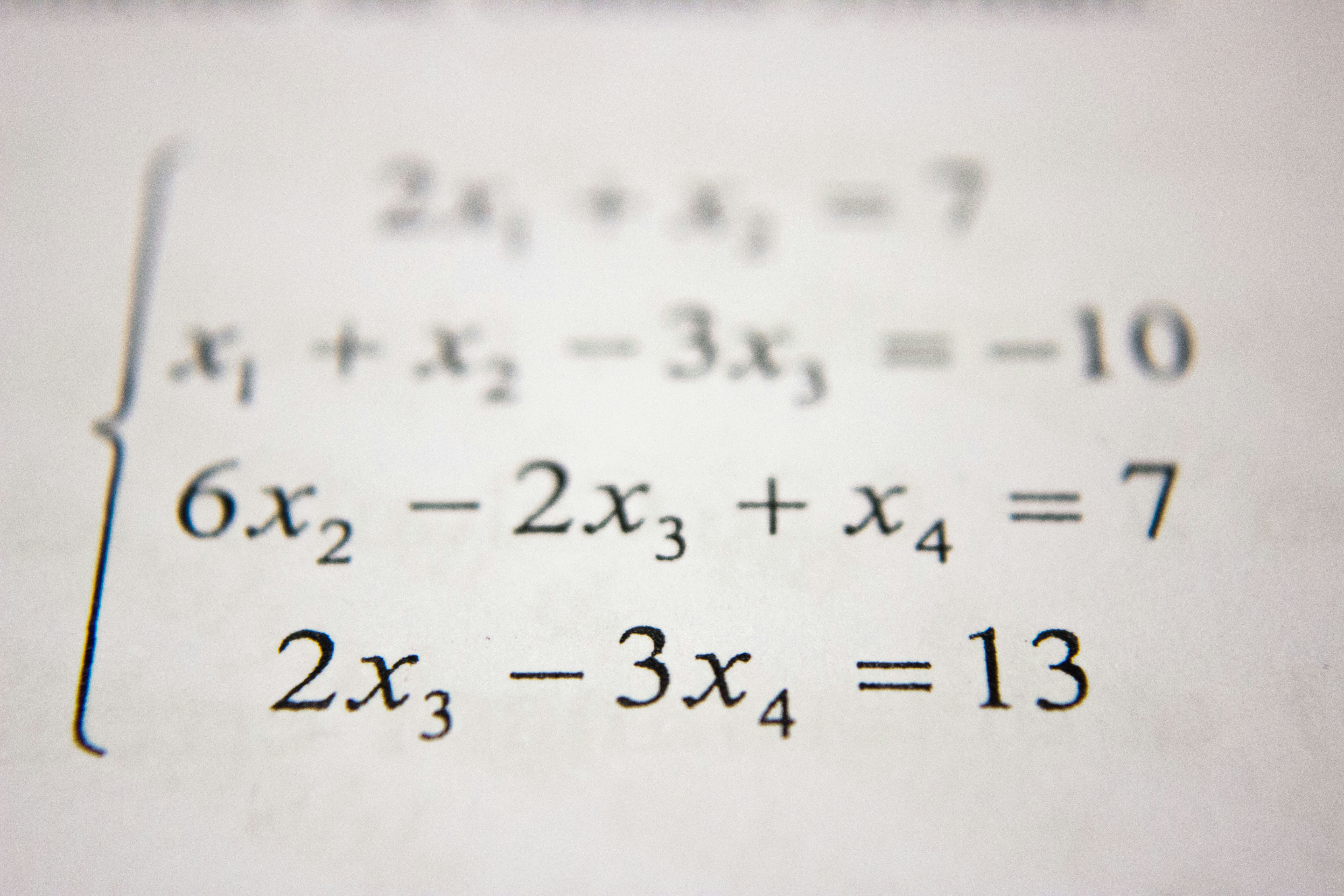
Descubre PyraMathBench: evalúa y mejora la capacidad matemática de los LLMs con 32,505 preguntas y técnicas como SOLVE e IRPO.
scTranslation: benchmark integral para traducción multiómica unicelular. Evalúa modelos con datasets y métricas, analizando selección de características y pocos ejemplos. ¡Descubre insights clave!
Hedge-Bench: solo el 16% de éxito en tareas financieras complejas para agentes de IA. ¿Qué tan lejos estamos del analista humano?

Descubre cómo mejoramos los Oráculos de Activación: reducimos alucinaciones y vaguedad. Presentamos AObrench, el primer conjunto de evaluación completo.

Descubre por qué los SLMs miden artefactos de prompt, no rasgos psicológicos. Un estudio revela cómo los sesgos de cumplimiento dominan las evaluaciones.

Aprende a evaluar proveedores de IA para onboarding de RRHH: experiencia, metodología, costos y SLA. Guía de Q2BSTUDIO.