
Post-entrenamiento federado: priorizar modelos de código abierto
¿Por qué el post-entrenamiento federado debe priorizar modelos de código abierto? Analizamos las ventajas en privacidad, autonomía y transparencia frente a
¿Por qué el post-entrenamiento federado debe priorizar modelos de código abierto? Analizamos las ventajas en privacidad, autonomía y transparencia frente a

Descubre cómo el método DPPF permite entrenar modelos con menos comunicación y mejor generalización, encontrando mínimos planos de forma colaborativa.

Descubre cómo la normalización de pesos acelera exponencialmente la convergencia en detección de matrices sobreparametrizadas. Un avance teórico clave.

Descubre cómo el Q-learning robusto con aproximación lineal converge en tiempo finito bajo incertidumbre chi-cuadrado, usando solo trayectorias markovianas.

Descubre cómo AVA-VLA mejora los modelos Visión-Lenguaje-Acción con atención visual activa y estado recurrente, logrando rendimiento de vanguardia en robótica.

Descubre cómo AReaL-DTA acelera el entrenamiento de LLMs con atención de árbol dinámica, logrando hasta 8x más rendimiento en RL.

Descubre cómo la validación temporal cambia la utilidad de los modelos de machine learning para predecir la mortalidad infantil en Bangladesh. Un estudio clave

Descubre cómo la cantidad de cómputo impacta el aprendizaje por refuerzo. Un nuevo estudio demuestra que más cómputo supera a redes con más parámetros en

Descubre cómo un nuevo algoritmo de caja negra logra arrepentimiento casi óptimo en bandidos adversariales distribuidos, superando records previos. ¡Lee más!
Descubre cómo los Transformers de Visión subcuadráticos logran descripción rápida de imágenes con complejidad lineal, mejorando eficiencia sin perder precisión

Analizamos el muestreo por ensamble lineal en bandidos lineales: demostramos una cota de regret casi óptima con tamaño de conjunto Θ(d log n). ¡Lee el análisis!

Descubre cómo DETECTURE revoluciona la segmentación de imágenes al combinar lenguaje y visión para identificar patrones de textura estables, superando fallos

CADO: minimiza costos reales en optimización combinatoria superando el sesgo de imitación. Resultados de vanguardia.

Descubre cómo Divide-and-Denoise coordina modelos de difusión mediante teoría de juegos para generar imágenes sin conflictos, mejorando calidad y equidad.

Descubre cómo OSP, un método geométrico, elimina alucinaciones en modelos de visión-lenguaje al ortogonalizar vectores de consulta. Mejora la interpretabilidad.

dXPP: penalización para diferenciación en QP. Más rápido, robusto y escalable. Código abierto. ¡Acelera tu optimización!
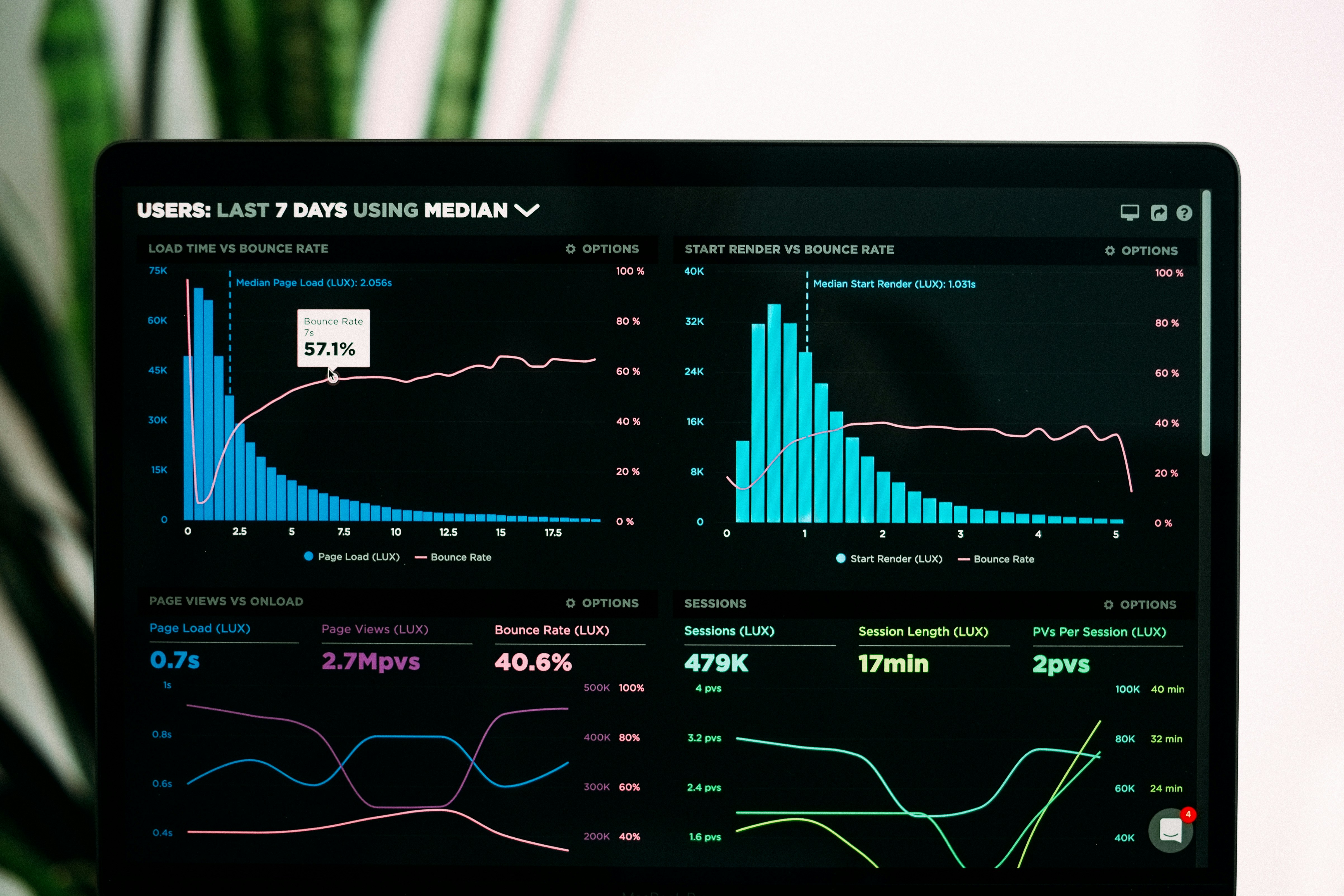
Descubre cómo los LLMs guían la recomendación federada en grafos para mejorar la precisión sin exponer datos. Alineación semántica inteligente.

CAP mejora la representación PPG al alinear con datos clínicos de pacientes. Logra hasta +87% en predicción respiratoria.

Descubre si los benchmarks populares de MARL realmente exigen razonamiento Dec-POMDP o si soluciones simples funcionan. Resultados sorprendentes.

Descubre cómo el machine learning y un sistema RAG permiten pronosticar la resistencia bacteriana y apoyar decisiones políticas con datos de la OMS.