
DeltaMem: Memoria Incremental para Agentes LLM con Árboles Residuales
Optimiza la memoria de tus agentes LLM con DeltaMem: árboles residuales que reducen redundancia y conflictos. Aprendizaje continuo más eficiente. Lee más.
Optimiza la memoria de tus agentes LLM con DeltaMem: árboles residuales que reducen redundancia y conflictos. Aprendizaje continuo más eficiente. Lee más.

El marco CER (control, evidencia, respuesta) permite reconstruir pérdidas mediadas por IA para reclamaciones de seguro. Ideal para riesgos de IA agentiva y generativa.
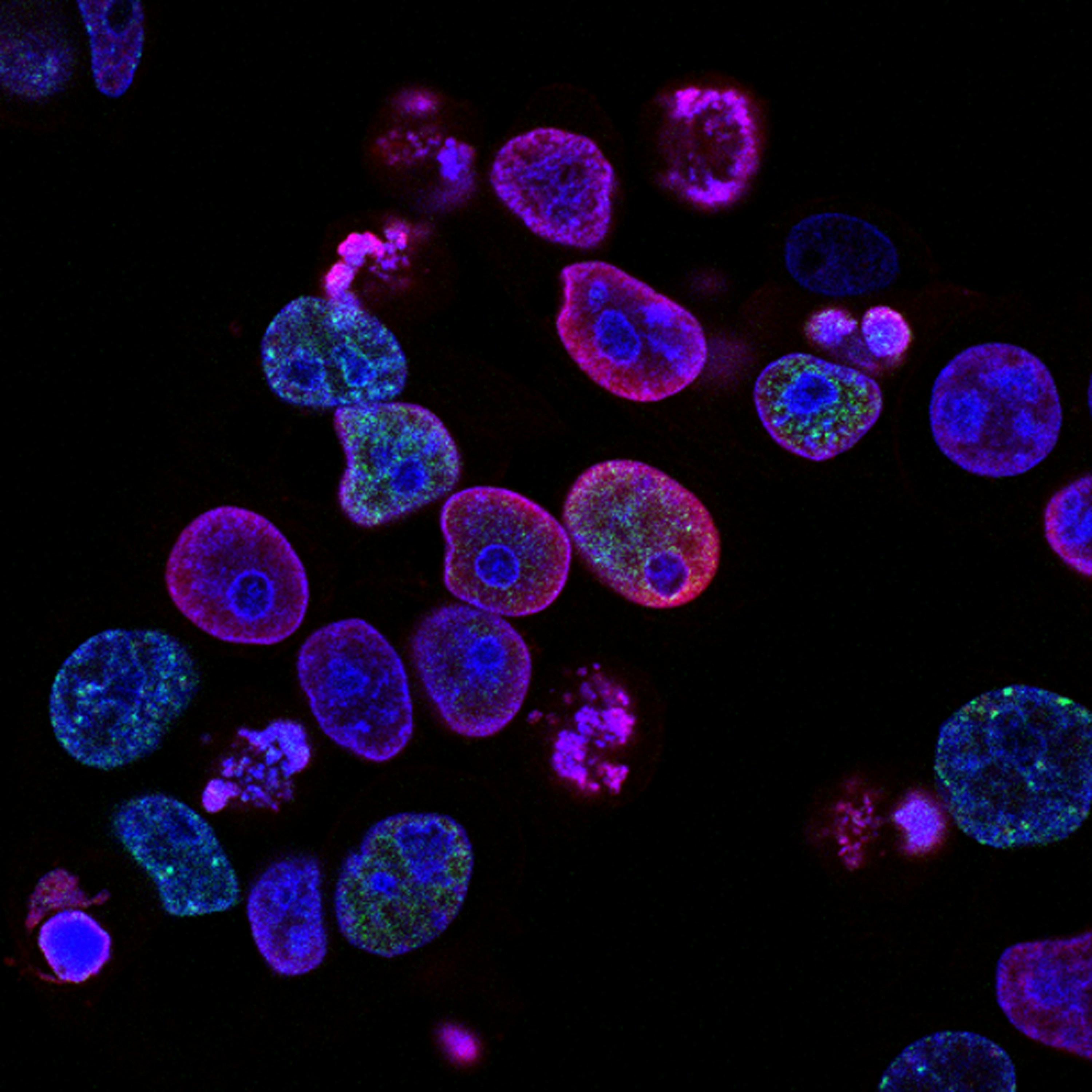
Descubre scBatchProx, un método de refinamiento ligero inspirado en federated learning que estabiliza embeddings de células individuales y mejora la clasificaci

