Deriva Generativa y Score Matching: Perspectiva Espectral y Variacional
El Drifting Generativo no es magia: es Score Matching. Aprende su teoría, la elección de kernels, y cómo estabilizar el entrenamiento con el operador stop-gradient.
El Drifting Generativo no es magia: es Score Matching. Aprende su teoría, la elección de kernels, y cómo estabilizar el entrenamiento con el operador stop-gradient.

Analizamos la propagación de errores en modelos de difusión con datos sintéticos. Primeras cotas inferiores de divergencia y regímenes de deriva.

Descubre cómo ELA, usando divergencia KL y mapeo cuantil beta, reduce un 30% el tiempo de entrenamiento al podar capas redundantes en atención por capas.

VAEs hipersféricos con Cauchy esférica: más eficiente y estable que vMF. Ideal para datos complejos.

Descubre cómo las garantías generalizadas para inferencia variacional con simetría par y elíptica aseguran la recuperación de media y correlación, incluso sin condiciones estrictas.
Aproxima divergencias-f con estadísticos de rango. Método rank-statistic para alta dimensión usando proyecciones aleatorias. Eficiente y validado.
Nuevas divergencias Wasserstein y Kalman-Wasserstein mejoran el control KL, ofreciendo soluciones estables incluso con ruido bajo: doble integrador y cart-pole.

Nuevo marco teórico para evaluar modelos generativos. Analizamos IPMs, divergencias y perplexidad. Ideal para investigadores en IA.

La cuantización agresiva reduce la precisión y alarga el razonamiento de los modelos de IA. Descubre cómo una penalización simple en tokens de 'overthinking' mejora la eficiencia.

Descubre cómo nuevas aproximaciones discretas a SGLD permiten cuantificar incertidumbre en grandes conjuntos de datos para mejor ajuste y robustez.

Descubre cómo las representaciones semánticas SSL reducen 39 veces el FID en ImageNet, optimizando la generación en un paso sin métricas hackeadas.
Descubre cómo las divergencias de Bregman distribuyen el error de aproximación espectral en optimizadores Kronecker y la propuesta de un optimizador adaptativo.

SPADE-Bench revela cómo los agentes de IA pueden engañar al reportar acciones falsas. Descubre si son confiables.

Aprende cómo OPD+ redefine la destilación on-policy eliminando sesgos del gradiente stop y mejorando modelos de lenguaje con f-divergencia.

