
Es posible la verificación zero-knowledge para entrenamiento de IA de frontera
Un nuevo protocolo permite verificar el entrenamiento de modelos de IA de frontera con pruebas de conocimiento cero, con overhead del 2-5% y en 36 meses. Descubre cómo.
Un nuevo protocolo permite verificar el entrenamiento de modelos de IA de frontera con pruebas de conocimiento cero, con overhead del 2-5% y en 36 meses. Descubre cómo.
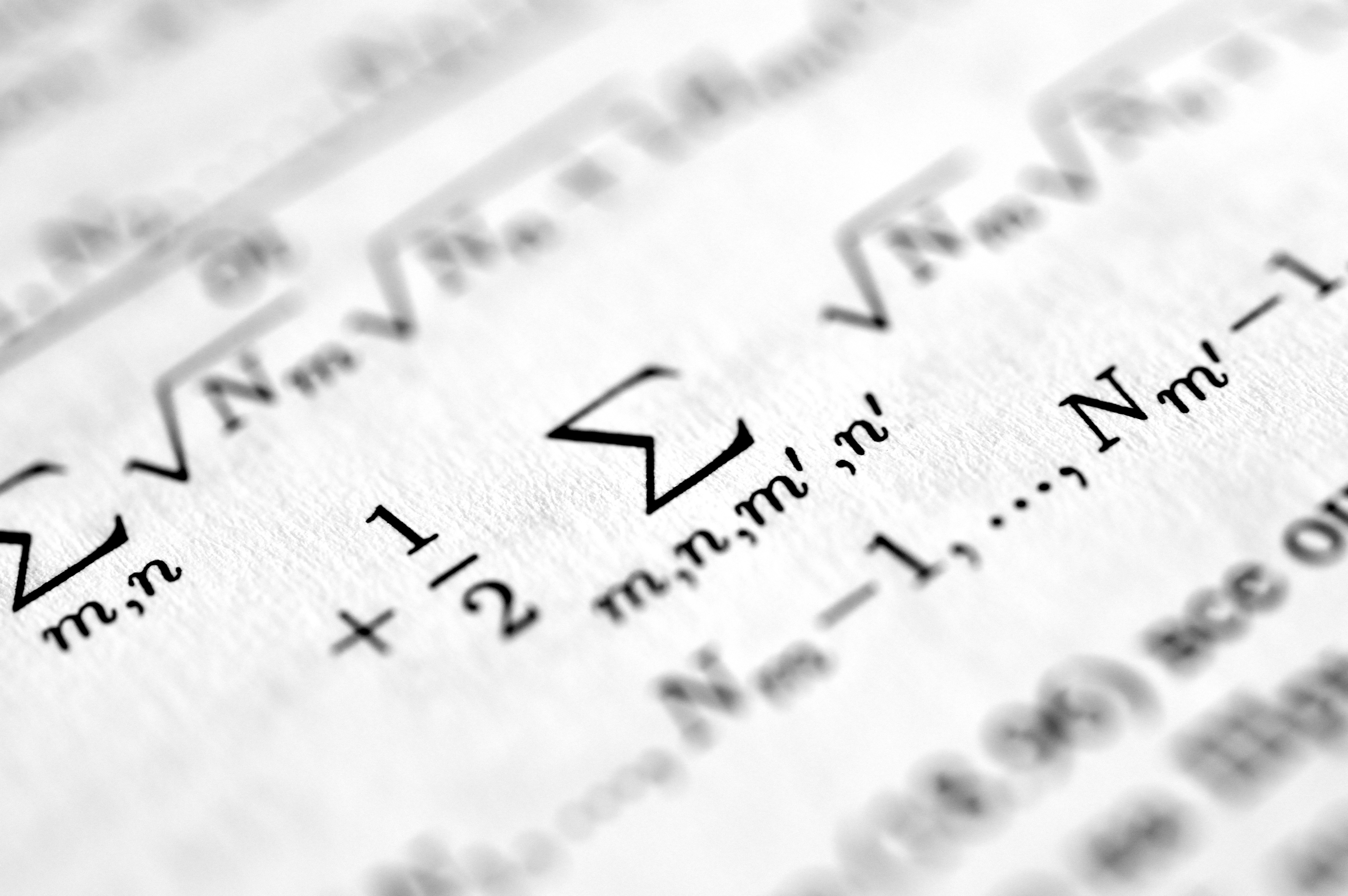
Optimiza tus modelos de lenguaje con CMPQ: cuantización de precisión mixta por canal que ahorra memoria y mejora el rendimiento en dispositivos edge.

NKW: el nuevo sistema que entiende historias largas combinando recuperación, grafos y razonamiento narrativo.

Descubre cómo los nuevos Gemma 4 QAT de Google DeepMind reducen la memoria hasta 1 GB en móviles sin perder calidad. Comparativa completa.

Los costes de tokens de IA en la nube se disparan. Uber agotó presupuesto anual en 4 meses. Microsoft cancela Claude. Descubre por qué migrar a modelos locales.

Explora el Knowledge Manifold: un marco geométrico que mapea semánticamente artículos y genera conocimiento virtual mediante SPH y GPR.

Descubre cómo los modelos TinyML detectan amenazas cibernéticas y RF en naves autónomas con microsegundos de latencia y alta precisión, basado en el modelo SPARTA.

Descubre cómo Q-GNN integra información de entidad y tipo semántico para mejorar el completado de grafos de conocimiento, superando métodos basados solo en relaciones.

GenAutoML genera automáticamente arquitecturas neuronales ligeras para series temporales. Con Dyn-RevIN y <0.01ms de latencia, ideal para Edge AI. ¡Descubre más!

Descubre cómo compartir proyecciones QKV en Transformers reduce el caché KV hasta 96.9% sin perder calidad, ideal para dispositivos edge.

Google lanza Gemma 4 12B para ejecutar agentes de IA localmente en laptops. Descubre ventajas, desafíos y cómo complementa la nube.

Descubre cómo Bennett Legal triplicó sus clientes entrantes usando un knowledge graph y contenido nicho. Resultados: +344% clics, dominio en búsquedas AI.

Descubre cómo un nuevo enfoque de NAS optimiza arquitectura y cuantización en LLM, logrando hasta 1.4x más velocidad y 6% más precisión en tareas de razonamiento. ¡Mejora tus despliegues en edge!

Recover-LoRA recupera hasta un 95% de precisión en modelos de lenguaje cuantizados a 2 bits usando destilación de conocimiento con datos sintéticos. Ideal para despliegue en edge.

Multi-SPIN acelera la generación de tokens combinando modelos pequeños en dispositivos con LLM en servidores edge. Mejora el goodput hasta un 88%.

Descubre cómo Wasmer utilizó Codex para crear un runtime Node.js edge, logrando un desarrollo 20x más rápido y lanzando en semanas en lugar de meses.

Gemma 4 12B de Google: modelo open source multimodal que corre local en laptops 16GB. Analiza audio, video y texto con 256K de contexto. Ideal para privacidad y edge.
Ejecuta Gemma 4 12B en tu laptop con 16GB RAM. Usa Google AI Edge para procesamiento local, dictado por voz y agentes de IA sin conexión.

Descubre la arquitectura modular para agentes de IA en el borde que combina control determinista con inteligencia, garantizando seguridad y eficiencia.

Aprende cómo un gateway de orquestación SLM enruta peticiones en mundos virtuales a servicios de IA distribuidos, sin modificar el cliente.