
¿Mentiste? Evaluando detectores de mentiras en modelos de lenguaje
¿Pueden los detectores de mentiras identificar cuándo un modelo de IA miente? Un estudio evalúa cuatro métodos en modelos de hasta 1B parámetros y revela sus limitaciones.
¿Pueden los detectores de mentiras identificar cuándo un modelo de IA miente? Un estudio evalúa cuatro métodos en modelos de hasta 1B parámetros y revela sus limitaciones.

Descubre cómo las trayectorias de entrenamiento revelan inestabilidad y rendimientos decrecientes en modelos pequeños bajo presupuesto de tokens.

Un estudio experimental muestra que evaluar solo los resultados finales oculta inestabilidad y rendimientos decrecientes en modelos de lenguaje con recursos limitados.

Descubre cómo el benchmark SORB evalúa el impacto de la reducción de grafos en la maximización de influencia en redes multirelacionales. Resultados clave para IA y ciberseguridad.

Descubre AfriSUD, la primera colección de treebanks sintácticos para 9 lenguas africanas. Evalúa modelos NLP y descubre la brecha sintáctica.

¿El benchmark ROAR es confiable? Descubre cómo la borrosidad en mapas de atribución infla resultados y engaña.

Descubre cómo la competencia entre creadores fomenta la diversidad en la IA generativa, evitando la homogeneización y mejorando el bienestar social. Un estudio basado en teoría de juegos.

Descubre cómo los modelos de lenguaje crean jerarquías emocionales que imitan la psicología humana y revelan sesgos sociales. Un estudio fascinante sobre IA y emociones.

Conoce VDE Bench, el benchmark que evalúa modelos de edición de imágenes en documentos densos bilingües chino-inglés. Ideal para IA.

Descubre cómo CMI-RewardBench evalúa modelos de recompensa musical con instrucciones multimodales, mejorando la generación y alineación de música con IA.

Descubre cómo los LLMs de frontera componen señales morales comprimidas con el benchmark Moral Trolley Arena. Resultados sobre ética en IA.

Evaluamos PlanGPT con métricas de coste y tiempo. ¿El resultado? No es mejor que una estrategia greedy. Descubre por qué.

¿Pueden los modelos de imagen imaginar el tiempo? ImageTime lo prueba con un benchmark de consistencia espaciotemporal. ¡Entra y descubre los resultados!

PhysMetrics.Weather evalúa el realismo físico de modelos ML meteorológicos con métricas de conservación, espectrales y dinámicas.
PROBE-Web: sistema interactivo para evaluar modelos de completado de grafos de conocimiento. Ajusta perspectivas de nitidez y sesgo de popularidad. ¡Explora paisajes de evaluación!

DHAuDS es un benchmark de audio dinámico y heterogéneo que expone las debilidades reales de los modelos TTA frente a ruido realista. Ideal para investigadores.

¿Tus modelos de regresión están calibrados? Descubre cómo los árboles de boosting detectan problemas de calibración y auto-calibración en datos de seguros.
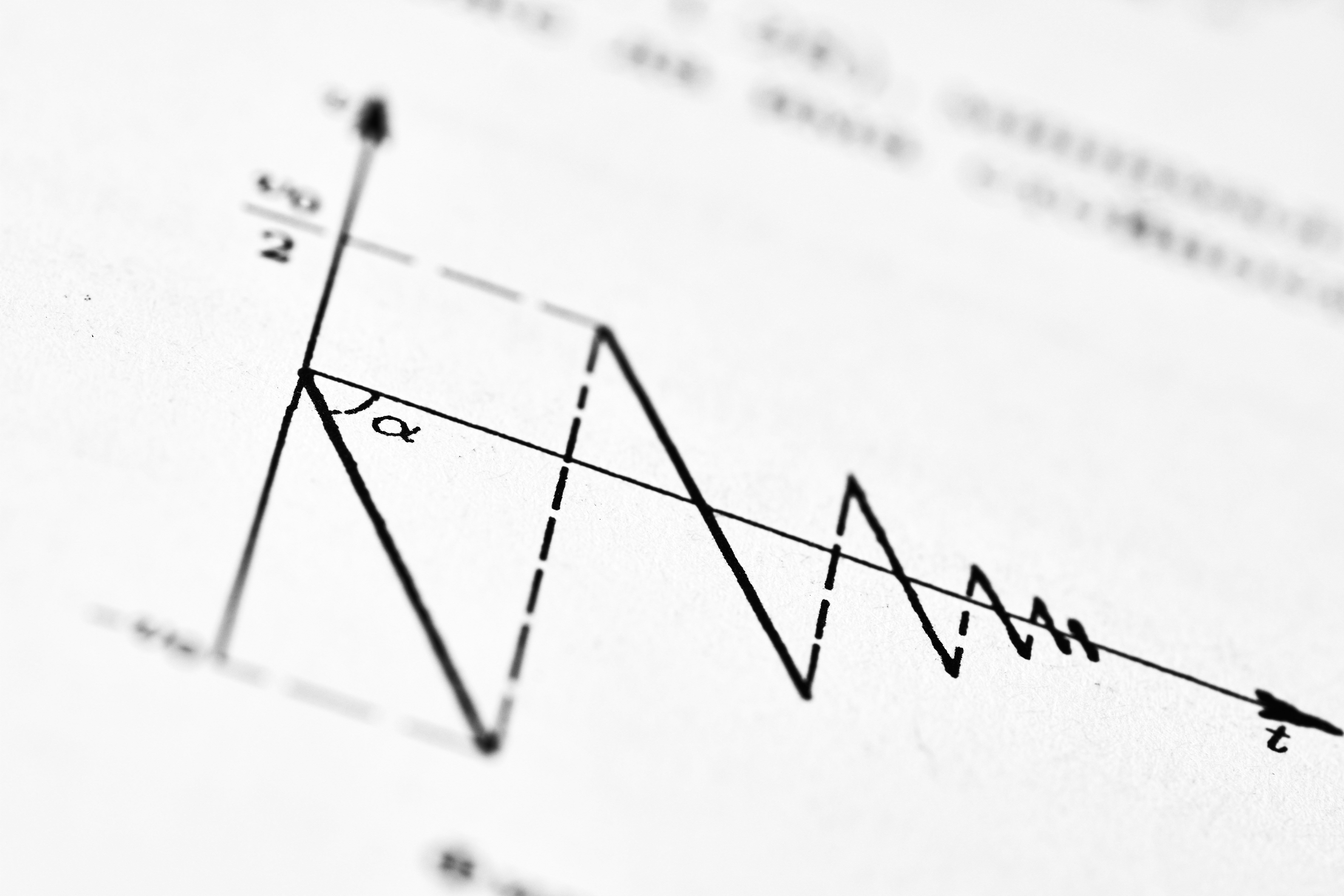
Este marco jerárquico construye intervalos de rango con garantías estadísticas para evaluar modelos en líderboards, manejando la incertidumbre entre tareas.
Descubre por qué el simple intervalo ConformalNaive, sin entrenamiento, supera a métodos complejos en pronósticos de series temporales probabilísticas.

El decreto de Trump sobre IA promete seguridad, pero ¿es solo un gesto vacío? Analizamos sus deficiencias y la realidad.