
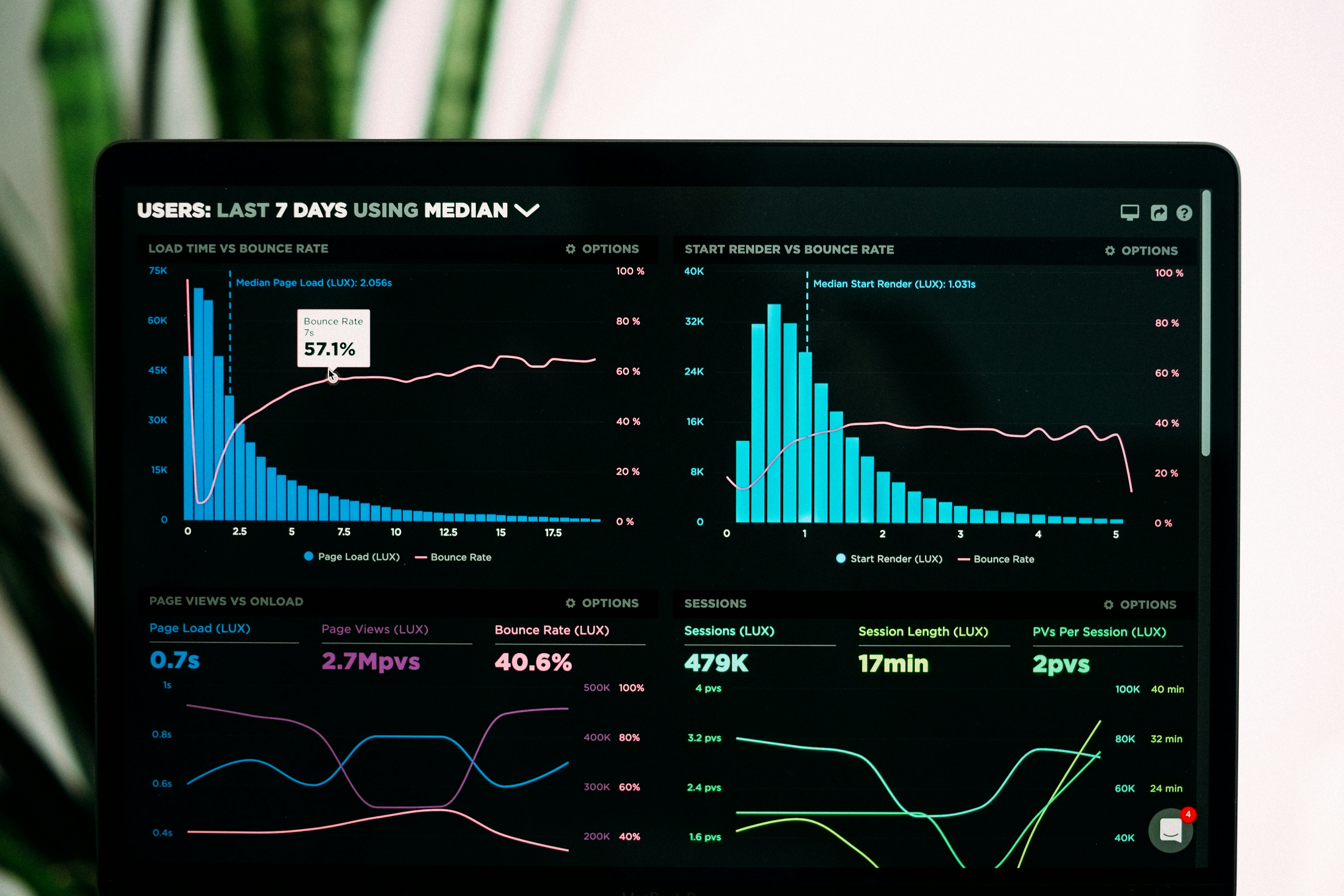
Límites pseudoespectrales en descenso de gradiente acoplado
Descubre cómo los nuevos límites pseudoespectrales revelan amplificación transitoria en gradiente acoplado. Clave para optimización bilevel y adversarial.
Descubre cómo los nuevos límites pseudoespectrales revelan amplificación transitoria en gradiente acoplado. Clave para optimización bilevel y adversarial.

Descubre cómo SKMD mejora el aprendizaje activo de potenciales interatómicos, equilibrando exploración y precisión en simulaciones moleculares. Ideal para MLIPs.

Descubre cómo fusionar BM25 con búsqueda densa late-interaction sin entrenamiento mejora hasta +17.2 puntos la recuperación de memoria en conversaciones largas. Estudio detallado.

Descubre cómo el borde de estabilidad redistribuye el aprendizaje entre grupos de datos, beneficiando a unos y suprimiendo a otros.

Aplicar RL durante el preentrenamiento de LLM mejora rendimiento, superando al enfoque SFT→RL. Fusionar RL y SFT da mejores resultados sin perder capacidades.

Descubre cuándo es posible usar menos coordenadas en DP-SGD sin perder rendimiento. El método TP-TopK optimiza el entrenamiento privado reduciendo el ruido.

Descubre TANDEM, un método que optimiza las proporciones de datos por dominio usando redes gemelas para mejorar el rendimiento de modelos de lenguaje grandes.

Descubre por qué los modelos entrenados para ser siempre útiles pueden presentar fallos inesperados de alineación, sycophancy y falta de control. Aprende cómo mitigarlos.

Descubre cómo LC-PINN entrena un único modelo que resuelve toda una familia de ecuaciones diferenciales paramétricas, sin datos generados por solver.