Diagnóstico y mitigación del colapso de flujo en hiperconexiones de modelos Transformer. Aprende a romper la simetría y mejorar el rendimiento.
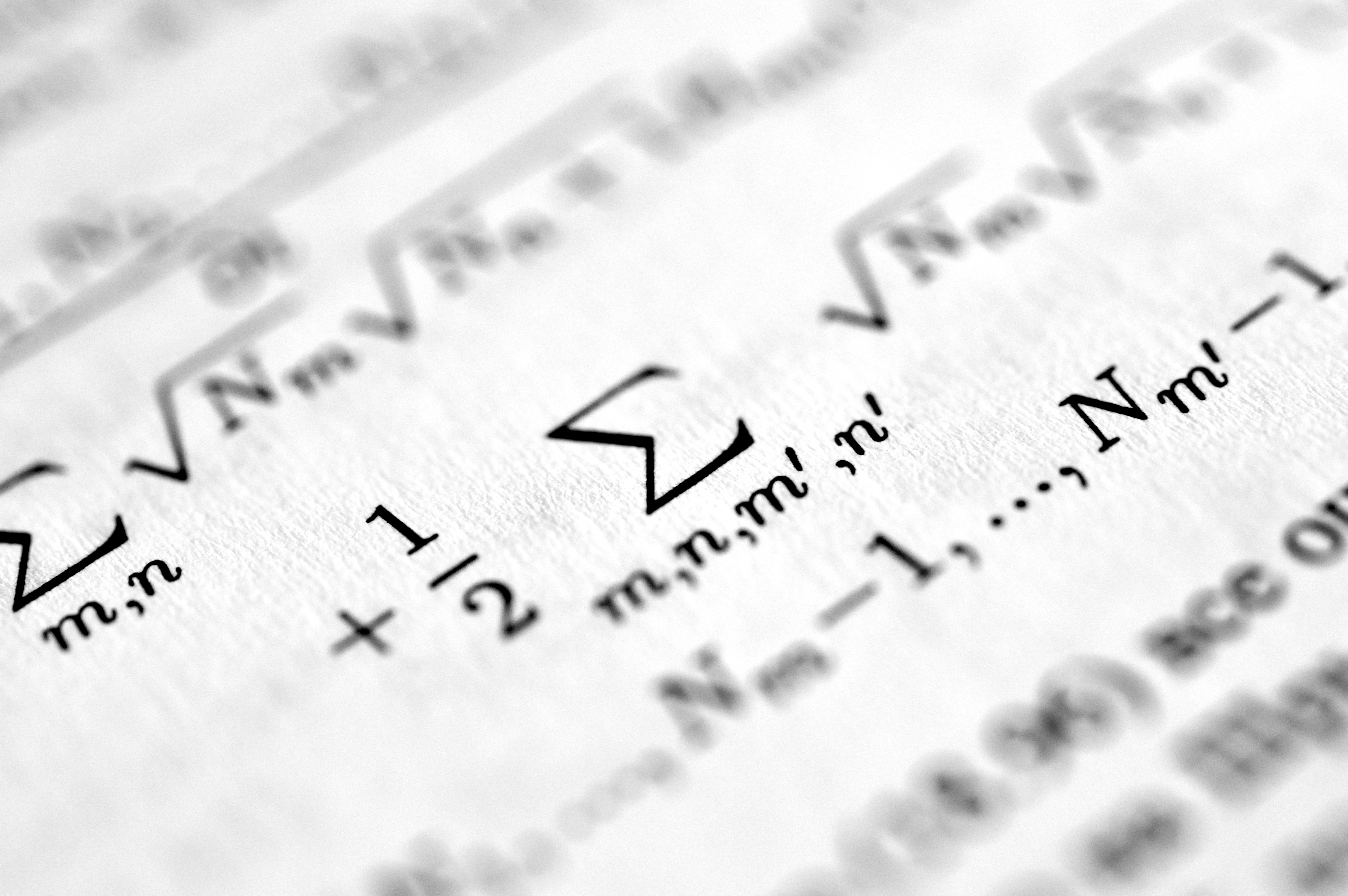
Descubre cómo los LLMs representan la suma geométricamente y por qué cometen errores. Un nuevo estudio revela la estructura oculta de la aritmética.

