
SERA: Agentes de Repositorio Eficientes con Verificación Suave
Descubre SERA, el método que entrena agentes de código abierto para repositorios privados con un costo 26x menor que RL. Acelera tu desarrollo con IA.
Descubre SERA, el método que entrena agentes de código abierto para repositorios privados con un costo 26x menor que RL. Acelera tu desarrollo con IA.

Descubre cómo la información previa determina si la memorización en modelos lineales es beneficiosa o perjudicial, según el umbral de ruido.

Analizamos la propagación de errores en modelos de difusión con datos sintéticos. Primeras cotas inferiores de divergencia y regímenes de deriva.

Descubre IAPO: asigna ventajas a cada token según información mutua. Reduce razonamiento hasta 36% sin perder precisión. Optimiza tus modelos de lenguaje.

IsoCLIP mejora la alineación intra-modal en CLIP sin reentrenar, reduciendo latencia y superando métodos existentes en recuperación y clasificación.

Descubre cómo un nuevo paradigma entrena dos modelos de lenguaje como atacante y defensor en un juego no cooperativo, mejorando seguridad y utilidad. Resultados sorprendentes.

PolarMem: sistema de memoria gráfica polarizada sin entrenamiento que verifica y reduce contradicciones en modelos de visión-lenguaje para un razonamiento multimodal confiable.

El Puente de Identidad: un simple ajuste en los datos de entrenamiento que rompe la maldición de la reversión en modelos de lenguaje. Logra un 50% de éxito.
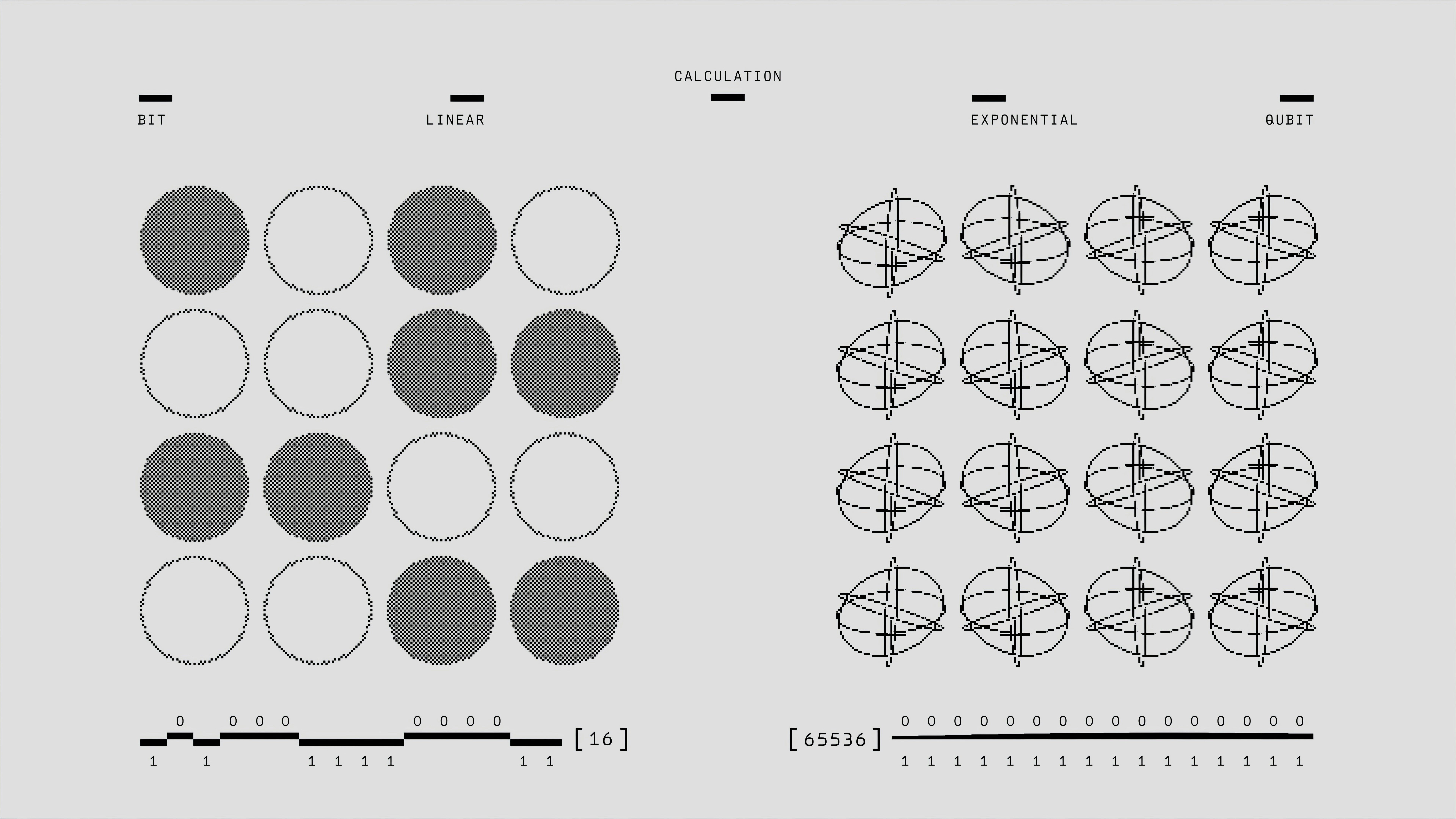
Descubre cómo el muestreo ponderado eficiente con modelos generativos de puntuación logra aceleraciones de 1.2x a 4.7x sin entrenamiento adicional, ideal para IA generativa.

