
OA-CutMix: Corrigiendo el sesgo de etiqueta de CutMix
Descubre OA-CutMix: corrige el sesgo de etiqueta en CutMix usando máscaras de segmentación. Mejora la precisión sin modificar la mezcla.
Descubre OA-CutMix: corrige el sesgo de etiqueta en CutMix usando máscaras de segmentación. Mejora la precisión sin modificar la mezcla.

Fase 2: 5 errores al implementar enrutamiento con embeddings - lecciones sobre precisión, categorías y datos sintéticos.

TadA-Bench ofrece un millón de variantes de proteínas para que la IA descubra rondas futuras en evolución dirigida. Acelera la ingeniería de proteínas con agentes.

Descubre cómo Self-Soupervision crea sopas de modelos sin etiquetas, mejorando robustez un +3.5% en ImageNet-C y +7% en LAION-C. ¡Optimiza tus modelos!

OPAL optimiza el etiquetado para inferencia precisa, logrando intervalos de confianza válidos con menos muestras etiquetadas. Ideal para medicina y ciencias.

Descubre cómo TTRL-CoCoV mejora Pass@k y Pass@1 en razonamiento complejo sin etiquetas, usando verificación condicionada por confianza.

Descubre CoEval: un framework que evalúa y rankea modelos de lenguaje sin necesidad de datos etiquetados ni benchmarks fiables. Resultados limpios y por solo $5.89.

Descubre cómo la descalibración en LLMs afecta mediciones sociales y cómo nuestra destilación reduce el error un 43%. Mejora la validez.

Cómo adaptadores ligeros entrenados en pares vector-etiqueta logran autointerpretación que supera etiquetas y revela razonamiento implícito.

IdEst evalúa representaciones SSL con dimensión intrínseca: métrica geométrica que correlaciona con el rendimiento downstream. Ahorra tiempo en evaluación.

Mejora la detección de especies raras en ecología con etiquetado activo transductivo. Un nuevo criterio de parada híbrido optimiza el descubrimiento de clases escasas.

Annot-Mix mejora el entrenamiento con etiquetas ruidosas de múltiples anotadores vía Mixup. Superior a 11 enfoques en 11 datasets.
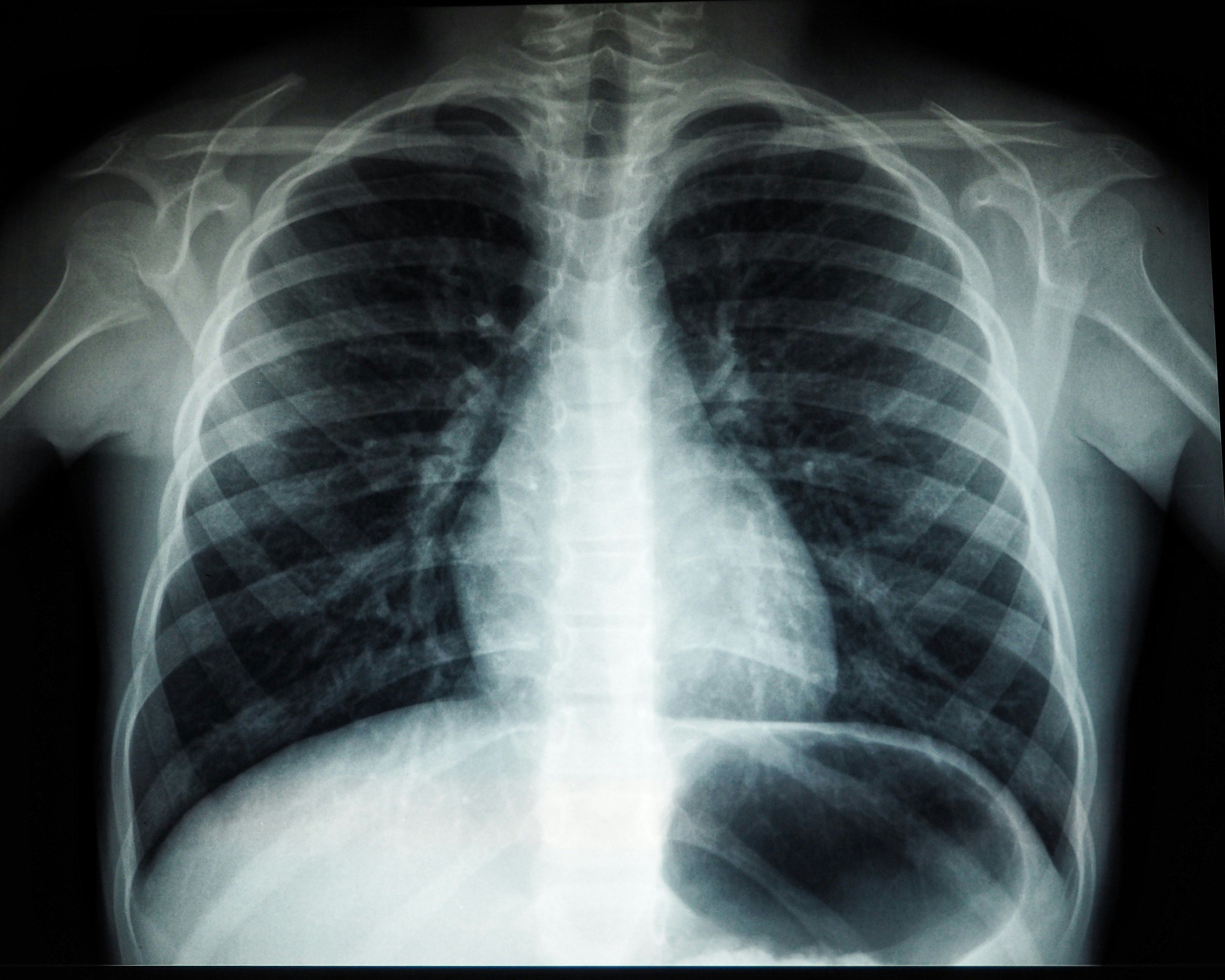
Evaluamos 13 métodos de cuantificación de incertidumbre en clasificación de radiografías de tórax, desenredando incertidumbres epistémicas y aleatorias.

El probing con tokens de parche reactivados supera al costoso fine-tuning en clasificación de audio multi-etiqueta. Descubre este nuevo método ligero y eficiente.
Descubre cómo la regularización implícita mejora la selección de características en problemas multi-etiqueta, reduciendo sesgo y permitiendo un sobreajuste beni
Descubre HiFi-KPI, el dataset con 1.65M de párrafos y 198k etiquetas jerárquicas para extraer KPIs de informes financieros. Modelos de IA alcanzan 0.906 F1 en clasificación.

PaCX-MAE mejora el diagnóstico de rayos X integrando datos fisiológicos (ECG, laboratorio) sin requerirlos en inferencia. Logra +2.7 AUROC y +6.5 F1 con solo 1% de datos.

Descubre un pipeline de ML para clasificar productos minoristas en categorías de precio usando reglas, bolsa de palabras y etiquetado humano confiable.

Descubre cómo los protocolos de colaboración incentivada reducen la complejidad de etiquetado en aprendizaje activo, garantizando racionalidad individual.

Descubre cómo extraer relaciones estáticas no lineales de datos no etiquetados con autoencoder de varianza ordenada. Ideal para optimización en tiempo real.