Descubre FutureWeaver: optimiza cómputo en tiempo de prueba para sistemas multi-agente con planificación dual y colaboración modular. Con presupuesto limitado.
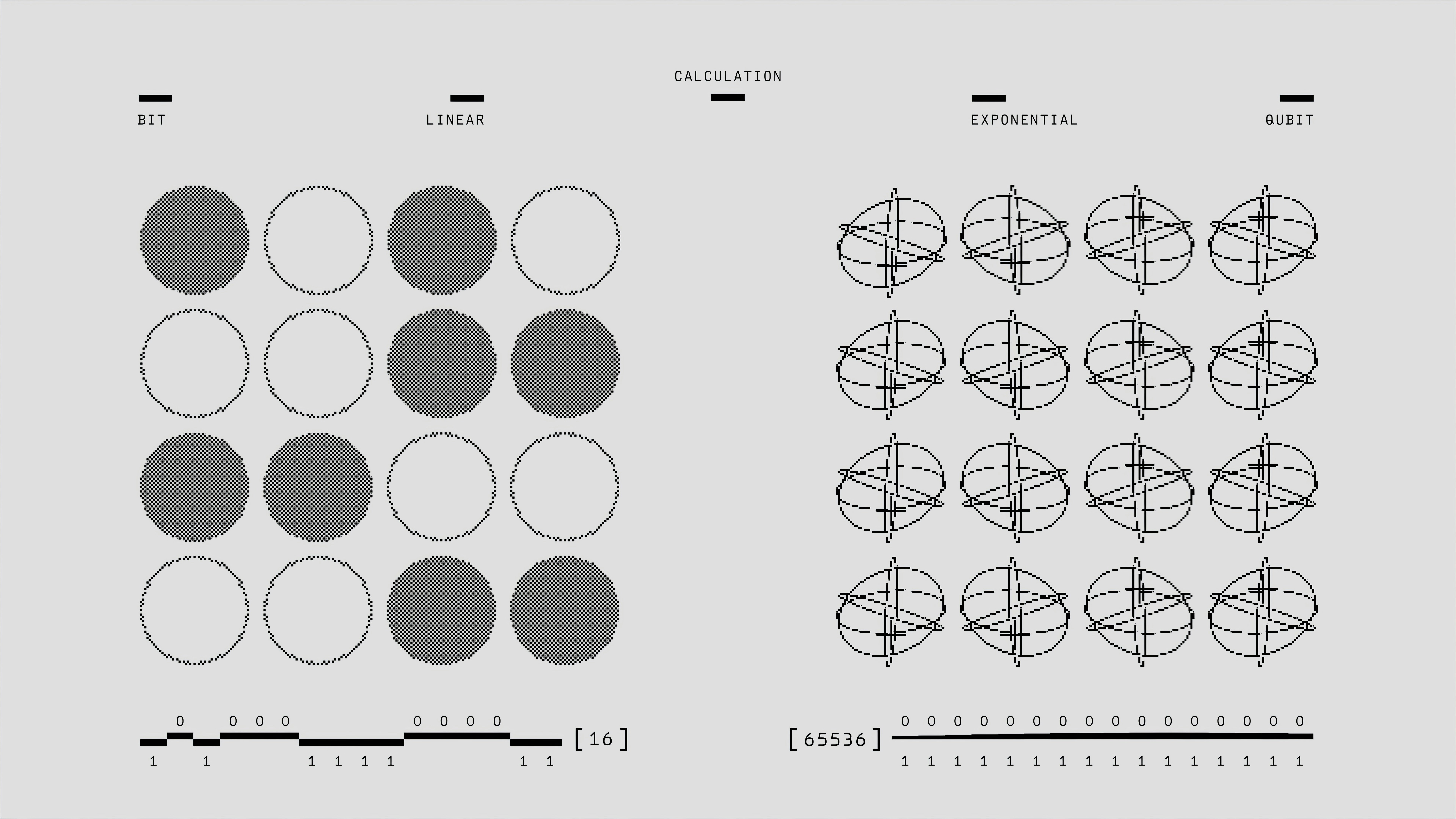
Descubre cómo ReaLM usa cuantificación residual para alinear embeddings de grafos de conocimiento con LLMs, logrando rendimiento estado del arte.
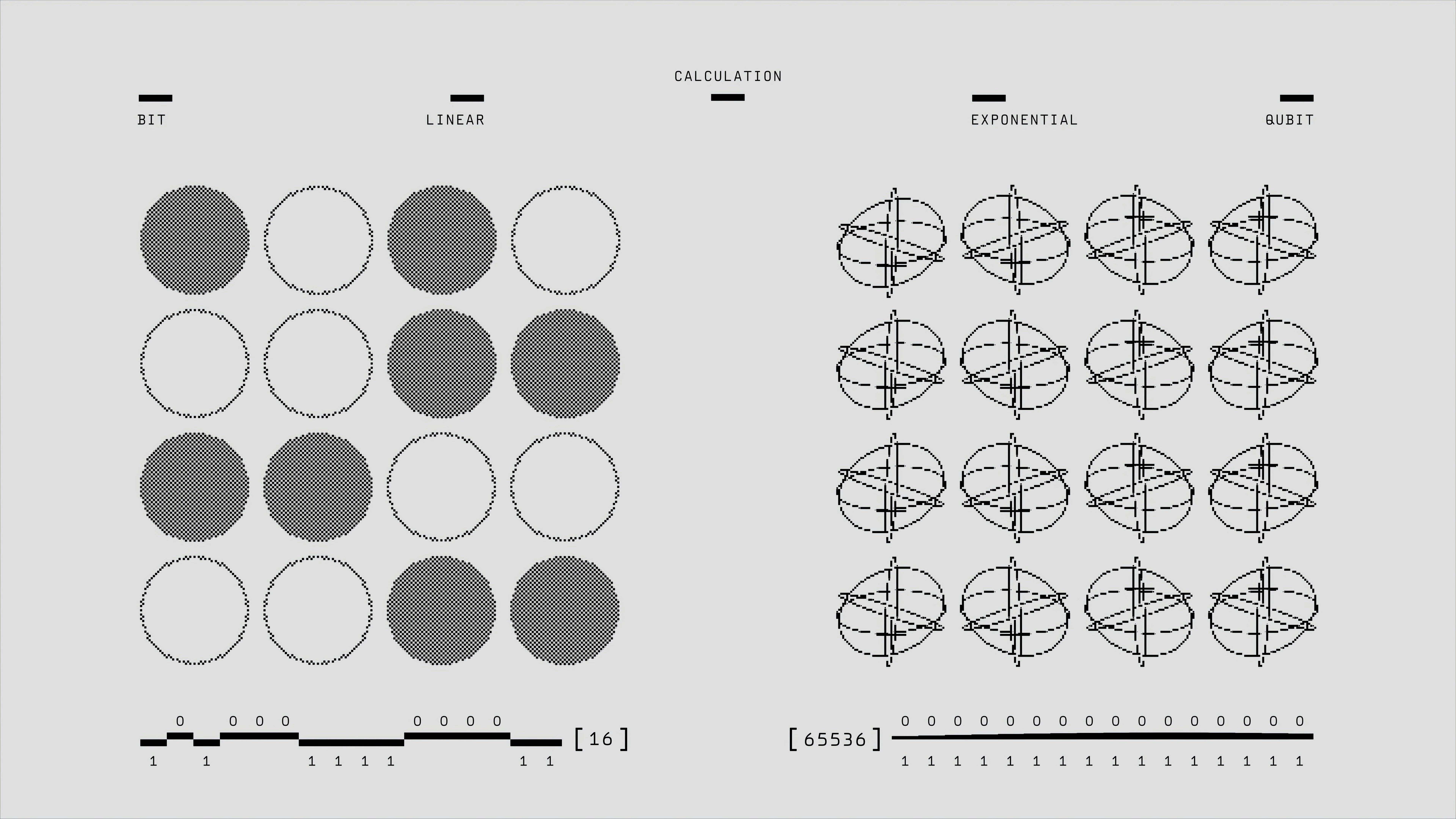
Descubre ReaLM, un innovador marco que une embeddings de KG y LLMs mediante cuantización residual para mejorar la completación de grafos. ¡Rendimiento líder!

