
Incertidumbre estructural para medir consistencia en razonamiento lógico de LLMs
La incertidumbre estructural mide la consistencia en el razonamiento lógico de LLMs combinando ranking y entropía. Ideal para detectar fallos de fiabilidad.
La incertidumbre estructural mide la consistencia en el razonamiento lógico de LLMs combinando ranking y entropía. Ideal para detectar fallos de fiabilidad.

Descubre cómo la incertidumbre estructural mide la consistencia en el razonamiento lógico de los LLM, mejorando la detección de respuestas poco fiables.

MemTrace revela que la precisión agregada oculta fallos críticos en la memoria de agentes LLM: el principal cuello de botella es el uso de la evidencia, no la

Descubre SpeechDx, el benchmark que evalúa modelos de IA en 27 tareas de habla clínica. ¿Son realmente generalizables? Lee nuestro análisis.

MLCI: índice de comorbilidad con machine learning que supera a Charlson y Elixhauser al capturar relaciones no lineales en múltiples resultados clínicos.
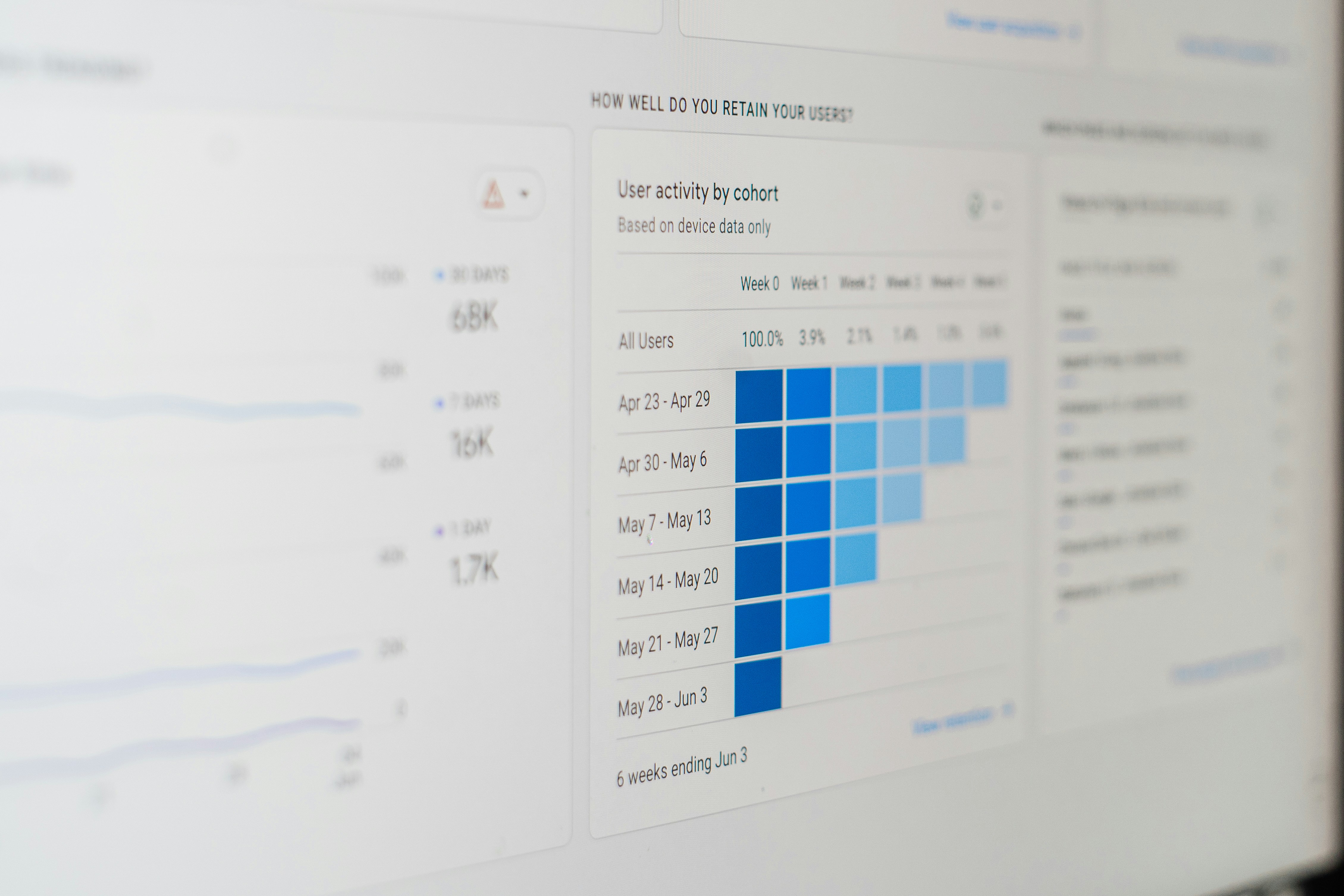
Descubre MapSatisfyBench, un benchmark que mide la satisfacción de usuarios con agentes de mapas. Ideal para mejorar la experiencia con IA.

Descubre cómo un pipeline de LLM como juez, basado en currículos oficiales, mejora la calificación de exámenes con trazabilidad.

Descubre SEAGym, el entorno que evalúa la evolución de agentes LLM auto-evolutivos con métricas de entrenamiento, validación, test y costos, evitando

Descubre DeepInsight: infraestructura unificada para evaluar el stack de IA física, diagnosticando regresiones entre capas con una traza compartida.

