
R3-CoVR: marco zero-shot de razonamiento para videos compuestos
Descubre R3-CoVR, un marco zero-shot sin entrenamiento que alcanza 91.9% R@1 en recuperación de videos compuestos mediante razonamiento multimodal y reordenamiento.
Descubre R3-CoVR, un marco zero-shot sin entrenamiento que alcanza 91.9% R@1 en recuperación de videos compuestos mediante razonamiento multimodal y reordenamiento.

Descubre cómo determinar si un conjunto de datos se ajusta a una hipótesis lógica en estructuras infinitas. Análisis de complejidad y uso de consultas naturales para clasificar muestras.

Aprendizaje por imitación sin entrenamiento: políticas de difusión cerradas logran inferencia en tiempo real en CPU móvil con rendimiento competitivo.

Descubre la auto-mejora en localización de objetos pequeños con LVLMs usando atención: hasta 19% de mejora sin ajuste fino.

Descubre OptCC: el algoritmo que evita que los fallos de red ralenticen AllReduce en clusters GPU, con rendimiento cercano al óptimo.
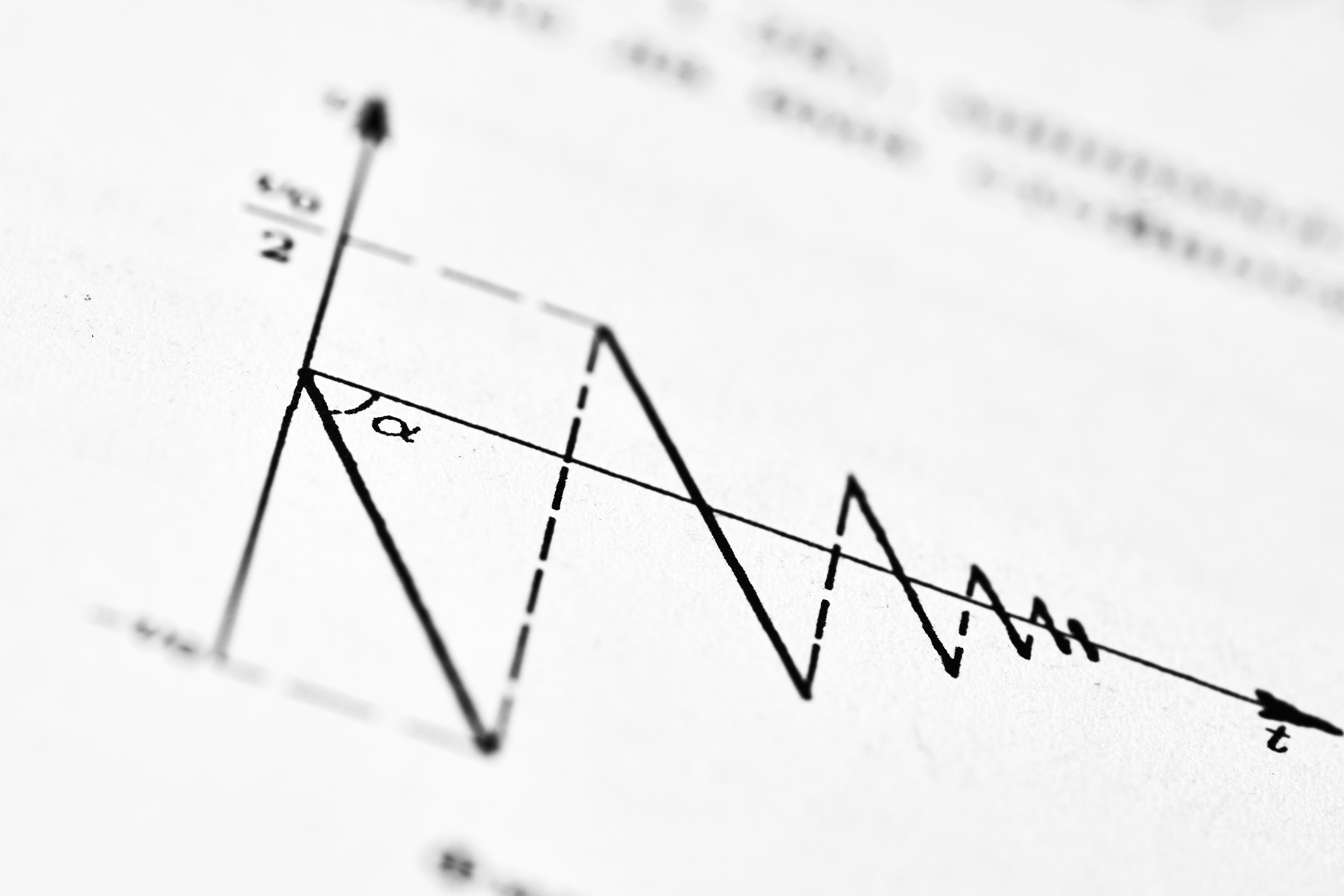
Descubre cómo el algoritmo SAM con paso Polyak mejora la generalización y reduce el ajuste de hiperparámetros, con garantías de convergencia teórica.

Descubre cómo el Anclaje de Contexto Resonante (RCA) reduce alucinaciones en LLMs sin sacrificar fluidez, una técnica ligera de inferencia.
Descubre cómo la minimización de complejidad demuestra que el meta-aprendizaje escala con datos, mejorando la eficiencia en pocos ejemplos.

Descubre cómo las redes neuronales recurrentes guiadas por física mejoran la predicción multietapa, incluso con datos limitados y modelos imperfectos.

Descubre cómo el descenso espejo se adapta a suavidad generalizada para optimizar objetivos no suaves, con aplicaciones en entrenamiento de LLMs. ¡Conoce las nuevas garantías de convergencia!

Aprende cómo un marco Bayesiano unificador permite defensas proactivas y reactivas contra ataques adversariales, mejorando la seguridad de la IA.

La superposición granular de cómputo y comunicación con DMA acelera hasta 1.6x el entrenamiento ML en GPUs. Heurísticas precisas para elegir el plan óptimo.

Descubre cómo PFT mejora un 55% las propiedades fonónicas de materiales al ajustar potenciales interatómicos con IA. Nuevo estándar en simulaciones.
Descubre cómo la relación señal-ruido no uniforme en el estimador REINFORCE causa inestabilidad y colapso durante el entrenamiento en RL.

NestRL optimiza la colaboración humano-IA mediante entrenamiento anidado, logrando mayor adaptabilidad y rendimiento frente a métodos tradicionales en Overcooked.
Mejora la calidad de embeddings multimodales con atención colaborativa y reconstrucción de contenido para tareas de recuperación y clasificación.

Mejora la asimilación de datos continua con modelos sustitutos de IA. Reduce error de modelo y asegura convergencia exponencial. Ideal para sistemas dinámicos.

Descubre cómo los modelos de juego potencial revelan transiciones críticas en el aprendizaje federado, optimizando el equilibrio entre esfuerzo y recompensa.

Descubre cómo los límites de error basados en la complejidad de Rademacher permiten controlar la generalización en computación cuántica de reservorios, incluso con escalamiento exponencial de qubits.

Optimiza pronósticos de series temporales con correcciones adaptativas y humanos en el bucle. Mejora precisión sin reentrenar, usando IA.