Descubre Ref-DGS, método Gaussian Splatting dual para reflejos especulares sin trazado de rayos, con reconstrucción y síntesis de vistas de alta calidad.

Descubre HARVE, un método sin entrenamiento que edita el vector de recompensa para eliminar el reward hacking en modelos de lenguaje. Mejora robustez sin perder capacidad.

Mejora la robustez de tus GNNs con TAGR: un método ligero de reparación de grafos que combina kernel Gaussiano y corrección topológica. ¡Optimiza tus modelos!

Descubre OASIS, la arquitectura LUT que acelera la inferencia de LLM un 3x con cuantificación dual, reduciendo la pérdida de precisión a solo 1.98%.

Regret Pre-training: nuevo método que usa información futura para mejorar modelos de lenguaje. Logra un 33.9% de precisión en 9 tareas. ¡Sin parámetros extra!
Descubre cómo implementar una app personalizada para reemplazar hojas de cálculo sin interrumpir tus operaciones. Guía con fases, pruebas piloto y soporte.

Descubre cómo las entropías de grupo y la dualidad espejo crean una familia flexible de actualizaciones de descenso espejo para optimizar modelos de ML con mayor adaptabilidad y convergencia.

La amplificación de errores temporales limita la conversión de ANN a SNN en control continuo. Conoce CRPI, una solución ligera que suprime estos errores y recupera el rendimiento.

Descubre cómo DAG-Plan usa grafos acíclicos para coordinar robots de doble brazo con un 48% más de éxito y 84% más de eficiencia.

Implementa 7 estrategias de eficiencia energética en tu negocio. Ahorra hasta un 30% en costos y mejora tu sostenibilidad.

Nuevo método de aprendizaje por refuerzo reduce error de trayectoria en UAV de ala fija en un 86.77% respecto al autopiloto clásico. Descubre cómo el filtro HJB mejora la supervisión.
FlatVPR corrige la curvatura de manifolds en modelos fundacionales, permitiendo reconstrucción lineal precisa con pocos anclajes. Mejora el VPR incluso con cambios estacionales extremos.