El nuevo benchmark EComAgentBench revela que los mejores agentes de compra solo aciertan en el 57.1% de tareas con intenciones ocultas.
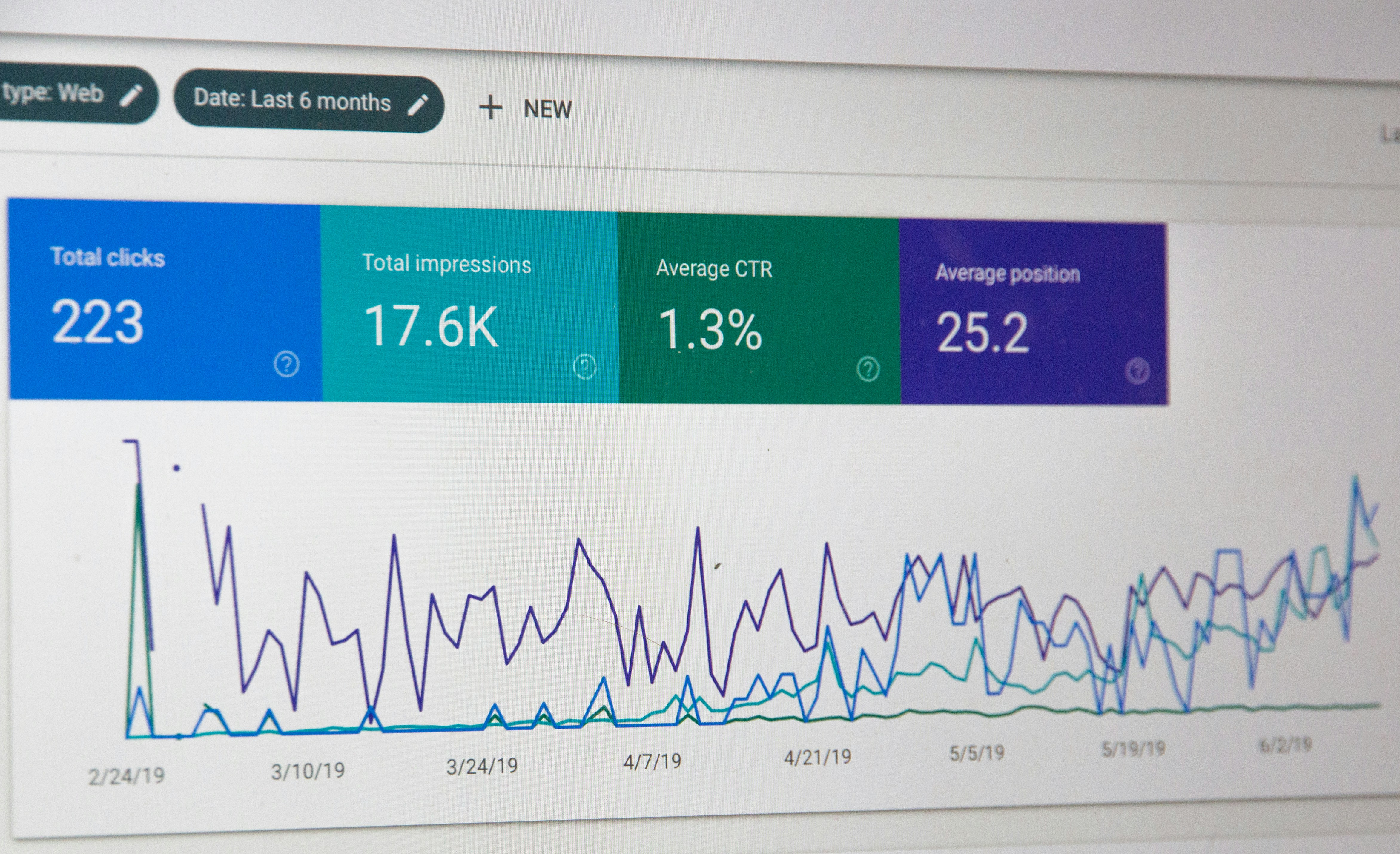
LongWebBench: el benchmark definitivo para evaluar la generación de páginas web largas, estructural y funcionalmente, con interacciones ejecutables.

Descubre cómo el presupuesto de cómputo en inferencia impacta los resultados de modelos de lenguaje de frontera. Un estudio revela que evaluaciones con
Descubre cómo los sistemas de IA se enfrentaron a 10 problemas de matemáticas de investigación. Resultados, soluciones humanas y análisis detallado.

Descubre DRFLOW, el benchmark que evalúa la capacidad de los agentes de IA para predecir flujos de trabajo personalizados a partir de fuentes heterogéneas.
Descubre ZIVARI-TLBO, un algoritmo de optimización que mejora TLBO con relevo élite sin costo computacional. Resultados superiores en múltiples funciones.

Comparativa de inferencia LLM entre GPU y aceleradores emergentes (GroqRack). GPUs ganan en Prefill; GroqRack en Decode (TPOT). ¿Cuándo conviene cada uno?

Estudio revela que agentes de IA con herramientas filtran datos sensibles incluso en tareas benignas. La seguridad operacional es un riesgo crítico diferente a

Un estudio revela que los grandes modelos de lenguaje generan historias muy similares entre sí, y las estrategias actuales no logran aumentar su diversidad.

DriveJudge: nuevo agente de evaluación que combina razonamiento VLM y reglas físicas para clasificar calidad y seleccionar trayectorias, superando a métricas
ReproRepo usa issues de GitHub para auditar la reproducibilidad de papers de ML. Los agentes LLM identifican bloqueos reales en el 90% de los casos.