
Selección de evidencia con optimización cuántica para razonamiento legal
EP-HUBO usa optimización cuántica para seleccionar la mejor evidencia en razonamiento legal, superando el voto mayoritario y preservando hipótesis correctas.
EP-HUBO usa optimización cuántica para seleccionar la mejor evidencia en razonamiento legal, superando el voto mayoritario y preservando hipótesis correctas.

Descubre cómo DyCon reduce el sobrepensamiento en modelos de razonamiento grandes sin perder precisión, adaptándose dinámicamente a la dificultad.

Descubre DuMate-DeepResearch, un sistema multiagente auditable con búsqueda recursiva y razonamiento por rúbricas que logra el mejor rendimiento en deep research.
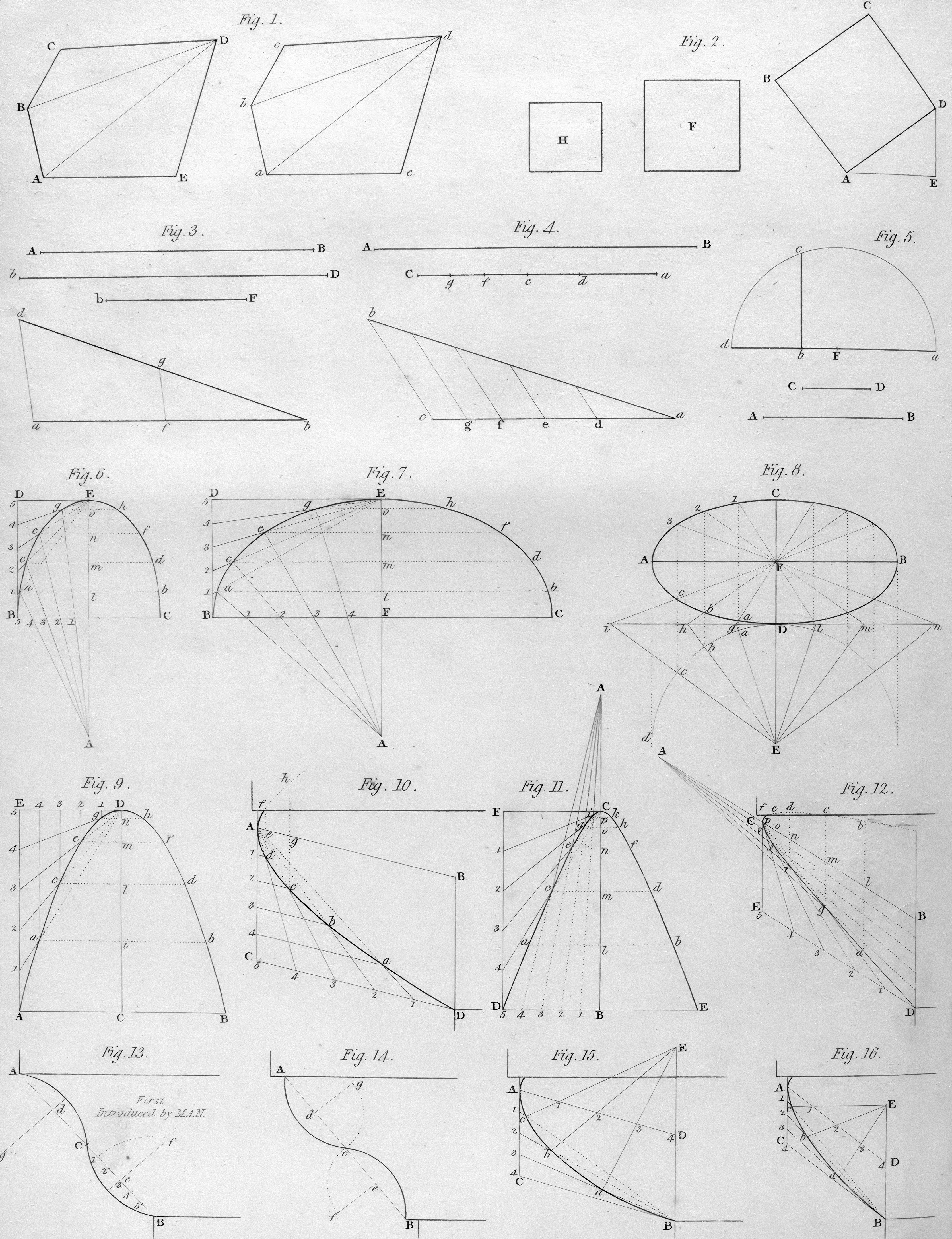
Descubre cómo representar curvas planas con incertidumbre mediante mezclas gaussianas, una técnica para CAD, robótica y planificación de trayectorias.
¿Qué anatomía importa con pocas etiquetas? Descubre cómo la representación anatómica supera a la complejidad del modelo. Benchmark ACDC.

Descubre cómo ViSAE usa circuitos de concepto inspirados en neurociencia para interpretar y guiar Vision Transformers, mejorando precisión y confianza.

Descubre MMBU, el mayor benchmark biomédico multimodal que evalúa la percepción de modelos de IA en 35 submodalidades. ¿Qué tan precisos son los VLMs?
Descubre MSAIC-Net, una red convolucional con atención multicanal y aprendizaje contrastivo que mejora la detección de anomalías miocárdicas en ECG. Resultados en PTB-XL y UVA.

El tamaño del cluster y el condicionamiento del hablante son clave para evitar mezcla de hablantes en vocoders multilingües. Descubre cómo.

Descubre cómo GD y SGD alcanzan tasas óptimas de generalización en redes ReLU profundas, con resultados minimax comparables a kernels.

Descubre DAVE, un método que rompe el bloqueo de homogeneidad en generación de imágenes con IA, mejorando la diversidad sin coste adicional.

Descubre ViSSRes, un método innovador que reduce las alucinaciones en modelos de video grandes usando residuos espacio-temporales. Mejora la comprensión hasta u
Estudio revela cómo la geometría de representaciones internas en VLMs causa alucinaciones. Aprende sobre vectores conceptuales y fallos visuales.

Evaluamos la fiabilidad de cinco modelos frontier con AgentSLR en revisiones epidemiológicas. Descubre los fallos, costes y el reto de la extracción de datos.

Descubre SW-A2-Bench, el primer benchmark que evalúa la generación de agentes de software autónomos a partir de código, impulsando la Web Agentica y la colaboración multi-agente.

Descubre cómo los LLMs pueden ejecutar programas dinámicos de capas, saltando o repitiendo, para mejorar precisión y eficiencia en razonamiento matemático.

Descubre cómo el aprendizaje profundo de representaciones abre la caja negra de las redes neuronales. Principios, teoría matemática y aplicaciones prácticas.
El Identity Trap en modelos EEG: ¿precisión genuina o sesgo de identidad? FMScope lo diagnostica para separar biomarcadores reales. Descúbrelo.

Descubre el seguimiento explicable de dependencias en tiempo real para monitoreo de conflictos en AI-RAN. Usa matrices booleanas y ventanas deslizantes.

Descubre cómo la variación de rendimiento entre ejecuciones afecta a los algoritmos de RL y nuevas métricas basadas en percentiles para evaluarla.