Descubre cómo ELA, usando divergencia KL y mapeo cuantil beta, reduce un 30% el tiempo de entrenamiento al podar capas redundantes en atención por capas.

El escalamiento en inferencia mejora el preentrenamiento generativo, superando la falsa dicotomía entre autoregresión y difusión.

Descubre cómo una red ligera y sin entrenamiento logra segmentar y reconocer texto en escenas con alta eficiencia, reduciendo costos computacionales y manteniendo precisión.

Descubre cómo el Subnetwork Data Parallelism reduce el uso de memoria en un 28-60% al entrenar modelos de IA, manteniendo el rendimiento. ¡Optimiza tu entrenamiento distribuido!

Descubre cómo MAPR usa recompensas predictivas para aumentar la precisión en modelos de razonamiento, acelerando el entrenamiento GRPO hasta 1.28x.

Descubre R3-CoVR, un marco zero-shot sin entrenamiento que alcanza 91.9% R@1 en recuperación de videos compuestos mediante razonamiento multimodal y reordenamiento.

Descubre cómo determinar si un conjunto de datos se ajusta a una hipótesis lógica en estructuras infinitas. Análisis de complejidad y uso de consultas naturales para clasificar muestras.

Aprendizaje por imitación sin entrenamiento: políticas de difusión cerradas logran inferencia en tiempo real en CPU móvil con rendimiento competitivo.

Descubre la auto-mejora en localización de objetos pequeños con LVLMs usando atención: hasta 19% de mejora sin ajuste fino.

Descubre OptCC: el algoritmo que evita que los fallos de red ralenticen AllReduce en clusters GPU, con rendimiento cercano al óptimo.
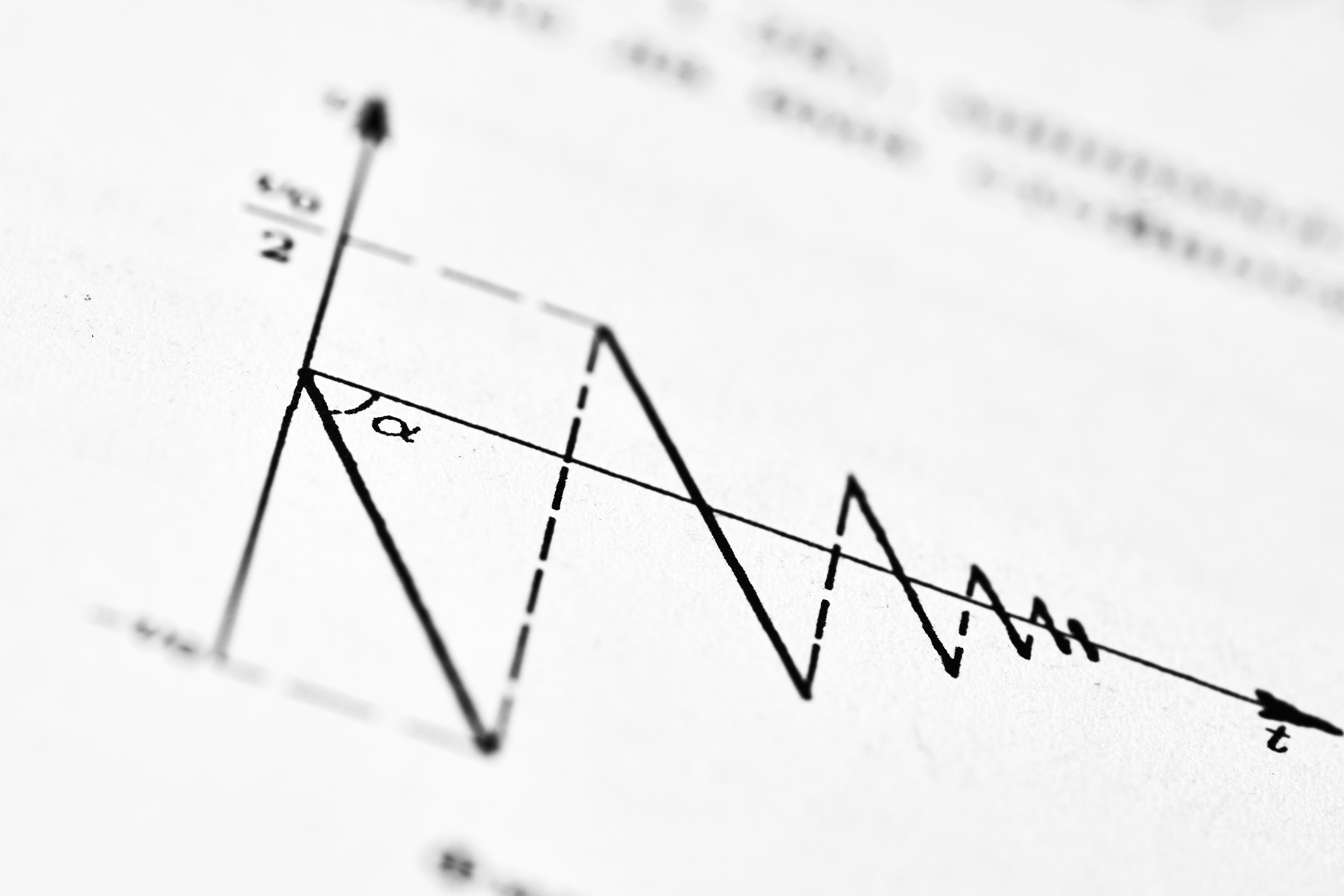
Descubre cómo el algoritmo SAM con paso Polyak mejora la generalización y reduce el ajuste de hiperparámetros, con garantías de convergencia teórica.