Aprende cómo el descenso de gradiente logra convergencia lineal en redes ReLU, evitando puntos silla y alcanzando el mínimo global.

Descubre cómo la identificabilidad de neuronas permite fusionar representaciones sin alineación previa, revelando nuevas conexiones en el deep learning.
Descubre CRAFT: un entrenamiento único supera la divergencia de protocolos en IMVC. Elimina reentrenamiento y logra robustez en datos faltantes.

Conoce el adaptador de texto para TabPFN que elimina el cuello de botella PCA, mejorando el rendimiento en datos tabulares con texto de alta cardinalidad.

Múltiples atacantes pueden envenenar datos en distintas etapas del post-entrenamiento de LLMs, revelando vulnerabilidades ocultas.
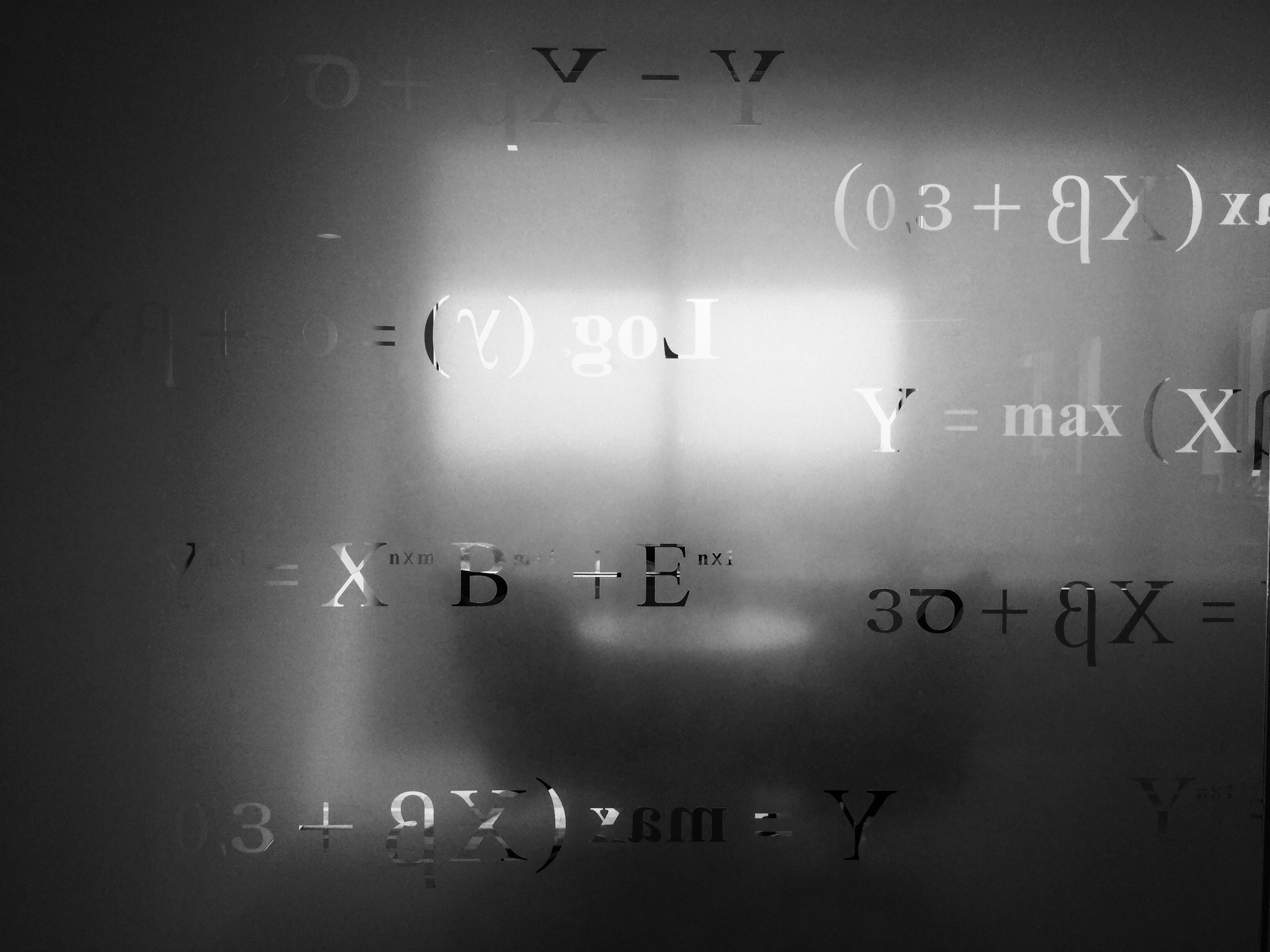
STaR-Quant mejora la cuantificación de baja precisión en DLLMs, logrando 1.69x aceleración y 3.14x ahorro de memoria sobre FP16. Descubre cómo optimizar tu modelo.

OpenRFM mejora un 30% el rendimiento en tareas relacionales. Su arquitectura dual y preentrenamiento inteligente superan a modelos comerciales.

Descubre STRIDE, un nuevo método que atribuye predicciones de LLM a datos de entrenamiento mediante recuperación dispersa, logrando 13 veces más rapidez que métodos anteriores.

Descubre MorphoQuant, un marco de cuantización que mantiene la precisión en modelos omni-modales con solo 4 bits, superando a modelos de 16 bits en ScienceQA.

Descubre QuBLAST, un framework que reduce el tamaño de LLMs hasta un 45% mediante cuantización por bloques y escalado de activaciones, sin perder rendimiento.

Muon duplica la eficiencia de Adam en LLMs gracias a menor curvatura. Descubre el análisis geométrico detrás de su ventaja.