
5 conceptos de Python esenciales para científicos de datos
¿Quieres dejar atrás el código lento? Conoce los 5 conceptos de Python que convertirán tus pipelines en rápidos y funcionales.
¿Quieres dejar atrás el código lento? Conoce los 5 conceptos de Python que convertirán tus pipelines en rápidos y funcionales.

Implementa 7 estrategias de eficiencia energética en tu negocio. Ahorra hasta un 30% en costos y mejora tu sostenibilidad.
Descubre cómo LatentMAS permite a agentes LLM colaborar directamente en el espacio latente, mejorando precisión hasta 14.6% y acelerando inferencia 4x sin necesidad de texto. Código abierto.

Mitiga alucinaciones en LLMs con soft prompts: un método ligero que mejora la precisión y fomenta la abstención responsable. Ideal para aplicaciones críticas.

Aprende cómo los espacios de variación optimizan la aproximación de operadores neurales codificador-decodificador, con garantías de convergencia.

Descubre KDH-CAD, el marco híbrido que alcanza un 92.6% de precisión en clasificación CAD con apenas 250 muestras.

SmartThinker calibra la longitud de cadena de pensamiento logrando hasta 52.5% de compresión y mejora de precisión en modelos de lenguaje grandes.

Descubre CRAFT, un marco que replica expertos con granularidad fina para mejorar el rendimiento de modelos MoE hasta un 20% sin modificar el modelo.

Estimación casi óptima y eficiente de señales discretas con recurrencias lineales. Descubre el estimador minimax y su aplicación en detección.
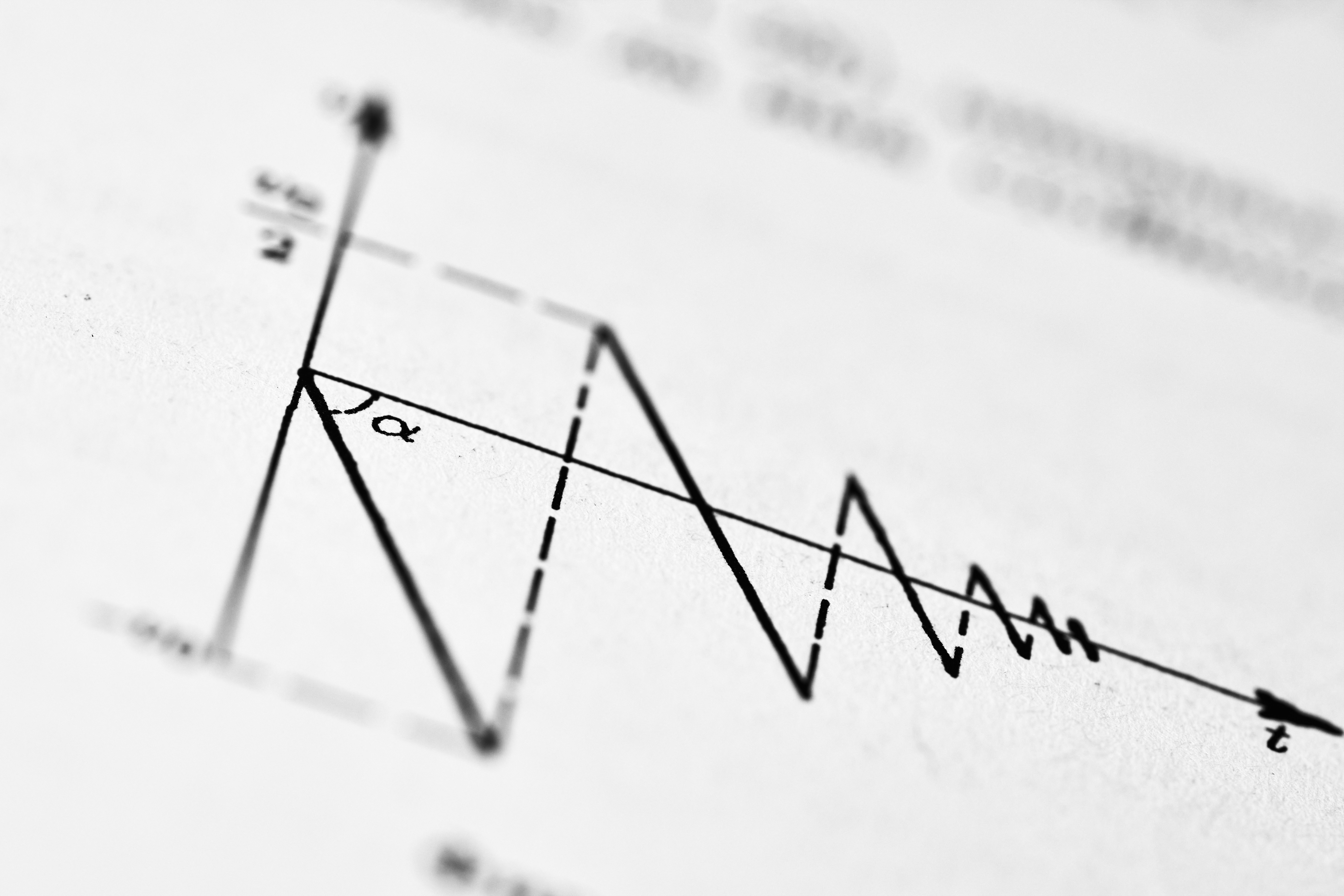
Descubre RefLoRA, una nueva técnica de fine-tuning que acelera la convergencia y mejora el rendimiento de modelos grandes con mínimo costo computacional.

El ajuste dinámico de entropía en RL mejora el control de drones, evitando olvido catastrófico y optimizando la exploración. Comparativa SAC vs TD3.

Descubre cómo los glifos visuales duplican la precisión inicial en modelado de lenguaje chino, pero con un límite final.

Descubre cómo la parada bayesiana óptima permite obtener respuestas consistentes de LLM usando menos muestras, ahorrando hasta un 50% en costos de inferencia.
Descubre Local MixVR, el primer método de aprendizaje distribuido que elimina la dependencia de la comunicación con el número de muestras. ¡Optimiza tu modelo!

Descubre SABER: refinamiento selectivo para transferencia positiva en aprendizaje continuo sin olvidar.
Descubre cómo modernizar aplicaciones heredadas y escalarlas eficientemente sin disparar costos. Estrategias de automatización y cloud con Q2BSTUDIO.

Descubre CRePE, método de poda post-entrenamiento para LLMs que reduce costos sin perder precisión, y PHO que acelera la búsqueda de hiperparámetros.

Descubre cómo el escalado de PEFT permite crear millones de modelos personales persistentes sobre modelos base compartidos, transformando el fine-tuning en un sustrato compacto y eficiente.
Aprende a entrenar modelos de difusión descentralizados con objetivos heterogéneos, reduciendo 16x cómputo y 14x datos con una sola GPU. ¡Acelera tu IA!

Descubre DyLLM, un marco de inferencia sin entrenamiento que acelera hasta 9.6x los LLMs de difusión seleccionando solo tokens relevantes. Ideal para razonamiento y código.