
Recocido Autorregulado en Modelos de Difusión de Cola Pesada
Aprende cómo el recocido autorregulado en modelos de difusión de cola pesada mejora el muestreo adaptativo. Optimiza la generación con SDE.
Aprende cómo el recocido autorregulado en modelos de difusión de cola pesada mejora el muestreo adaptativo. Optimiza la generación con SDE.

Descubre cómo la minimización de complejidad demuestra que el meta-aprendizaje escala con datos, mejorando la eficiencia en pocos ejemplos.

Descubre cómo FAT revoluciona la predicción de CTR con expresividad estructurada: +4.38% AUC y +2.33% CTR en producción.

Descubre cómo acelerar la inferencia autoescalable en Red Hat AI con Everpure, garantizando soberanía y control total sobre tus agentes y modelos de IA.

Aprende cómo LiDAR acelera 9.5x la guía de recompensa en modelos de difusión, mejorando la alineación con intenciones humanas.

El entrenamiento de LLMs converge lentamente por una razón fundamental: softmax y entropía cruzada generan un escalado de pérdida universal 1/3. Descubre las implicaciones.

Investigación revela que la pérdida escala inversamente con la profundidad en LLMs debido a capas funcionalmente similares. ¿Qué implica para la eficiencia?

Descubre cómo datos sintéticos de calidad permiten las primeras leyes de escalado para LLMs en recomendación, superando datos reales.

Descubre cuándo y cuánto imaginar en razonamiento espacial visual. AVIC optimiza el uso de modelos del mundo, superando a GPT-4o con menos recursos.

Descubre cómo combinar scores (perplejidad, contraste, verificación) con decodificadores para reducir alucinaciones en LLM sin supervisión. Resultados con Qwen3-1.7B.

¿Cómo se relacionan las leyes de escalado con las representaciones internas en deep learning? Este estudio revela una correlación entre rendimiento y estructura

Descubre ATLAS, un framework donde un orquestador decide cómo escalar el razonamiento de LLMs en tiempo de prueba, mejorando precisión con menos llamadas API.
Descubre cómo el escalado de PEFT permite crear millones de modelos personales persistentes sobre modelos base compartidos, transformando el fine-tuning en un sustrato compacto y eficiente.

Descubre cómo equilibrar las tasas de aprendizaje entre capas en redes lineales mejora el rendimiento temprano. Resultados teóricos y experimentales.

En KubeCon Europa, expertos de AWS, Google y Microsoft revelan las claves para lograr IA lista para producción: plataforma madura, seguridad y contribución activa.

Nuevo método SAMN elimina hiperparámetros en reescalado adaptativo monótono para colas largas. Resultados SOTA en benchmarks.

Aprende cómo la complejidad de los datos define el presupuesto mínimo de parámetros para el razonamiento implícito en modelos de lenguaje.
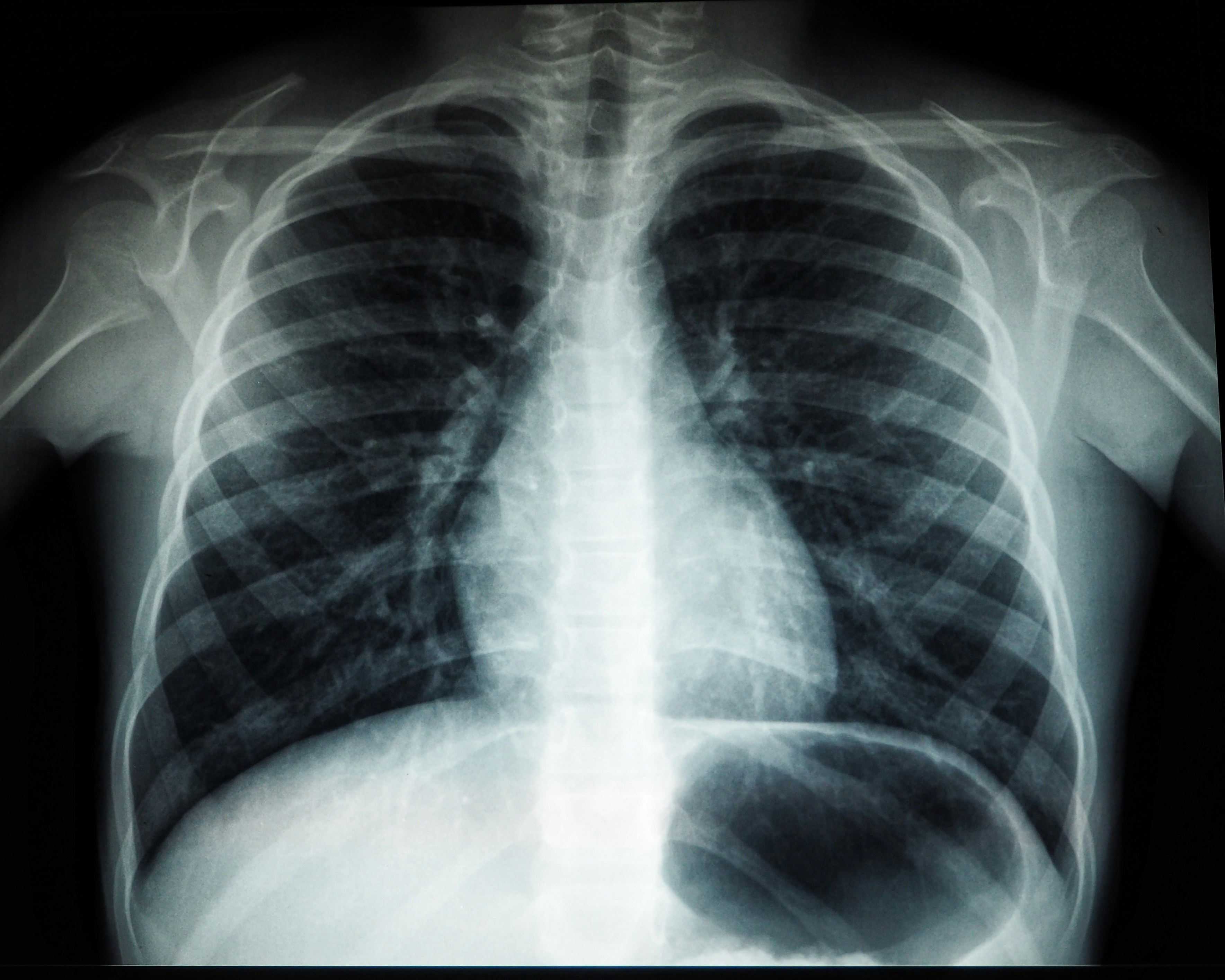
Mejora la generación automática de informes de rayos X de tórax con recompensas Set-Distance. Resultados: +6.8% BERTScore, +7.82% RadGraph, +4.45% CheXbert.

Francia, EE.UU. y China logran soberanía en IA regulando su aprendizaje nacional. Modelo basado en aprendizaje centrado en humanos.

Descubre DAG-MoE: agrega estructuralmente expertos para mejorar MoE sin costos adicionales.