
Debate entre IAs para tu arquitectura
Descubre cómo usar múltiples AIs especializados para debatir y mejorar tu diseño de arquitectura. Evita soluciones genéricas con un comité automatizado.
Descubre cómo usar múltiples AIs especializados para debatir y mejorar tu diseño de arquitectura. Evita soluciones genéricas con un comité automatizado.

Evalúa la IA para procesamiento de pedidos con demos a medida, sandbox y talleres. Asegura el éxito antes de implementar.

Descubre si tu empresa necesita IA para automatizar el procesamiento de pedidos. Evalúa desafíos, metas y brechas con Q2BSTUDIO.

Pasos clave para identificar al consultor de implementación de IA adecuado en Medio Oriente. Evalúa experiencia, arquitectura, seguridad y escalabilidad.

El benchmark data-centric revela que el fine-tuning de modelos pequeños mejora un 42% la generación de exploits, superando a modelos propietarios.
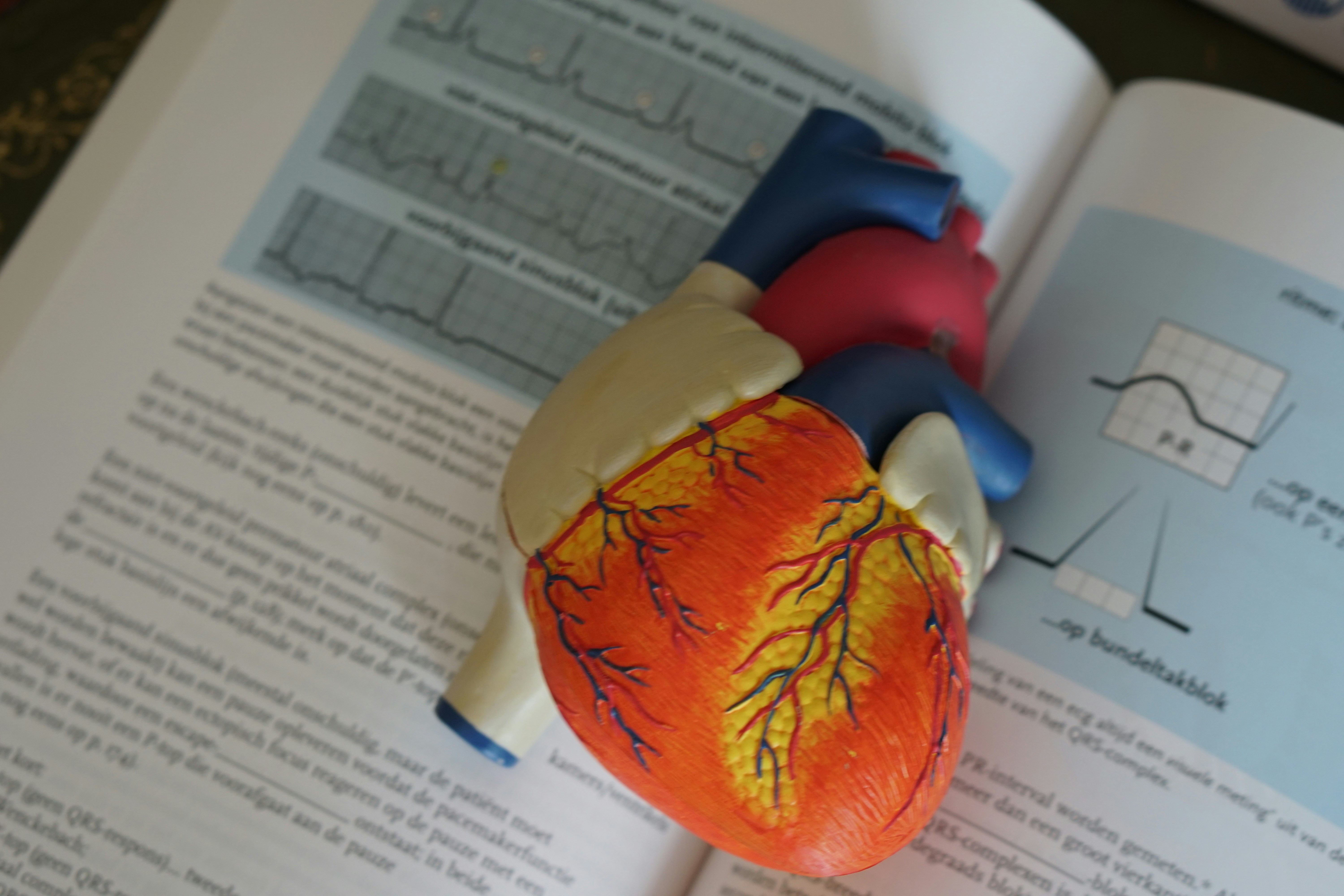
Evaluamos seis enfoques para asignar códigos LOINC a preguntas FHIR mediante aprendizaje por transferencia. BioLORD lidera en precisión.

Descubre cómo PromptShift-CRC controla el riesgo en modelos fundacionales ante cambios en prompts y dominios. Aprendizaje adaptativo en tiempo real.

Descubre GRACE-DS, un entorno de evaluación para agentes AutoML basados en LLM que mide rendimiento, corrección y alineación con recompensas guiadas.

NLICV: marco semántico para evaluar personalización de LLM, reduciendo costos y ofreciendo evidencia clara. Más rápido.

Descubre NLICV: un marco semántico que evalúa personalización de LLM con precisión, bajo costo y explicaciones claras. ¡Optimiza tu evaluación!

Analizamos por qué los sistemas de orquestación con RL no llegan a producción: sesgos, incentivos y necesidad de evidencia operativa.

¿Realmente funcionan los sistemas de orquestación con IA? Un análisis revela que la evidencia es débil y los incentivos académicos distorsionan los resultados.

Nuevo estudio revela que las trayectorias de agentes de IA son únicas: se identifican con un 85.7% de acierto. Aprende a programar y auditar su comportamiento.

Nueva investigación usa grafos de cubos dibujados a mano e IA para detectar Alzheimer de forma temprana y no invasiva.

Descubre LatentGym, un banco de pruebas que evalúa cómo los agentes de IA aprenden de la experiencia entre tareas, mejorando su adaptación y personalización.

Descubre cómo medir la corriente oscura y los sesgos en los jueces LLM con un nuevo protocolo psicométrico. Mejora la evaluación de modelos de IA.

Descubre cómo DeepTrap expone vulnerabilidades contextuales en agentes de IA, yendo más allá de los prompts de usuario.

Descubre cómo evaluar modelos del mundo centrados en la toma de decisiones: métricas, protocolos y pruebas contrafácticas para IA robusta.

La precisión no basta: descubre cómo medir el reconocimiento de sesgos en cadenas de pensamiento. Datos reveladores: Claude 75% vs GPT-4o 13%.

Sistema LLM puntúa manuscritos sin entrenamiento: 0.82 AUROC, consistente. La inteligencia no es el cuello de botella.