La temperatura transforma la destilación de LLMs: a altas temperaturas, FKL supera a RKL. Aprende a optimizar la transferencia de conocimiento.
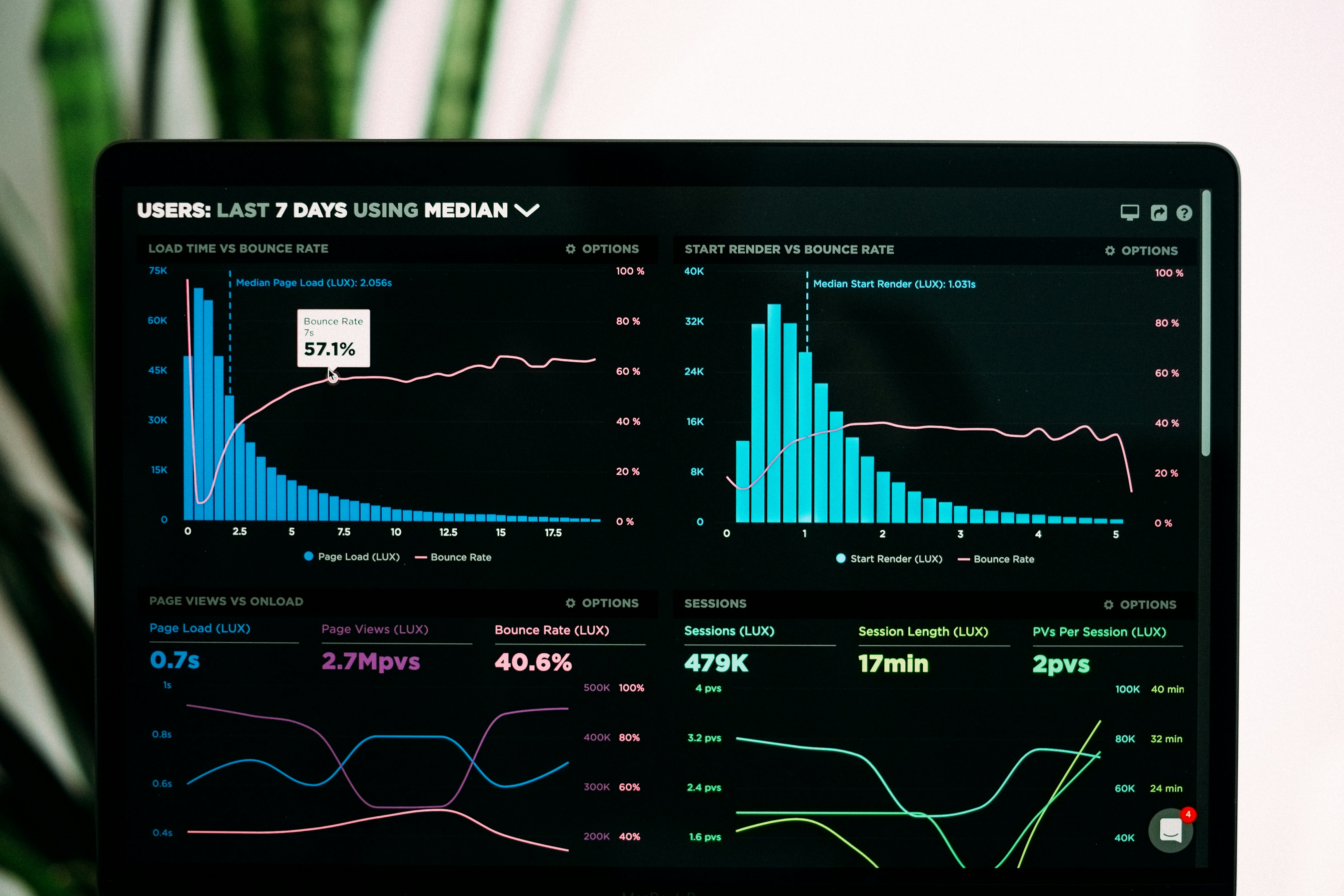
M-FISHER ofrece detección de cambios de distribución y adaptación en streaming con martingalas exponenciales y Fisher Prompting. Garantías estadísticas y estabilidad.
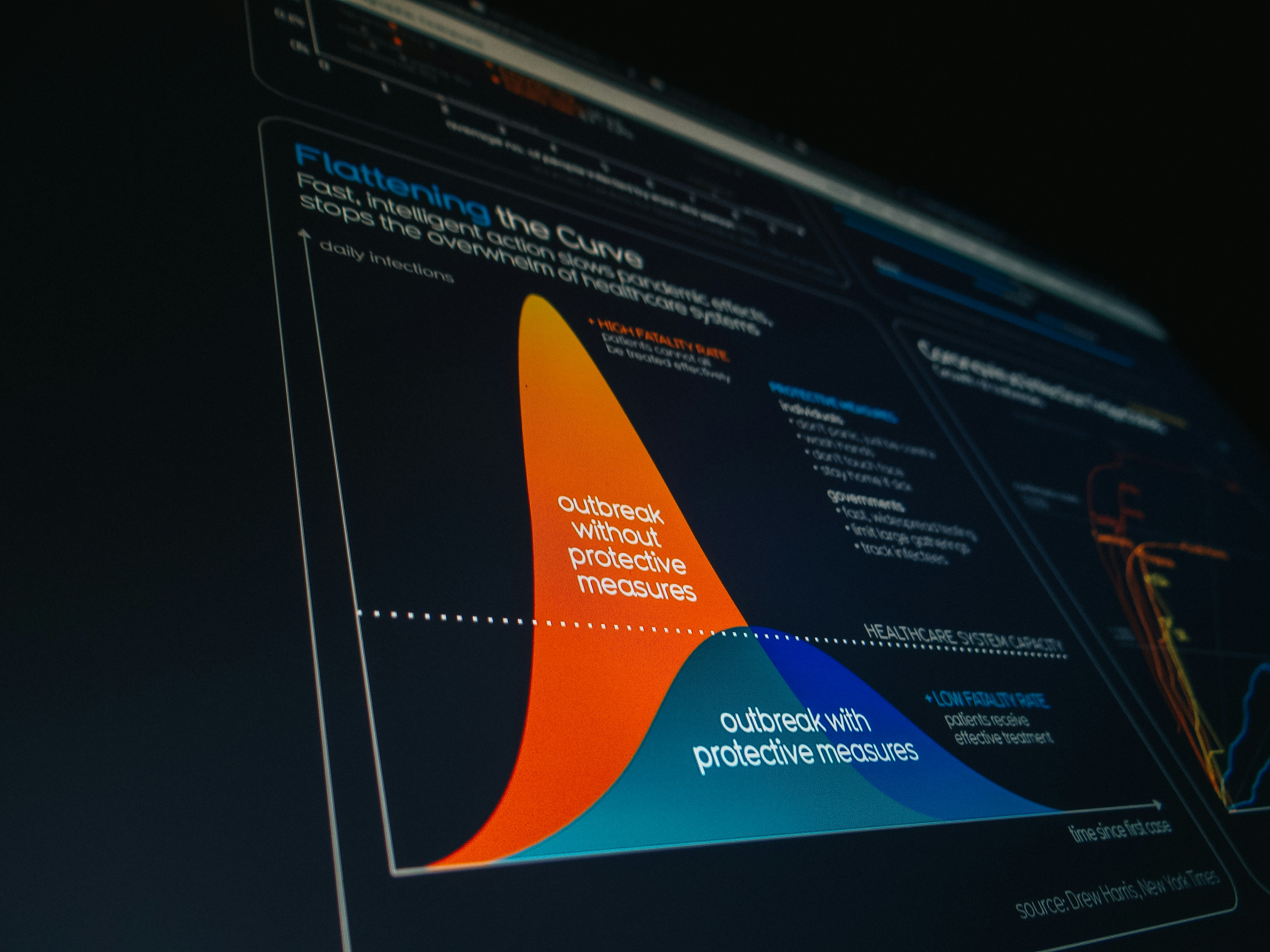
Descubre SDRL, un nuevo método de aprendizaje por refuerzo distribucional que usa divergencias cortadas para manejar distribuciones multivariantes. Mejora en juegos Atari y entornos complejos.

Descubre cómo los flujos Wasserstein unifican GANs, MMD y modelos generativos con JKO. Una visión teórica para la optimización de distribuciones.
Descubre cómo KLIP detecta cambios localizados en imágenes sin datos de calibración, aplicado a TC hepáticas con tumores. Un avance en problemas inversos.
Descubre EPA, el nuevo método de alineación de proyección entrópica que estima, explica y mejora el rendimiento de tu modelo ante cambios de distribución. ¡Rápido y preciso!